 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrasping by parallel shape matching
Dec 11, 2024



Grasping is essential in robotic manipulation, yet challenging due to object and gripper diversity and real-world complexities. Traditional analytic approaches often have long optimization times, while data-driven methods struggle with unseen objects. This paper formulates the problem as a rigid shape matching between gripper and object, which optimizes with Annealed Stein Iterative Closest Point (AS-ICP) and leverages GPU-based parallelization. By incorporating the gripper's tool center point and the object's center of mass into the cost function and using a signed distance field of the gripper for collision checking, our method achieves robust grasps with low computational time. Experiments with the Kinova KG3 gripper show an 87.3% success rate and 0.926 s computation time across various objects and settings, highlighting its potential for real-world applications.
Interpretable Medical Imagery Diagnosis with Self-Attentive Transformers: A Review of Explainable AI for Health Care
Sep 01, 2023Recent advancements in artificial intelligence (AI) have facilitated its widespread adoption in primary medical services, addressing the demand-supply imbalance in healthcare. Vision Transformers (ViT) have emerged as state-of-the-art computer vision models, benefiting from self-attention modules. However, compared to traditional machine-learning approaches, deep-learning models are complex and are often treated as a "black box" that can cause uncertainty regarding how they operate. Explainable Artificial Intelligence (XAI) refers to methods that explain and interpret machine learning models' inner workings and how they come to decisions, which is especially important in the medical domain to guide the healthcare decision-making process. This review summarises recent ViT advancements and interpretative approaches to understanding the decision-making process of ViT, enabling transparency in medical diagnosis applications.
Path Signatures for Diversity in Probabilistic Trajectory Optimisation
Aug 08, 2023



Motion planning can be cast as a trajectory optimisation problem where a cost is minimised as a function of the trajectory being generated. In complex environments with several obstacles and complicated geometry, this optimisation problem is usually difficult to solve and prone to local minima. However, recent advancements in computing hardware allow for parallel trajectory optimisation where multiple solutions are obtained simultaneously, each initialised from a different starting point. Unfortunately, without a strategy preventing two solutions to collapse on each other, naive parallel optimisation can suffer from mode collapse diminishing the efficiency of the approach and the likelihood of finding a global solution. In this paper we leverage on recent advances in the theory of rough paths to devise an algorithm for parallel trajectory optimisation that promotes diversity over the range of solutions, therefore avoiding mode collapses and achieving better global properties. Our approach builds on path signatures and Hilbert space representations of trajectories, and connects parallel variational inference for trajectory estimation with diversity promoting kernels. We empirically demonstrate that this strategy achieves lower average costs than competing alternatives on a range of problems, from 2D navigation to robotic manipulators operating in cluttered environments.
Psy-LLM: Scaling up Global Mental Health Psychological Services with AI-based Large Language Models
Jul 22, 2023The demand for psychological counseling has grown significantly in recent years, particularly with the global outbreak of COVID-19, which has heightened the need for timely and professional mental health support. Online psychological counseling has emerged as the predominant mode of providing services in response to this demand. In this study, we propose the Psy-LLM framework, an AI-based system leveraging Large Language Models (LLMs) for question-answering in online psychological consultation. Our framework combines pre-trained LLMs with real-world professional Q&A from psychologists and extensively crawled psychological articles. The Psy-LLM framework serves as a front-end tool for healthcare professionals, allowing them to provide immediate responses and mindfulness activities to alleviate patient stress. Additionally, it functions as a screening tool to identify urgent cases requiring further assistance. We evaluated the framework using intrinsic metrics, such as perplexity, and extrinsic evaluation metrics, with human participant assessments of response helpfulness, fluency, relevance, and logic. The results demonstrate the effectiveness of the Psy-LLM framework in generating coherent and relevant answers to psychological questions. This article concludes by discussing the potential of large language models to enhance mental health support through AI technologies in online psychological consultation.
