 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinerU2.5-Pro: Pushing the Limits of Data-Centric Document Parsing at Scale
Apr 06, 2026Current document parsing methods compete primarily on model architecture innovation, while systematic engineering of training data remains underexplored. Yet SOTA models of different architectures and parameter scales exhibit highly consistent failure patterns on the same set of hard samples, suggesting that the performance bottleneck stems from shared deficiencies in training data rather than architecture itself. Building on this finding, we present \minerupro, which advances the state of the art solely through data engineering and training strategy optimization while keeping the 1.2B-parameter architecture of \mineru completely fixed. At its core is a Data Engine co-designed around coverage, informativeness, and annotation accuracy: Diversity-and-Difficulty-Aware Sampling expands training data from under 10M to 65.5M samples while correcting distribution shift; Cross-Model Consistency Verification leverages output agreement among heterogeneous models to assess sample difficulty and generate reliable annotations; the Judge-and-Refine pipeline improves annotation quality for hard samples through render-then-verify iterative correction. A three-stage progressive training strategy -- large-scale pre-training, hard sample fine-tuning, and GRPO alignment -- sequentially exploits these data at different quality tiers. On the evaluation front, we fix element-matching biases in OmniDocBench~v1.5 and introduce a Hard subset, establishing the more discriminative OmniDocBench~v1.6 protocol. Without any architectural modification, \minerupro achieves 95.69 on OmniDocBench~v1.6, improving over the same-architecture baseline by 2.71 points and surpassing all existing methods including models with over 200$\times$ more parameters.
pQuant: Towards Effective Low-Bit Language Models via Decoupled Linear Quantization-Aware Training
Feb 26, 2026Quantization-Aware Training from scratch has emerged as a promising approach for building efficient large language models (LLMs) with extremely low-bit weights (sub 2-bit), which can offer substantial advantages for edge deployment. However, existing methods still fail to achieve satisfactory accuracy and scalability. In this work, we identify a parameter democratization effect as a key bottleneck: the sensitivity of all parameters becomes homogenized, severely limiting expressivity. To address this, we propose pQuant, a method that decouples parameters by splitting linear layers into two specialized branches: a dominant 1-bit branch for efficient computation and a compact high-precision branch dedicated to preserving the most sensitive parameters. Through tailored feature scaling, we explicitly guide the model to allocate sensitive parameters to the high-precision branch. Furthermore, we extend this branch into multiple, sparsely-activated experts, enabling efficient capacity scaling. Extensive experiments indicate our pQuant achieves state-of-the-art performance in extremely low-bit quantization.
ReNCE: Learning to Reason by Noise Contrastive Estimation
Jan 30, 2026GRPO is a standard approach to endowing pretrained LLMs with reasoning capabilities. It estimates the advantage of an outcome from a group of $K$ outcomes, and promotes those with positive advantages inside a trust region. Since GRPO discriminates between good and bad outcomes softly, it benefits from additional refinements such as asymmetric clipping and zero-variance data filtering. While effective, these refinements require significant empirical insight and can be challenging to identify. We instead propose an explicit contrastive learning approach. Instead of estimating advantages, we bifurcate $K$ outcomes into positive and negative sets, then maximize the likelihood of positive outcomes. Our approach can be viewed as an online instantiation of (multi-label) noise contrastive estimation for LLM reasoning. We validate our method by demonstrating competitive performance on a suite of challenging math benchmarks against strong baselines such as DAPO and online DPO.
Loop Closure using AnyLoc Visual Place Recognition in DPV-SLAM
Jan 06, 2026Loop closure is crucial for maintaining the accuracy and consistency of visual SLAM. We propose a method to improve loop closure performance in DPV-SLAM. Our approach integrates AnyLoc, a learning-based visual place recognition technique, as a replacement for the classical Bag of Visual Words (BoVW) loop detection method. In contrast to BoVW, which relies on handcrafted features, AnyLoc utilizes deep feature representations, enabling more robust image retrieval across diverse viewpoints and lighting conditions. Furthermore, we propose an adaptive mechanism that dynamically adjusts similarity threshold based on environmental conditions, removing the need for manual tuning. Experiments on both indoor and outdoor datasets demonstrate that our method significantly outperforms the original DPV-SLAM in terms of loop closure accuracy and robustness. The proposed method offers a practical and scalable solution for enhancing loop closure performance in modern SLAM systems.
Topological Mapping and Navigation using a Monocular Camera based on AnyLoc
Jan 03, 2026This paper proposes a method for topological mapping and navigation using a monocular camera. Based on AnyLoc, keyframes are converted into descriptors to construct topological relationships, enabling loop detection and map building. Unlike metric maps, topological maps simplify path planning and navigation by representing environments with key nodes instead of precise coordinates. Actions for visual navigation are determined by comparing segmented images with the image associated with target nodes. The system relies solely on a monocular camera, ensuring fast map building and navigation using key nodes. Experiments show effective loop detection and navigation in real and simulation environments without pre-training. Compared to a ResNet-based method, this approach improves success rates by 60.2% on average while reducing time and space costs, offering a lightweight solution for robot and human navigation in various scenarios.
