 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCapRL++: Unified Reinforcement Learning with Verifiable Rewards for Dense Image and Video Captioning
Jun 08, 2026Image and video captioning are fundamental tasks that bridge the visual and linguistic domains, playing a critical role in pre-training Large Vision-Language Models (LVLMs). Current state-of-the-art captioning models are typically trained with Supervised Fine-Tuning (SFT), a paradigm that relies on expensive, non-scalable annotations and often causes models to memorize specific ground-truth answers, limiting their generality and ability to generate diverse, creative descriptions. To overcome these limitations, we propose applying Reinforcement Learning with Verifiable Rewards (RLVR) to the open-ended task of multimodal captioning. We introduce Captioning Reinforcement Learning++ (CapRL++), a novel reference-free training framework that redefines caption quality through its utility: a high-quality caption should enable a non-visual language model to accurately answer questions about the corresponding visual content. CapRL++ employs a decoupled two-stage pipeline where an LVLM generates a caption, and the objective reward is derived from the accuracy of a separate, vision-free LLM answering Multiple-Choice Questions based solely on that caption. Evaluations on more than 20 image and video benchmarks show that CapRL++ improves dense caption quality and strengthens caption-based pretraining across tasks such as spatial and temporal understanding. Pretraining on scalable image and video caption datasets annotated by CapRL++ yields substantial downstream gains. Furthermore, within the Prism Framework for caption quality evaluation, compact models trained with CapRL++ achieve dense captioning performance comparable to substantially larger models such as Qwen2.5-VL-72B and Qwen3-VL-235B-A22B. These results validate that CapRL++ effectively trains models to produce generalizable, high-fidelity descriptions, establishing a robust foundation beyond the limitations of traditional SFT.
AdaGRPO: A Capability-Aware Adaptive Enhancement for Flow-based GRPO
Jun 05, 2026Group Relative Policy Optimization (GRPO) has demonstrated remarkable success in aligning text-to-image (T2I) flow models with human preferences. However, we have identified that the learning loop of current flow-based GRPO is fundamentally decoupled from the learner's current capability, suffering from critical blind spots at both prompt selection and advantage estimation: (i) Existing methods sample prompts randomly, overlooking the substantial impact of data selection on reinforcement learning (RL) efficacy--a factor proven crucial in GRPO for large language models; (ii) They evaluate sample quality solely relying on intra-group statistics, lacking a global perspective to accurately measure true policy improvement. To address these issues, we propose Adaptive GRPO (AdaGRPO), a novel capability-aware RL algorithm tailored for flow models. Specifically, AdaGRPO consists of two principal components: (i) Online Curriculum Filtering Strategy: Dynamically tracks the model's proficiency and adaptively selects prompts that best match its current learning boundary; (ii) Cross-Level Advantage Fusion: Synergistically integrates fine-grained intra-group advantages with macro-level global advantages, providing a comprehensive and unbiased policy evaluation. As a lightweight, plug-and-play module, AdaGRPO can be seamlessly integrated with existing frameworks such as Flow-GRPO, DanceGRPO, and Flow-CPS. Extensive experiments demonstrate that AdaGRPO consistently drives performance gains while significantly stabilizes GRPO training for flow models.