Ensemble Learning based Anomaly Detection for IoT Cybersecurity via Bayesian Hyperparameters Sensitivity Analysis
Jul 20, 2023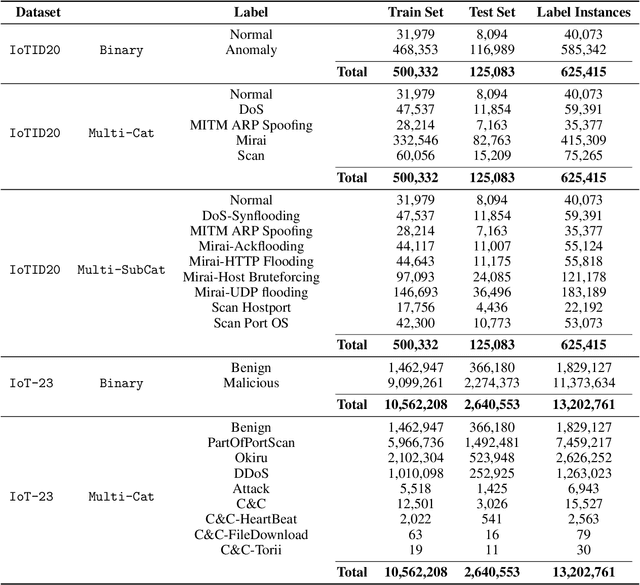
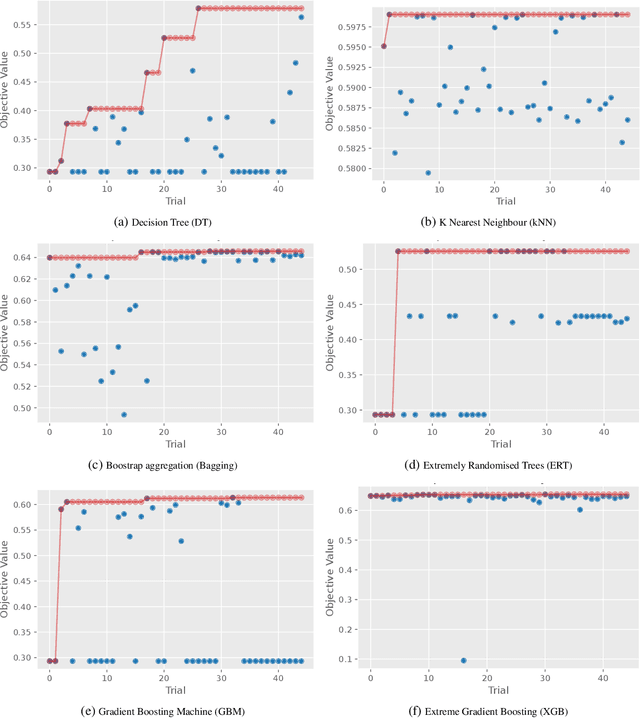
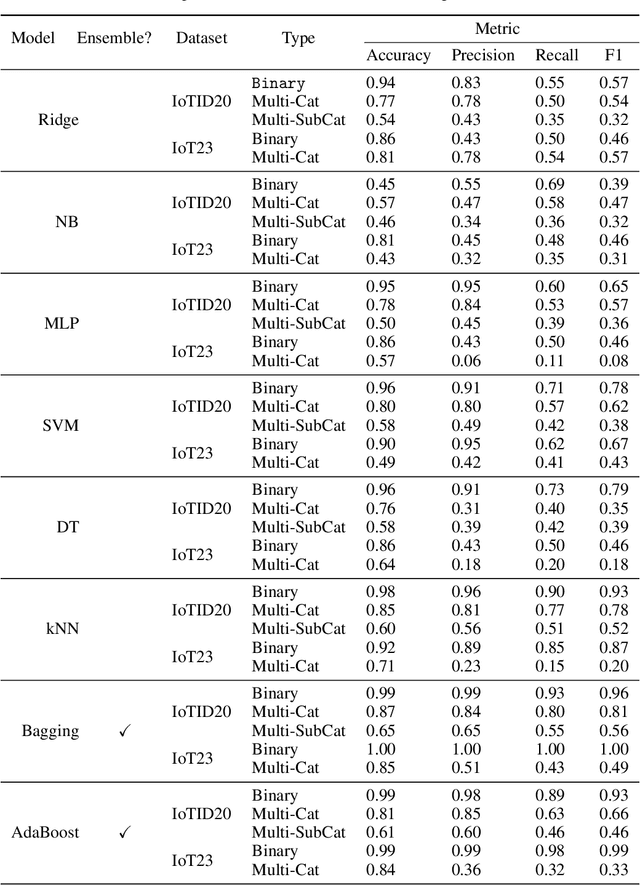
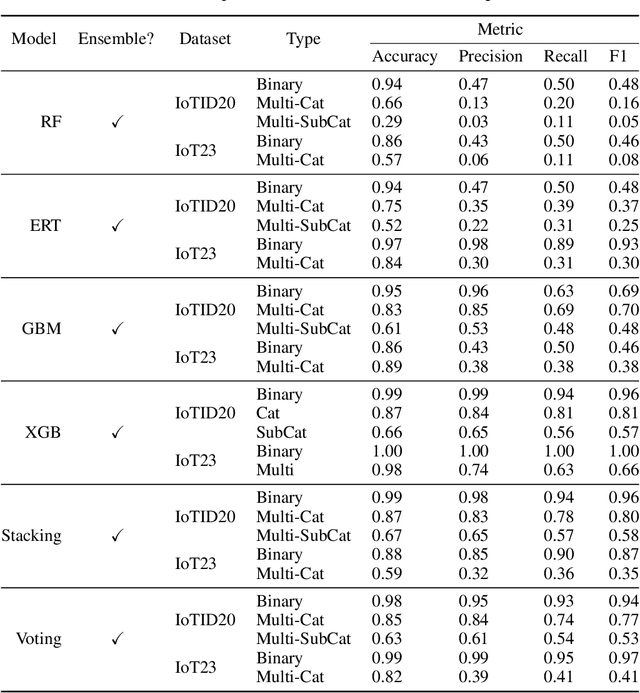
The Internet of Things (IoT) integrates more than billions of intelligent devices over the globe with the capability of communicating with other connected devices with little to no human intervention. IoT enables data aggregation and analysis on a large scale to improve life quality in many domains. In particular, data collected by IoT contain a tremendous amount of information for anomaly detection. The heterogeneous nature of IoT is both a challenge and an opportunity for cybersecurity. Traditional approaches in cybersecurity monitoring often require different kinds of data pre-processing and handling for various data types, which might be problematic for datasets that contain heterogeneous features. However, heterogeneous types of network devices can often capture a more diverse set of signals than a single type of device readings, which is particularly useful for anomaly detection. In this paper, we present a comprehensive study on using ensemble machine learning methods for enhancing IoT cybersecurity via anomaly detection. Rather than using one single machine learning model, ensemble learning combines the predictive power from multiple models, enhancing their predictive accuracy in heterogeneous datasets rather than using one single machine learning model. We propose a unified framework with ensemble learning that utilises Bayesian hyperparameter optimisation to adapt to a network environment that contains multiple IoT sensor readings. Experimentally, we illustrate their high predictive power when compared to traditional methods.
Real-time Aerial Detection and Reasoning on Embedded-UAVs
May 21, 2023



We present a unified pipeline architecture for a real-time detection system on an embedded system for UAVs. Neural architectures have been the industry standard for computer vision. However, most existing works focus solely on concatenating deeper layers to achieve higher accuracy with run-time performance as the trade-off. This pipeline of networks can exploit the domain-specific knowledge on aerial pedestrian detection and activity recognition for the emerging UAV applications of autonomous surveying and activity reporting. In particular, our pipeline architectures operate in a time-sensitive manner, have high accuracy in detecting pedestrians from various aerial orientations, use a novel attention map for multi-activities recognition, and jointly refine its detection with temporal information. Numerically, we demonstrate our model's accuracy and fast inference speed on embedded systems. We empirically deployed our prototype hardware with full live feeds in a real-world open-field environment.
