 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeATI-CTLO:Adaptive Temporal Interval-based Continuous-Time LiDAR-Only Odometry
Jul 30, 2024
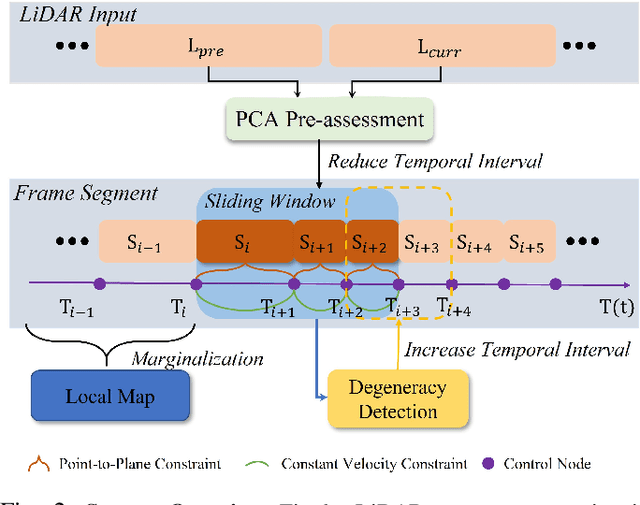
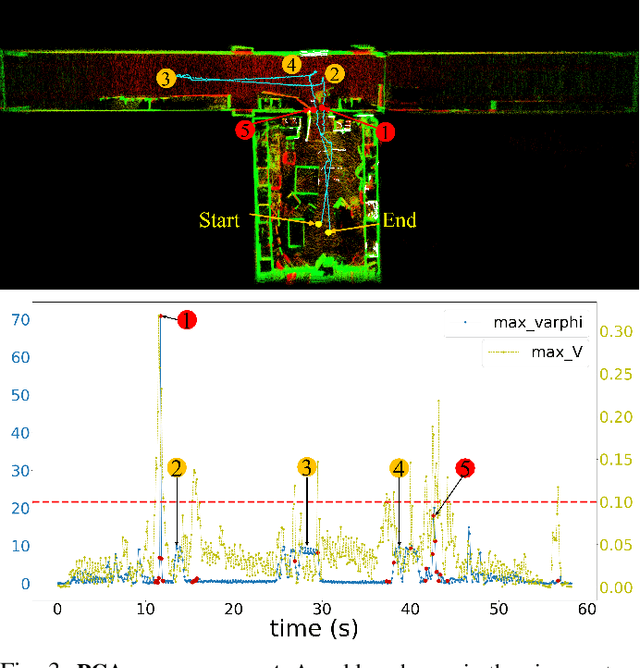
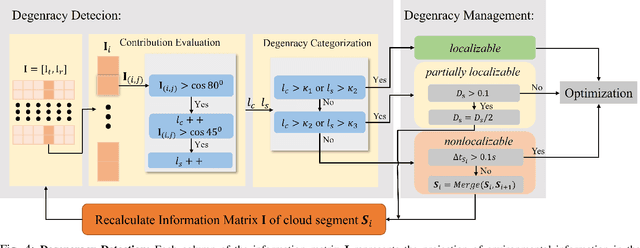
The motion distortion in LiDAR scans caused by aggressive robot motion and varying terrain features significantly impacts the positioning and mapping performance of 3D LiDAR odometry. Existing distortion correction solutions often struggle to balance computational complexity and accuracy. In this work, we propose an Adaptive Temporal Interval-based Continuous-Time LiDAR-only Odometry, utilizing straightforward and efficient linear interpolation. Our method flexibly adjusts the temporal intervals between control nodes according to the dynamics of motion and environmental characteristics. This adaptability enhances performance across various motion states and improves robustness in challenging, feature-sparse environments. We validate the effectiveness of our method on multiple datasets across different platforms, achieving accuracy comparable to state-of-the-art LiDAR-only odometry methods. Notably, in scenarios involving aggressive motion and sparse features, our method outperforms existing solutions.
AFSD-Physics: Exploring the governing equations of temperature evolution during additive friction stir deposition by a human-AI teaming approach
Jan 29, 2024



