 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinerU2.5-Pro: Pushing the Limits of Data-Centric Document Parsing at Scale
Apr 06, 2026Current document parsing methods compete primarily on model architecture innovation, while systematic engineering of training data remains underexplored. Yet SOTA models of different architectures and parameter scales exhibit highly consistent failure patterns on the same set of hard samples, suggesting that the performance bottleneck stems from shared deficiencies in training data rather than architecture itself. Building on this finding, we present \minerupro, which advances the state of the art solely through data engineering and training strategy optimization while keeping the 1.2B-parameter architecture of \mineru completely fixed. At its core is a Data Engine co-designed around coverage, informativeness, and annotation accuracy: Diversity-and-Difficulty-Aware Sampling expands training data from under 10M to 65.5M samples while correcting distribution shift; Cross-Model Consistency Verification leverages output agreement among heterogeneous models to assess sample difficulty and generate reliable annotations; the Judge-and-Refine pipeline improves annotation quality for hard samples through render-then-verify iterative correction. A three-stage progressive training strategy -- large-scale pre-training, hard sample fine-tuning, and GRPO alignment -- sequentially exploits these data at different quality tiers. On the evaluation front, we fix element-matching biases in OmniDocBench~v1.5 and introduce a Hard subset, establishing the more discriminative OmniDocBench~v1.6 protocol. Without any architectural modification, \minerupro achieves 95.69 on OmniDocBench~v1.6, improving over the same-architecture baseline by 2.71 points and surpassing all existing methods including models with over 200$\times$ more parameters.
Intern-S1-Pro: Scientific Multimodal Foundation Model at Trillion Scale
Mar 26, 2026We introduce Intern-S1-Pro, the first one-trillion-parameter scientific multimodal foundation model. Scaling to this unprecedented size, the model delivers a comprehensive enhancement across both general and scientific domains. Beyond stronger reasoning and image-text understanding capabilities, its intelligence is augmented with advanced agent capabilities. Simultaneously, its scientific expertise has been vastly expanded to master over 100 specialized tasks across critical science fields, including chemistry, materials, life sciences, and earth sciences. Achieving this massive scale is made possible by the robust infrastructure support of XTuner and LMDeploy, which facilitates highly efficient Reinforcement Learning (RL) training at the 1-trillion parameter level while ensuring strict precision consistency between training and inference. By seamlessly integrating these advancements, Intern-S1-Pro further fortifies the fusion of general and specialized intelligence, working as a Specializable Generalist, demonstrating its position in the top tier of open-source models for general capabilities, while outperforming proprietary models in the depth of specialized scientific tasks.
MinerU2.5: A Decoupled Vision-Language Model for Efficient High-Resolution Document Parsing
Sep 26, 2025We introduce MinerU2.5, a 1.2B-parameter document parsing vision-language model that achieves state-of-the-art recognition accuracy while maintaining exceptional computational efficiency. Our approach employs a coarse-to-fine, two-stage parsing strategy that decouples global layout analysis from local content recognition. In the first stage, the model performs efficient layout analysis on downsampled images to identify structural elements, circumventing the computational overhead of processing high-resolution inputs. In the second stage, guided by the global layout, it performs targeted content recognition on native-resolution crops extracted from the original image, preserving fine-grained details in dense text, complex formulas, and tables. To support this strategy, we developed a comprehensive data engine that generates diverse, large-scale training corpora for both pretraining and fine-tuning. Ultimately, MinerU2.5 demonstrates strong document parsing ability, achieving state-of-the-art performance on multiple benchmarks, surpassing both general-purpose and domain-specific models across various recognition tasks, while maintaining significantly lower computational overhead.
Explanation for Trajectory Planning using Multi-modal Large Language Model for Autonomous Driving
Nov 15, 2024End-to-end style autonomous driving models have been developed recently. These models lack interpretability of decision-making process from perception to control of the ego vehicle, resulting in anxiety for passengers. To alleviate it, it is effective to build a model which outputs captions describing future behaviors of the ego vehicle and their reason. However, the existing approaches generate reasoning text that inadequately reflects the future plans of the ego vehicle, because they train models to output captions using momentary control signals as inputs. In this study, we propose a reasoning model that takes future planning trajectories of the ego vehicle as inputs to solve this limitation with the dataset newly collected.
