 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Iteration-Free Fixed-Point Estimator for Diffusion Inversion
Dec 09, 2025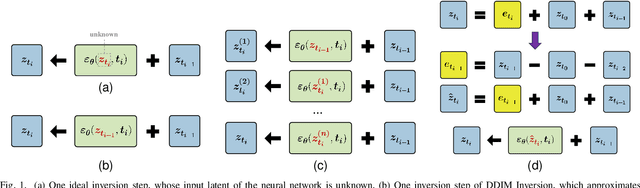



Diffusion inversion aims to recover the initial noise corresponding to a given image such that this noise can reconstruct the original image through the denoising diffusion process. The key component of diffusion inversion is to minimize errors at each inversion step, thereby mitigating cumulative inaccuracies. Recently, fixed-point iteration has emerged as a widely adopted approach to minimize reconstruction errors at each inversion step. However, it suffers from high computational costs due to its iterative nature and the complexity of hyperparameter selection. To address these issues, we propose an iteration-free fixed-point estimator for diffusion inversion. First, we derive an explicit expression of the fixed point from an ideal inversion step. Unfortunately, it inherently contains an unknown data prediction error. Building upon this, we introduce the error approximation, which uses the calculable error from the previous inversion step to approximate the unknown error at the current inversion step. This yields a calculable, approximate expression for the fixed point, which is an unbiased estimator characterized by low variance, as shown by our theoretical analysis. We evaluate reconstruction performance on two text-image datasets, NOCAPS and MS-COCO. Compared to DDIM inversion and other inversion methods based on the fixed-point iteration, our method achieves consistent and superior performance in reconstruction tasks without additional iterations or training.
Thinking Before You Speak: A Proactive Test-time Scaling Approach
Aug 27, 2025
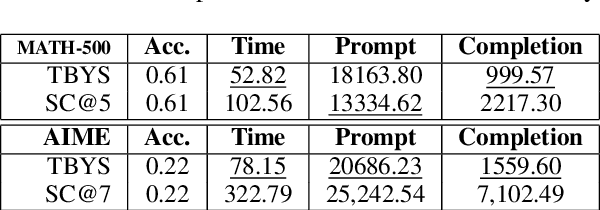
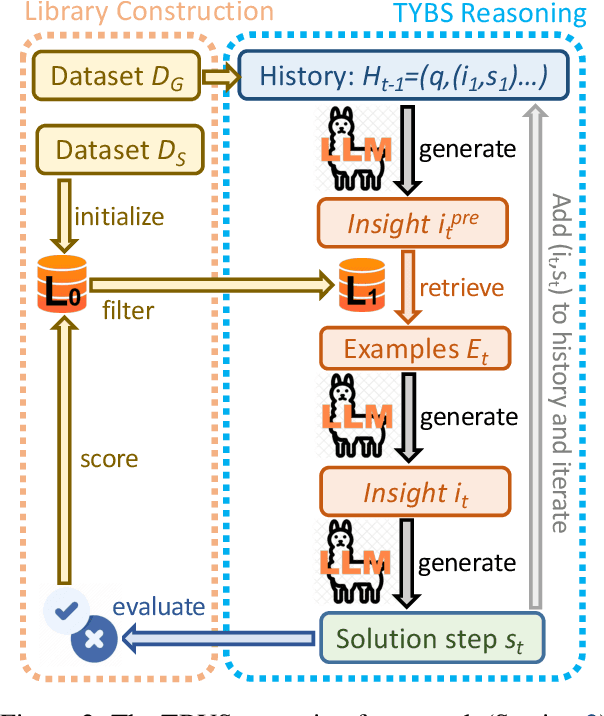
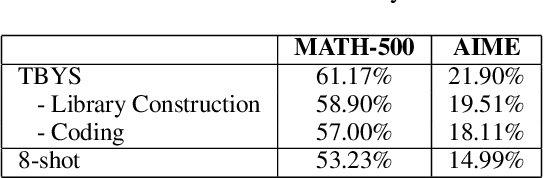
Large Language Models (LLMs) often exhibit deficiencies with complex reasoning tasks, such as maths, which we attribute to the discrepancy between human reasoning patterns and those presented in the LLMs' training data. When dealing with complex problems, humans tend to think carefully before expressing solutions. However, they often do not articulate their inner thoughts, including their intentions and chosen methodologies. Consequently, critical insights essential for bridging