This paper presents a modeling effort to explore the underlying physics of temperature evolution during additive friction stir deposition (AFSD) by a human-AI teaming approach. AFSD is an emerging solid-state additive manufacturing technology that deposits materials without melting. However, both process modeling and modeling of the AFSD tool are at an early stage. In this paper, a human-AI teaming approach is proposed to combine models based on first principles with AI. The resulting human-informed machine learning method, denoted as AFSD-Physics, can effectively learn the governing equations of temperature evolution at the tool and the build from in-process measurements. Experiments are designed and conducted to collect in-process measurements for the deposition of aluminum 7075 with a total of 30 layers. The acquired governing equations are physically interpretable models with low computational cost and high accuracy. Model predictions show good agreement with the measurements. Experimental validation with new process parameters demonstrates the model's generalizability and potential for use in tool temperature control and process optimization.
A Physics-informed Machine Learning-based Control Method for Nonlinear Dynamic Systems with Highly Noisy Measurements
Nov 12, 2023



This study presents a physics-informed machine learning-based control method for nonlinear dynamic systems with highly noisy measurements. Existing data-driven control methods that use machine learning for system identification cannot effectively cope with highly noisy measurements, resulting in unstable control performance. To address this challenge, the present study extends current physics-informed machine learning capabilities for modeling nonlinear dynamics with control and integrates them into a model predictive control framework. To demonstrate the capability of the proposed method we test and validate with two noisy nonlinear dynamic systems: the chaotic Lorenz 3 system, and turning machine tool. Analysis of the results illustrate that the proposed method outperforms state-of-the-art benchmarks as measured by both modeling accuracy and control performance for nonlinear dynamic systems under high-noise conditions.
Camera-LiDAR Fusion with Latent Contact for Place Recognition in Challenging Cross-Scenes
Oct 16, 2023



Although significant progress has been made, achieving place recognition in environments with perspective changes, seasonal variations, and scene transformations remains challenging. Relying solely on perception information from a single sensor is insufficient to address these issues. Recognizing the complementarity between cameras and LiDAR, multi-modal fusion methods have attracted attention. To address the information waste in existing multi-modal fusion works, this paper introduces a novel three-channel place descriptor, which consists of a cascade of image, point cloud, and fusion branches. Specifically, the fusion-based branch employs a dual-stage pipeline, leveraging the correlation between the two modalities with latent contacts, thereby facilitating information interaction and fusion. Extensive experiments on the KITTI, NCLT, USVInland, and the campus dataset demonstrate that the proposed place descriptor stands as the state-of-the-art approach, confirming its robustness and generality in challenging scenarios.
Psy-LLM: Scaling up Global Mental Health Psychological Services with AI-based Large Language Models
Jul 22, 2023The demand for psychological counseling has grown significantly in recent years, particularly with the global outbreak of COVID-19, which has heightened the need for timely and professional mental health support. Online psychological counseling has emerged as the predominant mode of providing services in response to this demand. In this study, we propose the Psy-LLM framework, an AI-based system leveraging Large Language Models (LLMs) for question-answering in online psychological consultation. Our framework combines pre-trained LLMs with real-world professional Q&A from psychologists and extensively crawled psychological articles. The Psy-LLM framework serves as a front-end tool for healthcare professionals, allowing them to provide immediate responses and mindfulness activities to alleviate patient stress. Additionally, it functions as a screening tool to identify urgent cases requiring further assistance. We evaluated the framework using intrinsic metrics, such as perplexity, and extrinsic evaluation metrics, with human participant assessments of response helpfulness, fluency, relevance, and logic. The results demonstrate the effectiveness of the Psy-LLM framework in generating coherent and relevant answers to psychological questions. This article concludes by discussing the potential of large language models to enhance mental health support through AI technologies in online psychological consultation.
MotionBEV: Attention-Aware Online LiDAR Moving Object Segmentation with Bird's Eye View based Appearance and Motion Features
May 12, 2023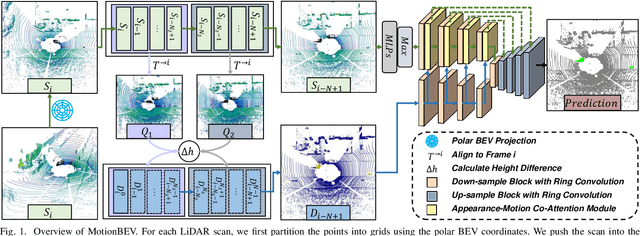