A Review on Visual-SLAM: Advancements from Geometric Modelling to Learning-based Semantic Scene Understanding
Sep 12, 2022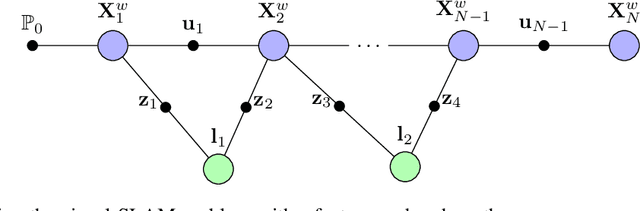
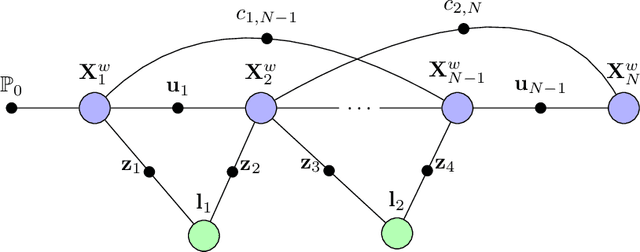


Simultaneous Localisation and Mapping (SLAM) is one of the fundamental problems in autonomous mobile robots where a robot needs to reconstruct a previously unseen environment while simultaneously localising itself with respect to the map. In particular, Visual-SLAM uses various sensors from the mobile robot for collecting and sensing a representation of the map. Traditionally, geometric model-based techniques were used to tackle the SLAM problem, which tends to be error-prone under challenging environments. Recent advancements in computer vision, such as deep learning techniques, have provided a data-driven approach to tackle the Visual-SLAM problem. This review summarises recent advancements in the Visual-SLAM domain using various learning-based methods. We begin by providing a concise overview of the geometric model-based approaches, followed by technical reviews on the current paradigms in SLAM. Then, we present the various learning-based approaches to collecting sensory inputs from mobile robots and performing scene understanding. The current paradigms in deep-learning-based semantic understanding are discussed and placed under the context of Visual-SLAM. Finally, we discuss challenges and further opportunities in the direction of learning-based approaches in Visual-SLAM.
Discover Life Skills for Planning with Bandits via Observing and Learning How the World Works
Jul 17, 2022


We propose a novel approach for planning agents to compose abstract skills via observing and learning from historical interactions with the world. Our framework operates in a Markov state-space model via a set of actions under unknown pre-conditions. We formulate skills as high-level abstract policies that propose action plans based on the current state. Each policy learns new plans by observing the states' transitions while the agent interacts with the world. Such an approach automatically learns new plans to achieve specific intended effects, but the success of such plans is often dependent on the states in which they are applicable. Therefore, we formulate the evaluation of such plans as infinitely many multi-armed bandit problems, where we balance the allocation of resources on evaluating the success probability of existing arms and exploring new options. The result is a planner capable of automatically learning robust high-level skills under a noisy environment; such skills implicitly learn the action pre-condition without explicit knowledge. We show that this planning approach is experimentally very competitive in high-dimensional state space domains.