Pave-GRPO: Beyond Instantaneous Guidance through Principled Average Velocity Decomposition
Jun 01, 2026Post-training via Group Relative Policy Optimization (GRPO) has emerged as a powerful paradigm for aligning flow-based generative models with human preferences. However, the iterative denoising nature of flow models incurs substantial costs when generating group rollouts for policy-gradient updates, compelling existing methods to train with extremely few denoising steps. This temporal sparsity severely restricts preference optimization: reward feedback can only reach a handful of stages per trajectory, leaving the vast majority of intermediate denoising steps without direct supervision and thus compromising alignment granularity. To address this, we propose Pave-GRPO, which reformulates the GRPO objective through Principled average velocity decomposition. Rather than generating expensive high-step rollouts, we maintain efficient few-step group sampling but decompose each coarse transition into an equivalent ensemble of finer sub-trajectories spanning multiple intermediate timesteps. This propagates reward feedback to a denser set of temporal stages for more comprehensive preference alignment without additional generation cost. This design offers two benefits: (i) zero-cost horizon expansion: through the direct reuse of piece-wise group samples and their associated rewards, Pave-GRPO significantly broadens the effective optimization scope under fixed sampling budgets; and (ii) comprehensive temporal supervision: by equivalently decomposing an instantaneous velocity target into a multi-timestep ensemble, it distributes reward signals across more intermediate stages of the denoising process, enabling finer-grained and more thorough preference optimization. Extensive experiments validate that Pave-GRPO effectively advances preference alignment across different reward settings, offering comprehensive performance enhancement.
SANEmerg: An Emergent Communication Framework for Semantic-aware Agentic AI Networking
May 07, 2026Future networking systems are envisioned to become part of an agentic AI-native ecosystem in which a vast number of heterogeneous and specialized AI agents cooperate seamlessly to fulfill complex user requirements in real time. However, traditional networking paradigms are characterized by a rigid decoupling of communication and computation, which often leads to significant inefficiencies in large-scale agentic AI networking (AgentNet) systems. Emergent communication offers a novel solution by enabling autonomous agents that support task-specific signaling protocols for information exchange and collaborative coordination. In this paper, we consider a multi-agent emergent communication framework, tailored for semantic-aware AgentNet systems in which the user's semantic intent can be automatically detected, inferred, and linked to a set of sub-tasks to be assigned to a set of agents. We investigate how communication and signaling protocols can emerge among collaborative agents with computationally bounded intelligence under stringent bandwidth constraints. Our proposed framework, called SANEmerg, is designed to facilitate the emergence of communication for collaborative task fulfillment while adhering to the physical limits of AgentNet. SANEmerg incorporates a bandwidth-adaptable importance-filter that dynamically prioritizes the transmission of higher-contribution message dimensions, ensuring robust performance in bandwidth-limited environments. Furthermore, SANEmerg integrates a complexity-regularizer grounded in the Minimum Description Length (MDL) principle to facilitate the emergence of computationally bounded signaling. Evaluated via an AgentNet prototype and extensive experimentation, SANEmerg demonstrates significant performance improvements over state-of-the-art solutions, achieving superior task accuracy while significantly reducing bandwidth and computational overhead.
Uni-Classifier: Leveraging Video Diffusion Priors for Universal Guidance Classifier
Mar 20, 2026In practical AI workflows, complex tasks often involve chaining multiple generative models, such as using a video or 3D generation model after a 2D image generator. However, distributional mismatches between the output of upstream models and the expected input of downstream models frequently degrade overall generation quality. To address this issue, we propose Uni-Classifier (Uni-C), a simple yet effective plug-and-play module that leverages video diffusion priors to guide the denoising process of preceding models, thereby aligning their outputs with downstream requirements. Uni-C can also be applied independently to enhance the output quality of individual generative models. Extensive experiments across video and 3D generation tasks demonstrate that Uni-C consistently improves generation quality in both workflow-based and standalone settings, highlighting its versatility and strong generalization capability.
From Sparse to Dense: Multi-View GRPO for Flow Models via Augmented Condition Space
Mar 13, 2026Group Relative Policy Optimization (GRPO) has emerged as a powerful framework for preference alignment in text-to-image (T2I) flow models. However, we observe that the standard paradigm where evaluating a group of generated samples against a single condition suffers from insufficient exploration of inter-sample relationships, constraining both alignment efficacy and performance ceilings. To address this sparse single-view evaluation scheme, we propose Multi-View GRPO (MV-GRPO), a novel approach that enhances relationship exploration by augmenting the condition space to create a dense multi-view reward mapping. Specifically, for a group of samples generated from one prompt, MV-GRPO leverages a flexible Condition Enhancer to generate semantically adjacent yet diverse captions. These captions enable multi-view advantage re-estimation, capturing diverse semantic attributes and providing richer optimization signals. By deriving the probability distribution of the original samples conditioned on these new captions, we can incorporate them into the training process without costly sample regeneration. Extensive experiments demonstrate that MV-GRPO achieves superior alignment performance over state-of-the-art methods.
