 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMDU: A Multi-Turn Multi-Image Dialog Understanding Benchmark and Instruction-Tuning Dataset for LVLMs
Paper and Code
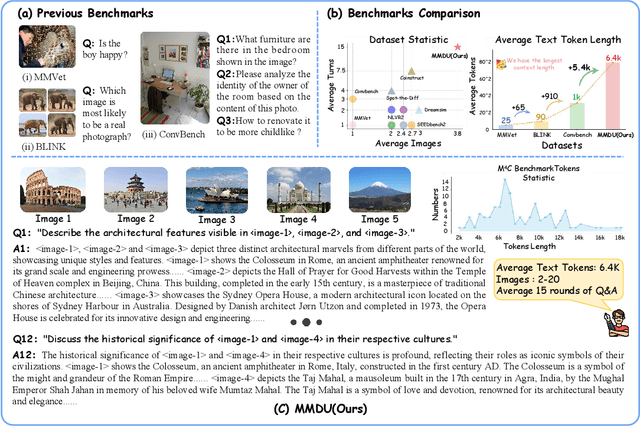
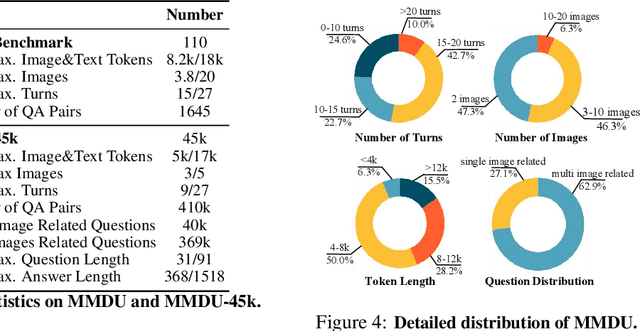
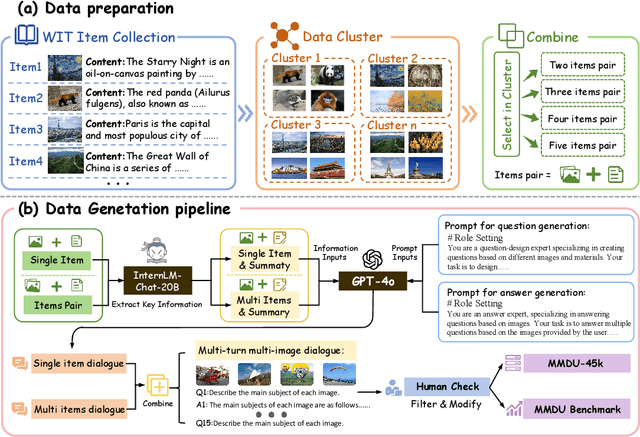

Generating natural and meaningful responses to communicate with multi-modal human inputs is a fundamental capability of Large Vision-Language Models(LVLMs). While current open-source LVLMs demonstrate promising performance in simplified scenarios such as single-turn single-image input, they fall short in real-world conversation scenarios such as following instructions in a long context history with multi-turn and multi-images. Existing LVLM benchmarks primarily focus on single-choice questions or short-form responses, which do not adequately assess the capabilities of LVLMs in real-world human-AI interaction applications. Therefore, we introduce MMDU, a comprehensive benchmark, and MMDU-45k, a large-scale instruction tuning dataset, designed to evaluate and improve LVLMs' abilities in multi-turn and multi-image conversations. We employ the clustering algorithm to ffnd the relevant images and textual descriptions from the open-source Wikipedia and construct the question-answer pairs by human annotators with the assistance of the GPT-4o model. MMDU has a maximum of 18k image+text tokens, 20 images, and 27 turns, which is at least 5x longer than previous benchmarks and poses challenges to current LVLMs. Our in-depth analysis of 15 representative LVLMs using MMDU reveals that open-source LVLMs lag behind closed-source counterparts due to limited conversational instruction tuning data. We demonstrate that ffne-tuning open-source LVLMs on MMDU-45k signiffcantly address this gap, generating longer and more accurate conversations, and improving scores on MMDU and existing benchmarks (MMStar: +1.1%, MathVista: +1.5%, ChartQA:+1.2%). Our contributions pave the way for bridging the gap between current LVLM models and real-world application demands. This project is available at https://github.com/Liuziyu77/MMDU.