 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChain of Methodologies: Scaling Test Time Computation without Training
Jun 08, 2025Large Language Models (LLMs) often struggle with complex reasoning tasks due to insufficient in-depth insights in their training data, which are typically absent in publicly available documents. This paper introduces the Chain of Methodologies (CoM), an innovative and intuitive prompting framework that enhances structured thinking by integrating human methodological insights, enabling LLMs to tackle complex tasks with extended reasoning. CoM leverages the metacognitive abilities of advanced LLMs, activating systematic reasoning throught user-defined methodologies without explicit fine-tuning. Experiments show that CoM surpasses competitive baselines, demonstrating the potential of training-free prompting methods as robust solutions for complex reasoning tasks and bridging the gap toward human-level reasoning through human-like methodological insights.
Convergence Analysis of Asynchronous Federated Learning with Gradient Compression for Non-Convex Optimization
Apr 28, 2025



Gradient compression is an effective technique for reducing communication costs in federated learning (FL), and error feedback (EF) is usually adopted to remedy the compression errors. However, there remains a lack of systematic study on these techniques in asynchronous FL. In this paper, we fill this gap by analyzing the convergence behaviors of FL under different frameworks. We firstly consider a basic asynchronous FL framework AsynFL, and provide an improved convergence analysis that relies on fewer assumptions and yields a superior convergence rate than prior studies. Then, we consider a variant framework with gradient compression, AsynFLC. We show sufficient conditions for its convergence to the optimum, indicating the interaction between asynchronous delay and compression rate. Our analysis also demonstrates that asynchronous delay amplifies the variance caused by compression, thereby hindering convergence, and such an impact is exacerbated by high data heterogeneity. Furthermore, we study the convergence of AsynFLC-EF, the framework that further integrates EF. We prove that EF can effectively reduce the variance of gradient estimation despite asynchronous delay, which enables AsynFLC-EF to match the convergence rate of AsynFL. We also show that the impact of asynchronous delay on EF is limited to slowing down the higher-order convergence term. Experimental results substantiate our analytical findings very well.
Cool-Fusion: Fuse Large Language Models without Training
Jul 29, 2024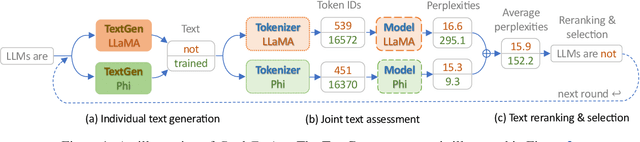

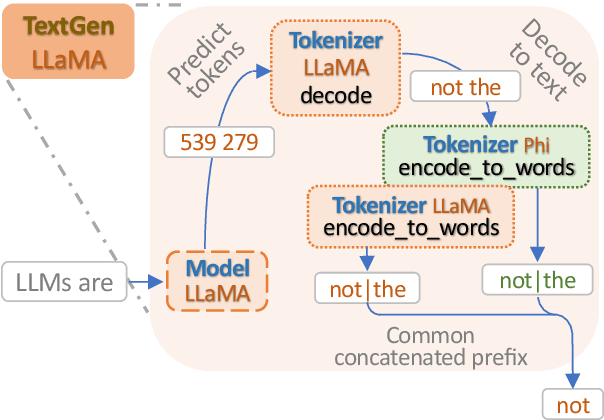

We focus on the problem of fusing two or more heterogeneous large language models (LLMs) to facilitate their complementary strengths. One of the challenges on model fusion is high computational load, i.e. to fine-tune or to align vocabularies via combinatorial optimization. To this end, we propose \emph{Cool-Fusion}, a simple yet effective approach that fuses the knowledge of heterogeneous source LLMs to leverage their complementary strengths. \emph{Cool-Fusion} is the first method that does not require any type of training like the ensemble approaches. But unlike ensemble methods, it is applicable to any set of source LLMs that have different vocabularies. The basic idea is to have each source LLM individually generate tokens until the tokens can be decoded into a text segment that ends at word boundaries common to all source LLMs. Then, the source LLMs jointly rerank the generated text segment and select the best one, which is the fused text generation in one step. Extensive experiments are conducted across a variety of benchmark datasets. On \emph{GSM8K}, \emph{Cool-Fusion} increases accuracy from three strong source LLMs by a significant 8\%-17.8\%.
VersiCode: Towards Version-controllable Code Generation
Jun 11, 2024