* Published in Proc. IEEE CASE 2025. 7 pages, 11 figures
MinerU2.5: A Decoupled Vision-Language Model for Efficient High-Resolution Document Parsing
Sep 26, 2025We introduce MinerU2.5, a 1.2B-parameter document parsing vision-language model that achieves state-of-the-art recognition accuracy while maintaining exceptional computational efficiency. Our approach employs a coarse-to-fine, two-stage parsing strategy that decouples global layout analysis from local content recognition. In the first stage, the model performs efficient layout analysis on downsampled images to identify structural elements, circumventing the computational overhead of processing high-resolution inputs. In the second stage, guided by the global layout, it performs targeted content recognition on native-resolution crops extracted from the original image, preserving fine-grained details in dense text, complex formulas, and tables. To support this strategy, we developed a comprehensive data engine that generates diverse, large-scale training corpora for both pretraining and fine-tuning. Ultimately, MinerU2.5 demonstrates strong document parsing ability, achieving state-of-the-art performance on multiple benchmarks, surpassing both general-purpose and domain-specific models across various recognition tasks, while maintaining significantly lower computational overhead.
Deformable Cluster Manipulation via Whole-Arm Policy Learning
Jul 22, 2025Manipulating clusters of deformable objects presents a substantial challenge with widespread applicability, but requires contact-rich whole-arm interactions. A potential solution must address the limited capacity for realistic model synthesis, high uncertainty in perception, and the lack of efficient spatial abstractions, among others. We propose a novel framework for learning model-free policies integrating two modalities: 3D point clouds and proprioceptive touch indicators, emphasising manipulation with full body contact awareness, going beyond traditional end-effector modes. Our reinforcement learning framework leverages a distributional state representation, aided by kernel mean embeddings, to achieve improved training efficiency and real-time inference. Furthermore, we propose a novel context-agnostic occlusion heuristic to clear deformables from a target region for exposure tasks. We deploy the framework in a power line clearance scenario and observe that the agent generates creative strategies leveraging multiple arm links for de-occlusion. Finally, we perform zero-shot sim-to-real policy transfer, allowing the arm to clear real branches with unknown occlusion patterns, unseen topology, and uncertain dynamics.
Grasping by parallel shape matching
Dec 11, 2024



Grasping is essential in robotic manipulation, yet challenging due to object and gripper diversity and real-world complexities. Traditional analytic approaches often have long optimization times, while data-driven methods struggle with unseen objects. This paper formulates the problem as a rigid shape matching between gripper and object, which optimizes with Annealed Stein Iterative Closest Point (AS-ICP) and leverages GPU-based parallelization. By incorporating the gripper's tool center point and the object's center of mass into the cost function and using a signed distance field of the gripper for collision checking, our method achieves robust grasps with low computational time. Experiments with the Kinova KG3 gripper show an 87.3% success rate and 0.926 s computation time across various objects and settings, highlighting its potential for real-world applications.
Seq2seq is All You Need for Coreference Resolution
Oct 20, 2023

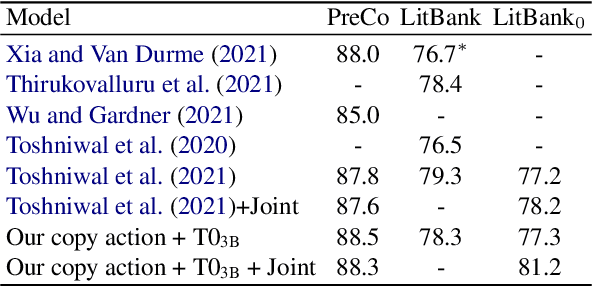
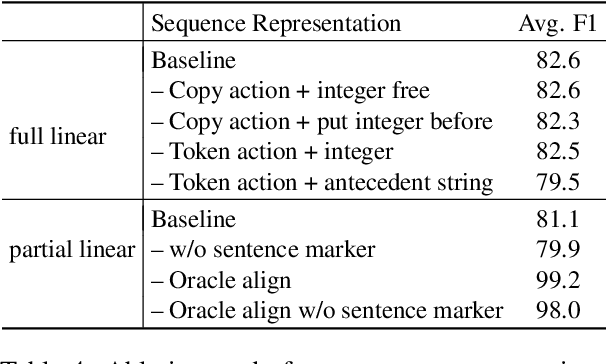
Existing works on coreference resolution suggest that task-specific models are necessary to achieve state-of-the-art performance. In this work, we present compelling evidence that such models are not necessary. We finetune a pretrained seq2seq transformer to map an input document to a tagged sequence encoding the coreference annotation. Despite the extreme simplicity, our model outperforms or closely matches the best coreference systems in the literature on an array of datasets. We also propose an especially simple seq2seq approach that generates only tagged spans rather than the spans interleaved with the original text. Our analysis shows that the model size, the amount of supervision, and the choice of sequence representations are key factors in performance.
Improving Multitask Retrieval by Promoting Task Specialization
Jul 01, 2023In multitask retrieval, a single retriever is trained to retrieve relevant contexts for multiple tasks. Despite its practical appeal, naive multitask retrieval lags behind task-specific retrieval in which a separate retriever is trained for each task. We show that it is possible to train a multitask retriever that outperforms task-specific retrievers by promoting task specialization. The main ingredients are: (1) a better choice of pretrained model (one that is explicitly optimized for multitasking) along with compatible prompting, and (2) a novel adaptive learning method that encourages each parameter to specialize in a particular task. The resulting multitask retriever is highly performant on the KILT benchmark. Upon analysis, we find that the model indeed learns parameters that are more task-specialized compared to naive multitasking without prompting or adaptive learning.