EndoCoT: Scaling Endogenous Chain-of-Thought Reasoning in Diffusion Models
Mar 12, 2026Recently, Multimodal Large Language Models (MLLMs) have been widely integrated into diffusion frameworks primarily as text encoders to tackle complex tasks such as spatial reasoning. However, this paradigm suffers from two critical limitations: (i) MLLMs text encoder exhibits insufficient reasoning depth. Single-step encoding fails to activate the Chain-of-Thought process, which is essential for MLLMs to provide accurate guidance for complex tasks. (ii) The guidance remains invariant during the decoding process. Invariant guidance during decoding prevents DiT from progressively decomposing complex instructions into actionable denoising steps, even with correct MLLM encodings. To this end, we propose Endogenous Chain-of-Thought (EndoCoT), a novel framework that first activates MLLMs' reasoning potential by iteratively refining latent thought states through an iterative thought guidance module, and then bridges these states to the DiT's denoising process. Second, a terminal thought grounding module is applied to ensure the reasoning trajectory remains grounded in textual supervision by aligning the final state with ground-truth answers. With these two components, the MLLM text encoder delivers meticulously reasoned guidance, enabling the DiT to execute it progressively and ultimately solve complex tasks in a step-by-step manner. Extensive evaluations across diverse benchmarks (e.g., Maze, TSP, VSP, and Sudoku) achieve an average accuracy of 92.1%, outperforming the strongest baseline by 8.3 percentage points.
Unified Personalized Reward Model for Vision Generation
Feb 02, 2026Recent advancements in multimodal reward models (RMs) have significantly propelled the development of visual generation. Existing frameworks typically adopt Bradley-Terry-style preference modeling or leverage generative VLMs as judges, and subsequently optimize visual generation models via reinforcement learning. However, current RMs suffer from inherent limitations: they often follow a one-size-fits-all paradigm that assumes a monolithic preference distribution or relies on fixed evaluation rubrics. As a result, they are insensitive to content-specific visual cues, leading to systematic misalignment with subjective and context-dependent human preferences. To this end, inspired by human assessment, we propose UnifiedReward-Flex, a unified personalized reward model for vision generation that couples reward modeling with flexible and context-adaptive reasoning. Specifically, given a prompt and the generated visual content, it first interprets the semantic intent and grounds on visual evidence, then dynamically constructs a hierarchical assessment by instantiating fine-grained criteria under both predefined and self-generated high-level dimensions. Our training pipeline follows a two-stage process: (1) we first distill structured, high-quality reasoning traces from advanced closed-source VLMs to bootstrap SFT, equipping the model with flexible and context-adaptive reasoning behaviors; (2) we then perform direct preference optimization (DPO) on carefully curated preference pairs to further strengthen reasoning fidelity and discriminative alignment. To validate the effectiveness, we integrate UnifiedReward-Flex into the GRPO framework for image and video synthesis, and extensive results demonstrate its superiority.
DynaDrag: Dynamic Drag-Style Image Editing by Motion Prediction
Jan 02, 2026To achieve pixel-level image manipulation, drag-style image editing which edits images using points or trajectories as conditions is attracting widespread attention. Most previous methods follow move-and-track framework, in which miss tracking and ambiguous tracking are unavoidable challenging issues. Other methods under different frameworks suffer from various problems like the huge gap between source image and target edited image as well as unreasonable intermediate point which can lead to low editability. To avoid these problems, we propose DynaDrag, the first dragging method under predict-and-move framework. In DynaDrag, Motion Prediction and Motion Supervision are performed iteratively. In each iteration, Motion Prediction first predicts where the handle points should move, and then Motion Supervision drags them accordingly. We also propose to dynamically adjust the valid handle points to further improve the performance. Experiments on face and human datasets showcase the superiority over previous works.