reasoning steps may be absent in training data collected from human sources. To bridge this gap, we proposes inserting \emph{insight}s between consecutive reasoning steps, which review the status and initiate the next reasoning steps. Unlike prior prompting strategies that rely on a single or a workflow of static prompts to facilitate reasoning, \emph{insight}s are \emph{proactively} generated to guide reasoning processes. We implement our idea as a reasoning framework, named \emph{Thinking Before You Speak} (TBYS), and design a pipeline for automatically collecting and filtering in-context examples for the generation of \emph{insight}s, which alleviates human labeling efforts and fine-tuning overheads. Experiments on challenging mathematical datasets verify the effectiveness of TBYS. Project website: https://gitee.com/jswrt/TBYS
Enhanced Multi-Tuple Extraction for Alloys: Integrating Pointer Networks and Augmented Attention
Mar 10, 2025Extracting high-quality structured information from scientific literature is crucial for advancing material design through data-driven methods. Despite the considerable research in natural language processing for dataset extraction, effective approaches for multi-tuple extraction in scientific literature remain scarce due to the complex interrelations of tuples and contextual ambiguities. In the study, we illustrate the multi-tuple extraction of mechanical properties from multi-principal-element alloys and presents a novel framework that combines an entity extraction model based on MatSciBERT with pointer networks and an allocation model utilizing inter- and intra-entity attention. Our rigorous experiments on tuple extraction demonstrate impressive F1 scores of 0.963, 0.947, 0.848, and 0.753 across datasets with 1, 2, 3, and 4 tuples, confirming the effectiveness of the model. Furthermore, an F1 score of 0.854 was achieved on a randomly curated dataset. These results highlight the model's capacity to deliver precise and structured information, offering a robust alternative to large language models and equipping researchers with essential data for fostering data-driven innovations.
ATI-CTLO:Adaptive Temporal Interval-based Continuous-Time LiDAR-Only Odometry
Jul 30, 2024
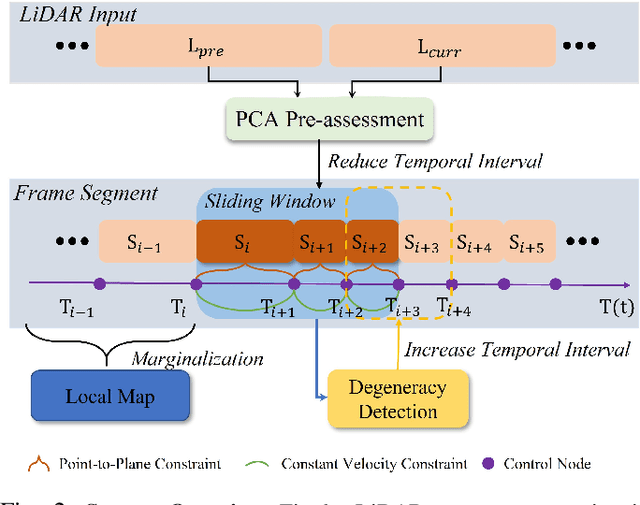
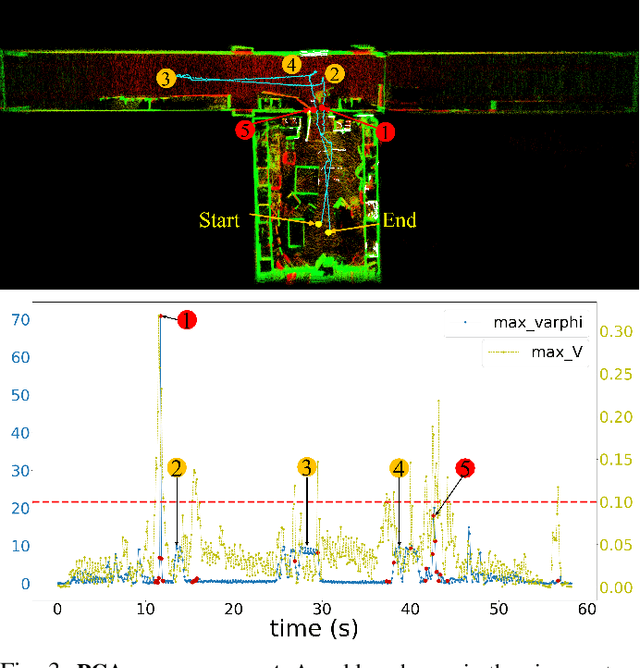
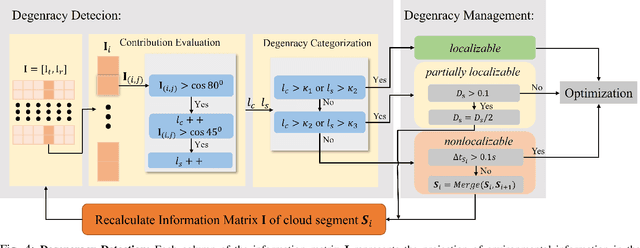