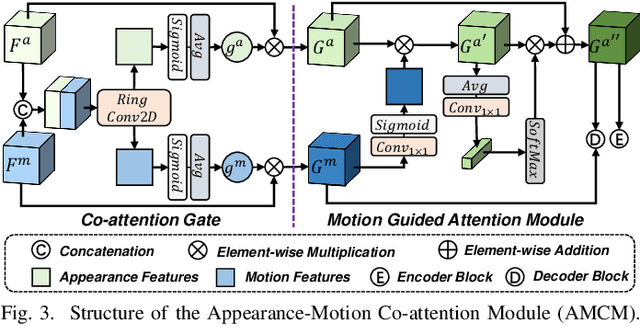
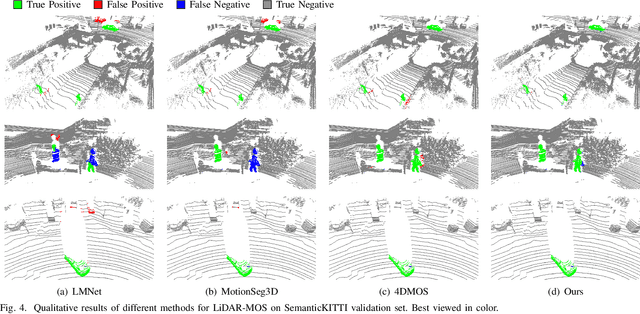
Identifying moving objects is an essential capability for autonomous systems, as it provides critical information for pose estimation, navigation, collision avoidance and static map construction. In this paper, we present MotionBEV, a fast and accurate framework for LiDAR moving object segmentation, which segments moving objects with appearance and motion features in bird's eye view (BEV) domain. Our approach converts 3D LiDAR scans into 2D polar BEV representation to achieve real-time performance. Specifically, we learn appearance features with a simplified PointNet, and compute motion features through the height differences of consecutive frames of point clouds projected onto vertical columns in the polar BEV coordinate system. We employ a dual-branch network bridged by the Appearance-Motion Co-attention Module (AMCM) to adaptively fuse the spatio-temporal information from appearance and motion features. Our approach achieves state-of-the-art performance on the SemanticKITTI-MOS benchmark, with an average inference time of 23ms on an RTX 3090 GPU. Furthermore, to demonstrate the practical effectiveness of our method, we provide a LiDAR-MOS dataset recorded by a solid-state LiDAR, which features non-repetitive scanning patterns and small field of view.
Literature review on vulnerability detection using NLP technology
Apr 23, 2021
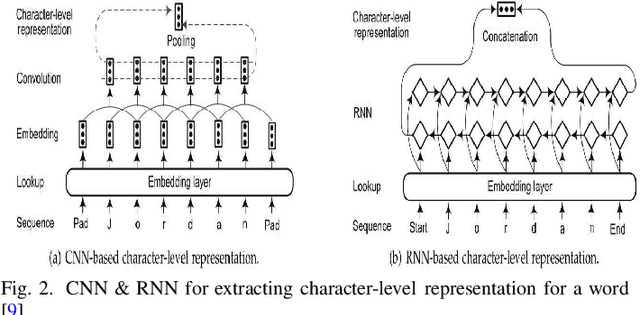
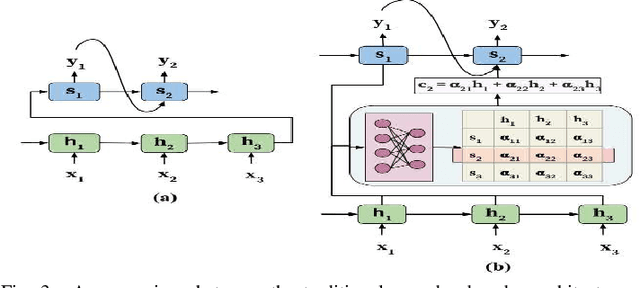

Vulnerability detection has always been the most important task in the field of software security. With the development of technology, in the face of massive source code, automated analysis and detection of vulnerabilities has become a current research hotspot. For special text files such as source code, using some of the hottest NLP technologies to build models and realize the automatic analysis and detection of source code has become one of the most anticipated studies in the field of vulnerability detection. This article does a brief survey of some recent new documents and technologies, such as CodeBERT, and summarizes the previous technologies.