$\text{G}^2$RPO: Granular GRPO for Precise Reward in Flow Models
Oct 02, 2025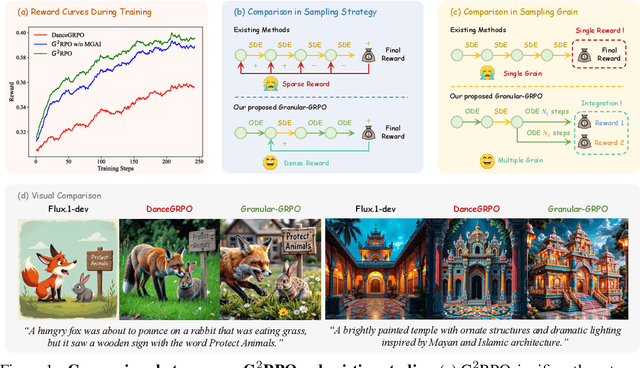
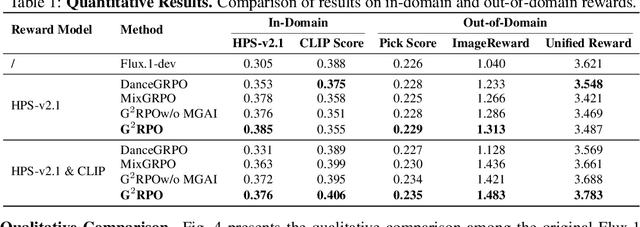
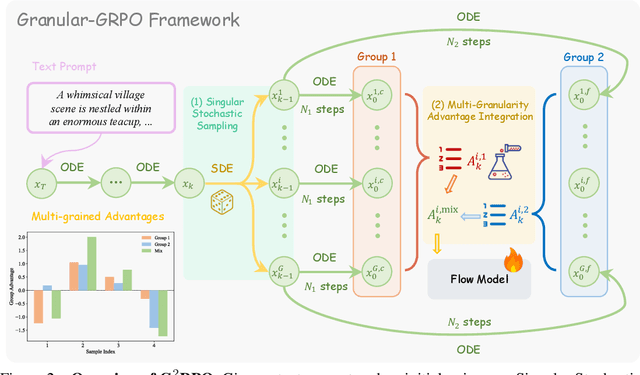
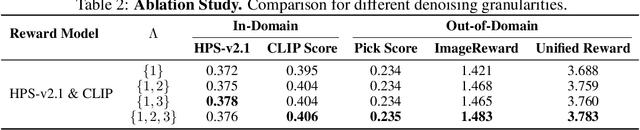
The integration of online reinforcement learning (RL) into diffusion and flow models has recently emerged as a promising approach for aligning generative models with human preferences. Stochastic sampling via Stochastic Differential Equations (SDE) is employed during the denoising process to generate diverse denoising directions for RL exploration. While existing methods effectively explore potential high-value samples, they suffer from sub-optimal preference alignment due to sparse and narrow reward signals. To address these challenges, we propose a novel Granular-GRPO ($\text{G}^2$RPO ) framework that achieves precise and comprehensive reward assessments of sampling directions in reinforcement learning of flow models. Specifically, a Singular Stochastic Sampling strategy is introduced to support step-wise stochastic exploration while enforcing a high correlation between the reward and the injected noise, thereby facilitating a faithful reward for each SDE perturbation. Concurrently, to eliminate the bias inherent in fixed-granularity denoising, we introduce a Multi-Granularity Advantage Integration module that aggregates advantages computed at multiple diffusion scales, producing a more comprehensive and robust evaluation of the sampling directions. Experiments conducted on various reward models, including both in-domain and out-of-domain evaluations, demonstrate that our $\text{G}^2$RPO significantly outperforms existing flow-based GRPO baselines,highlighting its effectiveness and robustness.