The motion distortion in LiDAR scans caused by aggressive robot motion and varying terrain features significantly impacts the positioning and mapping performance of 3D LiDAR odometry. Existing distortion correction solutions often struggle to balance computational complexity and accuracy. In this work, we propose an Adaptive Temporal Interval-based Continuous-Time LiDAR-only Odometry, utilizing straightforward and efficient linear interpolation. Our method flexibly adjusts the temporal intervals between control nodes according to the dynamics of motion and environmental characteristics. This adaptability enhances performance across various motion states and improves robustness in challenging, feature-sparse environments. We validate the effectiveness of our method on multiple datasets across different platforms, achieving accuracy comparable to state-of-the-art LiDAR-only odometry methods. Notably, in scenarios involving aggressive motion and sparse features, our method outperforms existing solutions.
Cool-Fusion: Fuse Large Language Models without Training
Jul 29, 2024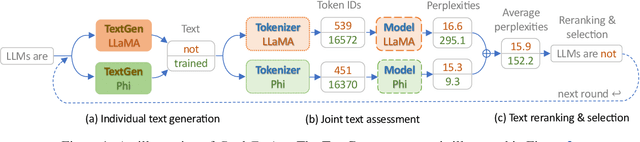

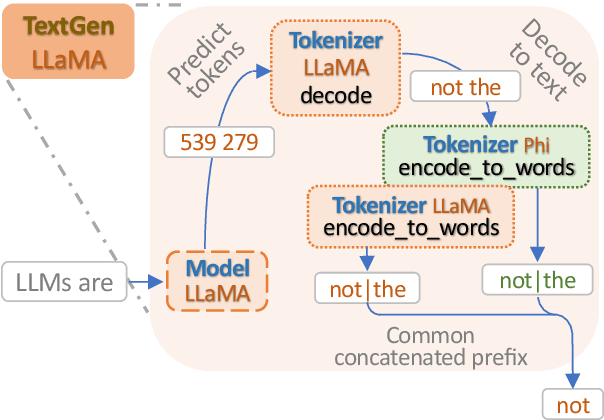

We focus on the problem of fusing two or more heterogeneous large language models (LLMs) to facilitate their complementary strengths. One of the challenges on model fusion is high computational load, i.e. to fine-tune or to align vocabularies via combinatorial optimization. To this end, we propose \emph{Cool-Fusion}, a simple yet effective approach that fuses the knowledge of heterogeneous source LLMs to leverage their complementary strengths. \emph{Cool-Fusion} is the first method that does not require any type of training like the ensemble approaches. But unlike ensemble methods, it is applicable to any set of source LLMs that have different vocabularies. The basic idea is to have each source LLM individually generate tokens until the tokens can be decoded into a text segment that ends at word boundaries common to all source LLMs. Then, the source LLMs jointly rerank the generated text segment and select the best one, which is the fused text generation in one step. Extensive experiments are conducted across a variety of benchmark datasets. On \emph{GSM8K}, \emph{Cool-Fusion} increases accuracy from three strong source LLMs by a significant 8\%-17.8\%.