V3Det Challenge 2024 on Vast Vocabulary and Open Vocabulary Object Detection: Methods and Results
Jun 17, 2024


Detecting objects in real-world scenes is a complex task due to various challenges, including the vast range of object categories, and potential encounters with previously unknown or unseen objects. The challenges necessitate the development of public benchmarks and challenges to advance the field of object detection. Inspired by the success of previous COCO and LVIS Challenges, we organize the V3Det Challenge 2024 in conjunction with the 4th Open World Vision Workshop: Visual Perception via Learning in an Open World (VPLOW) at CVPR 2024, Seattle, US. This challenge aims to push the boundaries of object detection research and encourage innovation in this field. The V3Det Challenge 2024 consists of two tracks: 1) Vast Vocabulary Object Detection: This track focuses on detecting objects from a large set of 13204 categories, testing the detection algorithm's ability to recognize and locate diverse objects. 2) Open Vocabulary Object Detection: This track goes a step further, requiring algorithms to detect objects from an open set of categories, including unknown objects. In the following sections, we will provide a comprehensive summary and analysis of the solutions submitted by participants. By analyzing the methods and solutions presented, we aim to inspire future research directions in vast vocabulary and open-vocabulary object detection, driving progress in this field. Challenge homepage: https://v3det.openxlab.org.cn/challenge
MMDU: A Multi-Turn Multi-Image Dialog Understanding Benchmark and Instruction-Tuning Dataset for LVLMs
Jun 17, 2024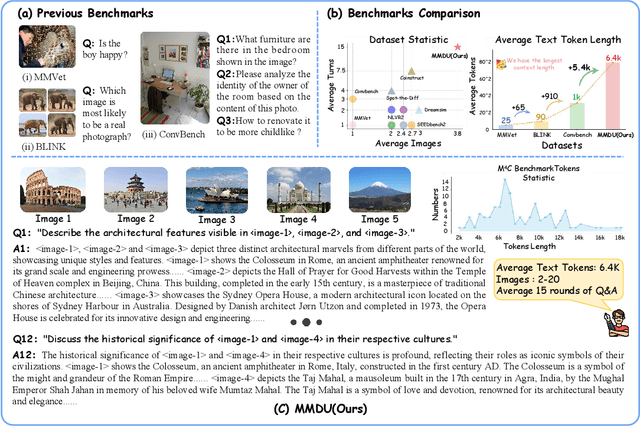
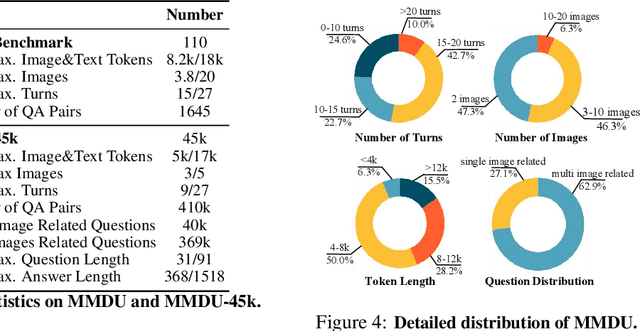
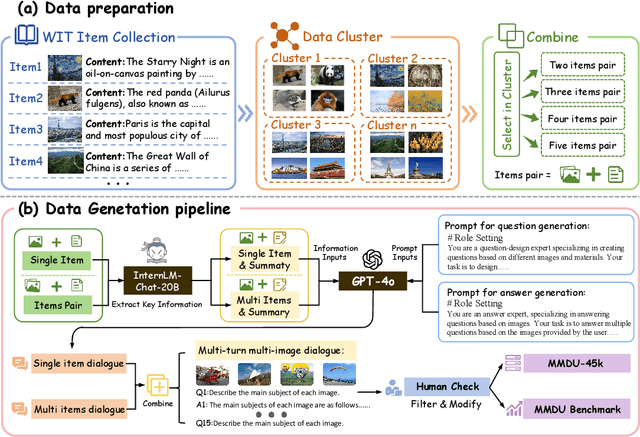

Generating natural and meaningful responses to communicate with multi-modal human inputs is a fundamental capability of Large Vision-Language Models(LVLMs). While current open-source LVLMs demonstrate promising performance in simplified scenarios such as single-turn single-image input, they fall short in real-world conversation scenarios such as following instructions in a long context history with multi-turn and multi-images. Existing LVLM benchmarks primarily focus on single-choice questions or short-form responses, which do not adequately assess the capabilities of LVLMs in real-world human-AI interaction applications. Therefore, we