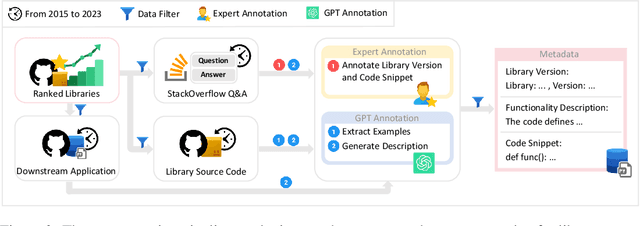

Significant research has focused on improving the performance of large language model on code-related tasks due to their practical importance. Although performance is typically evaluated using public benchmark datasets, the existing datasets do not account for the concept of \emph{version}, which is crucial in professional software development. In this paper, we introduce VersiCode, the first comprehensive dataset designed to assess the ability of large language models to generate verifiable code for specific library versions. VersiCode encompasses 300 libraries across more than 2,000 versions spanning 9 years. We design two dedicated evaluation tasks: version-specific code completion (VSCC) and version-aware code editing (VACE). Comprehensive experiments are conducted to benchmark the performance of LLMs, revealing the challenging nature of these tasks and VersiCode, that even state-of-the-art LLMs struggle to generate version-correct code. This dataset, together with the proposed tasks, sheds light on LLMs' capabilities and limitations in handling version-specific code generation, and opens up an important new area of research for further investigation. The resources can be found at https://github.com/wutong8023/VersiCode.
FedCME: Client Matching and Classifier Exchanging to Handle Data Heterogeneity in Federated Learning
Jul 17, 2023



Data heterogeneity across clients is one of the key challenges in Federated Learning (FL), which may slow down the global model convergence and even weaken global model performance. Most existing approaches tackle the heterogeneity by constraining local model updates through reference to global information provided by the server. This can alleviate the performance degradation on the aggregated global model. Different from existing methods, we focus the information exchange between clients, which could also enhance the effectiveness of local training and lead to generate a high-performance global model. Concretely, we propose a novel FL framework named FedCME by client matching and classifier exchanging. In FedCME, clients with large differences in data distribution will be matched in pairs, and then the corresponding pair of clients will exchange their classifiers at the stage of local training in an intermediate moment. Since the local data determines the local model training direction, our method can correct update direction of classifiers and effectively alleviate local update divergence. Besides, we propose feature alignment to enhance the training of the feature extractor. Experimental results demonstrate that FedCME performs better than FedAvg, FedProx, MOON and FedRS on popular federated learning benchmarks including FMNIST and CIFAR10, in the case where data are heterogeneous.
PFL-MoE: Personalized Federated Learning Based on Mixture of Experts
Dec 31, 2020



Federated learning (FL) is an emerging distributed machine learning paradigm that avoids data sharing among training nodes so as to protect data privacy. Under coordination of the FL server, each client conducts model training using its own computing resource and private data set. The global model can be created by aggregating the training results of clients. To cope with highly non-IID data distributions, personalized federated learning (PFL) has been proposed to improve overall performance by allowing each client to learn a personalized model. However, one major drawback of a personalized model is the loss of generalization. To achieve model personalization while maintaining generalization, in this paper, we propose a new approach, named PFL-MoE, which mixes outputs of the personalized model and global model via the MoE architecture. PFL-MoE is a generic approach and can be instantiated by integrating existing PFL algorithms. Particularly, we propose the PFL-MF algorithm which is an instance of PFL-MoE based on the freeze-base PFL algorithm. We further improve PFL-MF by enhancing the decision-making ability of MoE gating network and propose a variant algorithm PFL-MFE. We demonstrate the effectiveness of PFL-MoE by training the LeNet-5 and VGG-16 models on the Fashion-MNIST and CIFAR-10 datasets with non-IID partitions.