Water and Sediment Analyse Using Predictive Models
Mar 04, 2022
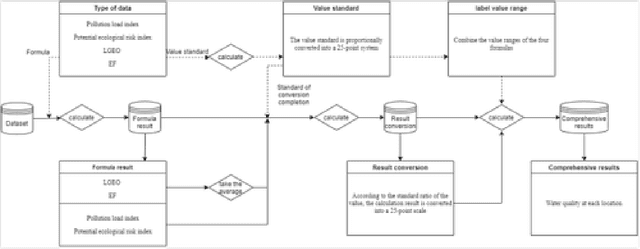

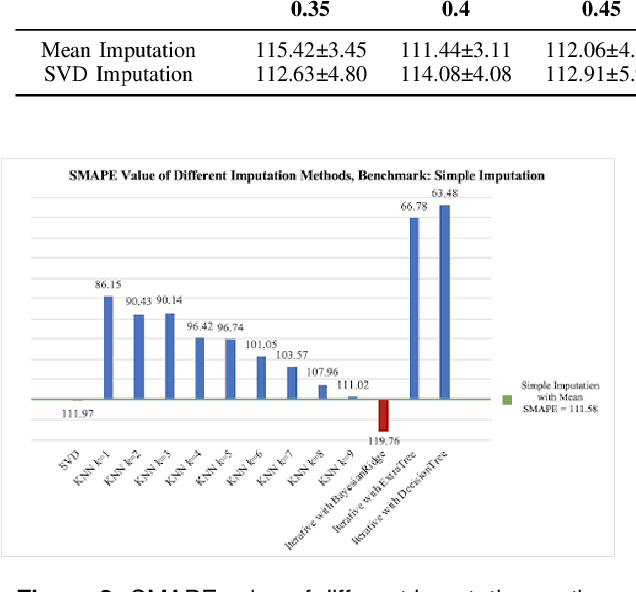
The increasing prevalence of marine pollution during the past few decades motivated recent research to help ease the situation. Typical water quality assessment requires continuous monitoring of water and sediments at remote locations with labour intensive laboratory tests to determine the degree of pollution. We propose an automated framework where we formalise a predictive model using Machine Learning to infer the water quality and level of pollution using collected water and sediments samples. One commonly encountered difficulty performing statistical analysis with water and sediment is the limited amount of data samples and incomplete dataset due to the sparsity of sample collection location. To this end, we performed extensive investigation on various data imputation methods' performance in water and sediment datasets with various data missing rates. Empirically, we show that our best model archives an accuracy of 75% after accounting for 57% of missing data. Experimentally, we show that our model would assist in assessing water quality screening based on possibly incomplete real-world data.
L4KDE: Learning for KinoDynamic Tree Expansion
Mar 02, 2022

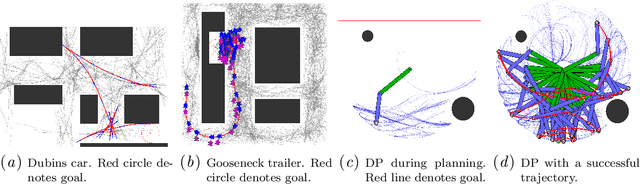
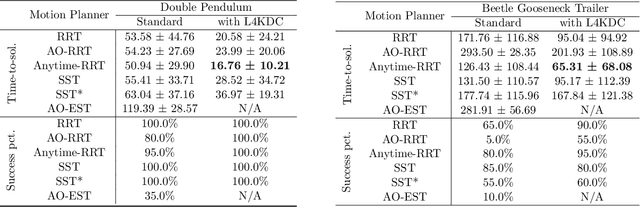
We present the Learning for KinoDynamic Tree Expansion (L4KDE) method for kinodynamic planning. Tree-based planning approaches, such as rapidly exploring random tree (RRT), are the dominant approach to finding globally optimal plans in continuous state-space motion planning. Central to these approaches is tree-expansion, the procedure in which new nodes are added into an ever-expanding tree. We study the kinodynamic variants of tree-based planning, where we have known system dynamics and kinematic constraints. In the interest of quickly selecting nodes to connect newly sampled coordinates, existing methods typically cannot optimise to find nodes which have low cost to transition to sampled coordinates. Instead they use metrics like Euclidean distance between coordinates as a heuristic for selecting candidate nodes to connect to the search tree. We propose L4KDE to address this issue. L4KDE uses a neural network to predict transition costs between queried states, which can be efficiently computed in batch, providing much higher quality estimates of transition cost compared to commonly used heuristics while maintaining almost-surely asymptotic optimality guarantee. We empirically demonstrate the significant performance improvement provided by L4KDE on a variety of challenging system dynamics, with the ability to generalise across different instances of the same model class, and in conjunction with a suite of modern tree-based motion planners.