 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVersiCode: Towards Version-controllable Code Generation
Paper and Code


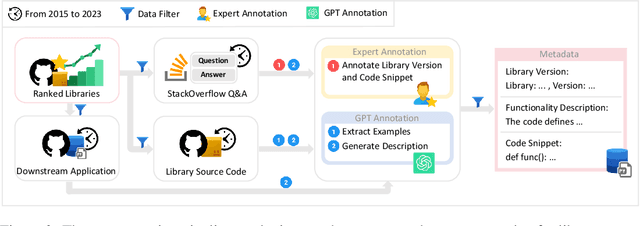

Significant research has focused on improving the performance of large language model on code-related tasks due to their practical importance. Although performance is typically evaluated using public benchmark datasets, the existing datasets do not account for the concept of \emph{version}, which is crucial in professional software development. In this paper, we introduce VersiCode, the first comprehensive dataset designed to assess the ability of large language models to generate verifiable code for specific library versions. VersiCode encompasses 300 libraries across more than 2,000 versions spanning 9 years. We design two dedicated evaluation tasks: version-specific code completion (VSCC) and version-aware code editing (VACE). Comprehensive experiments are conducted to benchmark the performance of LLMs, revealing the challenging nature of these tasks and VersiCode, that even state-of-the-art LLMs struggle to generate version-correct code. This dataset, together with the proposed tasks, sheds light on LLMs' capabilities and limitations in handling version-specific code generation, and opens up an important new area of research for further investigation. The resources can be found at https://github.com/wutong8023/VersiCode.