introduce MMDU, a comprehensive benchmark, and MMDU-45k, a large-scale instruction tuning dataset, designed to evaluate and improve LVLMs' abilities in multi-turn and multi-image conversations. We employ the clustering algorithm to ffnd the relevant images and textual descriptions from the open-source Wikipedia and construct the question-answer pairs by human annotators with the assistance of the GPT-4o model. MMDU has a maximum of 18k image+text tokens, 20 images, and 27 turns, which is at least 5x longer than previous benchmarks and poses challenges to current LVLMs. Our in-depth analysis of 15 representative LVLMs using MMDU reveals that open-source LVLMs lag behind closed-source counterparts due to limited conversational instruction tuning data. We demonstrate that ffne-tuning open-source LVLMs on MMDU-45k signiffcantly address this gap, generating longer and more accurate conversations, and improving scores on MMDU and existing benchmarks (MMStar: +1.1%, MathVista: +1.5%, ChartQA:+1.2%). Our contributions pave the way for bridging the gap between current LVLM models and real-world application demands. This project is available at https://github.com/Liuziyu77/MMDU.
Unified Scene Representation and Reconstruction for 3D Large Language Models
Apr 19, 2024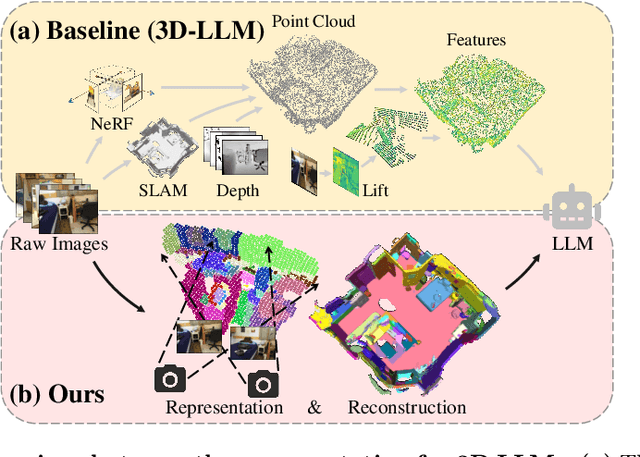
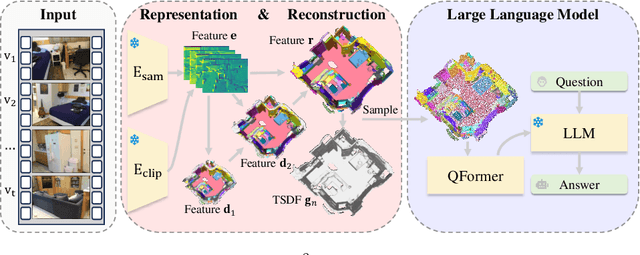
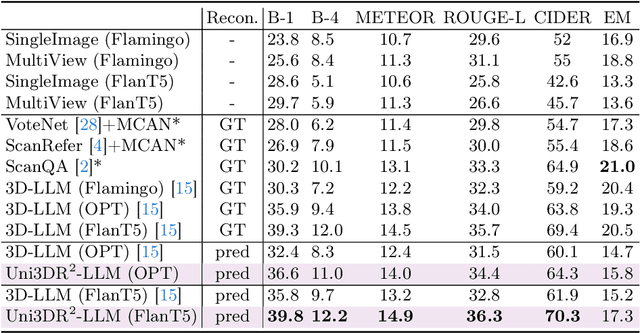
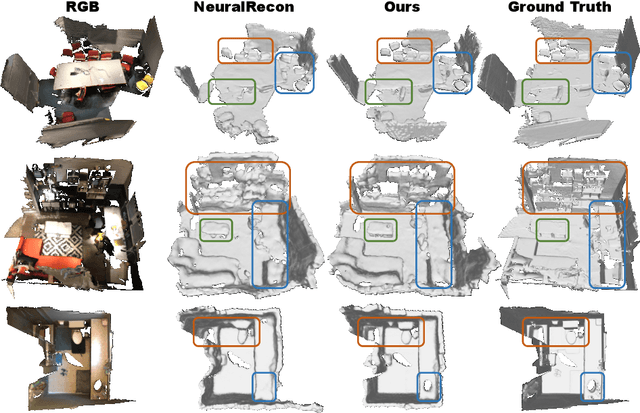
Enabling Large Language Models (LLMs) to interact with 3D environments is challenging. Existing approaches extract point clouds either from ground truth (GT) geometry or 3D scenes reconstructed by auxiliary models. Text-image aligned 2D features from CLIP are then lifted to point clouds, which serve as inputs for LLMs. However, this solution lacks the establishment of 3D point-to-point connections, leading to a deficiency of spatial structure information. Concurrently, the absence of integration and unification between the geometric and semantic representations of the scene culminates in a diminished level of 3D scene understanding. In this paper, we demonstrate the importance of having a unified scene representation and reconstruction framework, which is essential for LLMs in 3D scenes. Specifically, we introduce Uni3DR^2 extracts 3D geometric and semantic aware representation features via the frozen pre-trained 2D foundation models (e.g., CLIP and SAM) and a multi-scale aggregate 3D decoder. Our