OTO Planner: An Efficient Only Travelling Once Exploration Planner for Complex and Unknown Environments
Jun 11, 2024



Autonomous exploration in complex and cluttered environments is essential for various applications. However, there are many challenges due to the lack of global heuristic information. Existing exploration methods suffer from the repeated paths and considerable computational resource requirement in large-scale environments. To address the above issues, this letter proposes an efficient exploration planner that reduces repeated paths in complex environments, hence it is called "Only Travelling Once Planner". OTO Planner includes fast frontier updating, viewpoint evaluation and viewpoint refinement. A selective frontier updating mechanism is designed, saving a large amount of computational resources. In addition, a novel viewpoint evaluation system is devised to reduce the repeated paths utilizing the enclosed sub-region detection. Besides, a viewpoint refinement approach is raised to concentrate the redundant viewpoints, leading to smoother paths. We conduct extensive simulation and real-world experiments to validate the proposed method. Compared to the state-of-the-art approach, the proposed method reduces the exploration time and movement distance by 10%-20% and improves the speed of frontier detection by 6-9 times.
The Future of Cognitive Strategy-enhanced Persuasive Dialogue Agents: New Perspectives and Trends
Feb 07, 2024
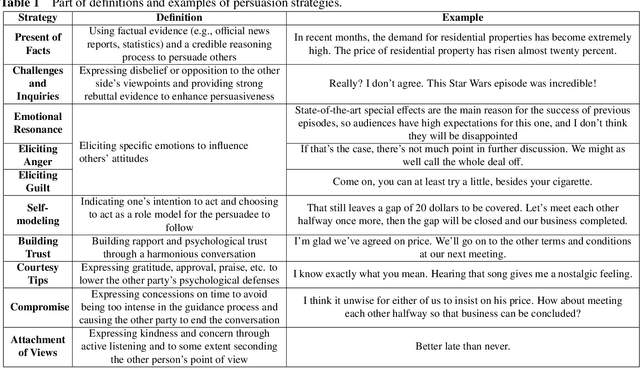

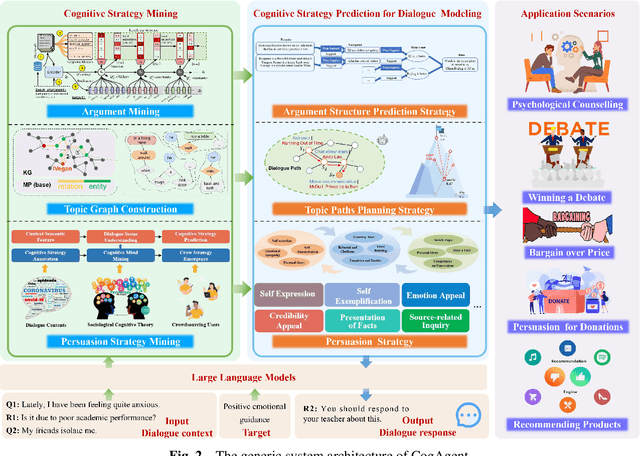
Persuasion, as one of the crucial abilities in human communication, has garnered extensive attention from researchers within the field of intelligent dialogue systems. We humans tend to persuade others to change their viewpoints, attitudes or behaviors through conversations in various scenarios (e.g., persuasion for social good, arguing in online platforms). Developing dialogue agents that can persuade others to accept certain standpoints is essential to achieving truly intelligent and anthropomorphic dialogue system. Benefiting from the substantial progress of Large Language Models (LLMs), dialogue agents have acquired an exceptional capability in context understanding and response generation. However, as a typical and complicated cognitive psychological system, persuasive dialogue agents also require knowledge from the domain of cognitive psychology to attain a level of human-like persuasion. Consequently, the cognitive strategy-enhanced persuasive dialogue agent (defined as CogAgent), which incorporates cognitive strategies to achieve persuasive targets through conversation, has become a predominant research paradigm. To depict the research trends of CogAgent, in this paper, we first present several fundamental cognitive psychology theories and give the formalized definition of three typical cognitive strategies, including the persuasion strategy, the topic path planning strategy, and the argument structure prediction strategy. Then we propose a new system architecture by incorporating the formalized definition to lay the foundation of CogAgent. Representative works are detailed and investigated according to the combined cognitive strategy, followed by the summary of authoritative benchmarks and evaluation metrics. Finally, we summarize our insights on open issues and future directions of CogAgent for upcoming researchers.
Improving Entropy-Based Test-Time Adaptation from a Clustering View
Nov 18, 2023



Domain shift is a common problem in the realistic world, where training data and test data follow different data distributions. To deal with this problem, fully test-time adaptation (TTA) leverages the unlabeled data encountered during test time to adapt the model. In particular, Entropy-Based TTA (EBTTA) methods, which minimize the prediction's entropy on test samples, have shown great success. In this paper, we introduce a new perspective on the EBTTA, which interprets these methods from a view of clustering. It is an iterative algorithm: 1) in the assignment step, the forward process of the EBTTA models is the assignment of labels for these test samples, and 2) in the updating step, the backward process is the update of the model via the assigned samples. Based on the interpretation, we can gain a deeper understanding of EBTTA, where we show that the entropy loss would further increase the largest probability. Accordingly, we offer an alternative explanation for why existing EBTTA methods are sensitive to initial assignments, outliers, and batch size. This observation can guide us to put forward the improvement of EBTTA. We propose robust label assignment, weight adjustment, and gradient accumulation to alleviate the above problems. Experimental results demonstrate that our method can achieve consistent improvements on various datasets. Code is provided in the supplementary material.
Camera-LiDAR Fusion with Latent Contact for Place Recognition in Challenging Cross-Scenes
Oct 16, 2023



Although significant progress has been made, achieving place recognition in environments with perspective changes, seasonal variations, and scene transformations remains challenging. Relying solely on perception information from a single sensor is insufficient to address these issues. Recognizing the complementarity between cameras and LiDAR, multi-modal fusion methods have attracted attention. To address the information waste in existing multi-modal fusion works, this paper introduces a novel three-channel place descriptor, which consists of a cascade of image, point cloud, and fusion branches. Specifically, the fusion-based branch employs a dual-stage pipeline, leveraging the correlation between the two modalities with latent contacts, thereby facilitating information interaction and fusion. Extensive experiments on the KITTI, NCLT, USVInland, and the campus dataset demonstrate that the proposed place descriptor stands as the state-of-the-art approach, confirming its robustness and generality in challenging scenarios.
Toward Understanding Why Adam Converges Faster Than SGD for Transformers
May 31, 2023



While stochastic gradient descent (SGD) is still the most popular optimization algorithm in deep learning, adaptive algorithms such as Adam have established empirical advantages over SGD in some deep learning applications such as training transformers. However, it remains a question that why Adam converges significantly faster than SGD in these scenarios. In this paper, we propose one explanation of why Adam converges faster than SGD using a new concept directional sharpness. We argue that the performance of optimization algorithms is closely related to the directional sharpness of the update steps, and show SGD has much worse directional sharpness compared to adaptive algorithms. We further observe that only a small fraction of the coordinates causes the bad sharpness and slow convergence of SGD, and propose to use coordinate-wise clipping as a solution to SGD and other optimization algorithms. We demonstrate the effect of coordinate-wise clipping on sharpness reduction and speeding up the convergence of optimization algorithms under various settings. We show that coordinate-wise clipping improves the local loss reduction when only a small fraction of the coordinates has bad sharpness. We conclude that the sharpness reduction effect of adaptive coordinate-wise scaling is the reason for Adam's success in practice and suggest the use of coordinate-wise clipping as a universal technique to speed up deep learning optimization.