learned 3D representations not only contribute to the reconstruction process but also provide valuable knowledge for LLMs. Experimental results validate that our Uni3DR^2 yields convincing gains over the baseline on the 3D reconstruction dataset ScanNet (increasing F-Score by +1.8\%). When applied to LLMs, our Uni3DR^2-LLM exhibits superior performance over the baseline on the 3D vision-language understanding dataset ScanQA (increasing BLEU-1 by +4.0\% and +4.2\% on the val set and test set, respectively). Furthermore, it outperforms the state-of-the-art method that uses additional GT point clouds on both ScanQA and 3DMV-VQA.
BUOL: A Bottom-Up Framework with Occupancy-aware Lifting for Panoptic 3D Scene Reconstruction From A Single Image
Jun 01, 2023Understanding and modeling the 3D scene from a single image is a practical problem. A recent advance proposes a panoptic 3D scene reconstruction task that performs both 3D reconstruction and 3D panoptic segmentation from a single image. Although having made substantial progress, recent works only focus on top-down approaches that fill 2D instances into 3D voxels according to estimated depth, which hinders their performance by two ambiguities. (1) instance-channel ambiguity: The variable ids of instances in each scene lead to ambiguity during filling voxel channels with 2D information, confusing the following 3D refinement. (2) voxel-reconstruction ambiguity: 2D-to-3D lifting with estimated single view depth only propagates 2D information onto the surface of 3D regions, leading to ambiguity during the reconstruction of regions behind the frontal view surface. In this paper, we propose BUOL, a Bottom-Up framework with Occupancy-aware Lifting to address the two issues for panoptic 3D scene reconstruction from a single image. For instance-channel ambiguity, a bottom-up framework lifts 2D information to 3D voxels based on deterministic semantic assignments rather than arbitrary instance id assignments. The 3D voxels are then refined and grouped into 3D instances according to the predicted 2D instance centers. For voxel-reconstruction ambiguity, the estimated multi-plane occupancy is leveraged together with depth to fill the whole regions of things and stuff. Our method shows a tremendous performance advantage over state-of-the-art methods on synthetic dataset 3D-Front and real-world dataset Matterport3D. Code and models are available in https://github.com/chtsy/buol.
V3Det: Vast Vocabulary Visual Detection Dataset
Apr 07, 2023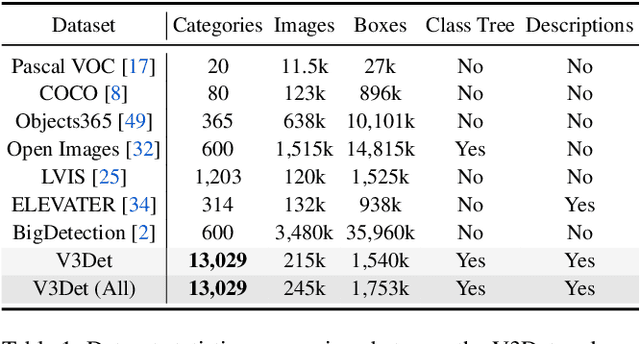
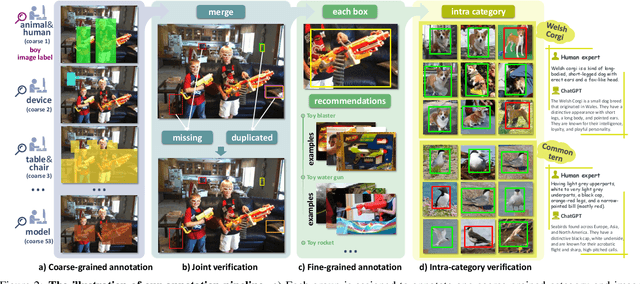
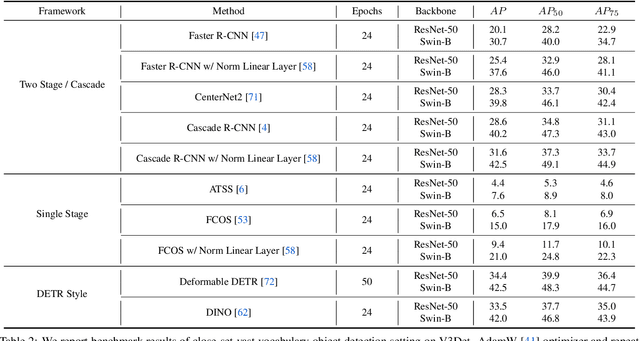
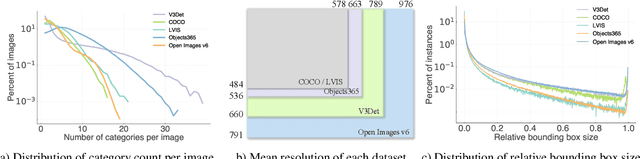
Recent advances in detecting arbitrary objects in the real world are trained and evaluated on object detection datasets with a relatively restricted vocabulary. To facilitate the development of more general visual object detection, we propose V3Det, a vast vocabulary visual detection dataset with precisely annotated bounding boxes on massive images. V3Det has several appealing properties: 1) Vast Vocabulary: It contains bounding boxes of objects from 13,029 categories on real-world images, which is 10 times larger than the existing large vocabulary object detection dataset, e.g., LVIS. 2) Hierarchical Category Organization: The vast vocabulary of V3Det is organized by a hierarchical category tree which annotates the inclusion relationship among categories, encouraging the exploration of category relationships in vast and open vocabulary object detection. 3) Rich Annotations: V3Det comprises precisely annotated objects in 245k images and professional descriptions of each category written by human experts and a powerful chatbot. By offering a vast exploration space, V3Det enables extensive benchmarks on both vast and open vocabulary object detection, leading to new observations, practices, and insights for future research. It has the potential to serve as a cornerstone dataset for developing more general visual perception systems.