 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward a Sustainable Federated Learning Ecosystem: A Practical Least Core Mechanism for Payoff Allocation
Feb 03, 2026Emerging network paradigms and applications increasingly rely on federated learning (FL) to enable collaborative intelligence while preserving privacy. However, the sustainability of such collaborative environments hinges on a fair and stable payoff allocation mechanism. Focusing on coalition stability, this paper introduces a payoff allocation framework based on the least core (LC) concept. Unlike traditional methods, the LC prioritizes the cohesion of the federation by minimizing the maximum dissatisfaction among all potential subgroups, ensuring that no participant has an incentive to break away. To adapt this game-theoretic concept to practical, large-scale networks, we propose a streamlined implementation with a stack-based pruning algorithm, effectively balancing computational efficiency with allocation precision. Case studies in federated intrusion detection demonstrate that our mechanism correctly identifies pivotal contributors and strategic alliances. The results confirm that the practical LC framework promotes stable collaboration and fosters a sustainable FL ecosystem.
Depersonalized Federated Learning: Tackling Statistical Heterogeneity by Alternating Stochastic Gradient Descent
Oct 07, 2022

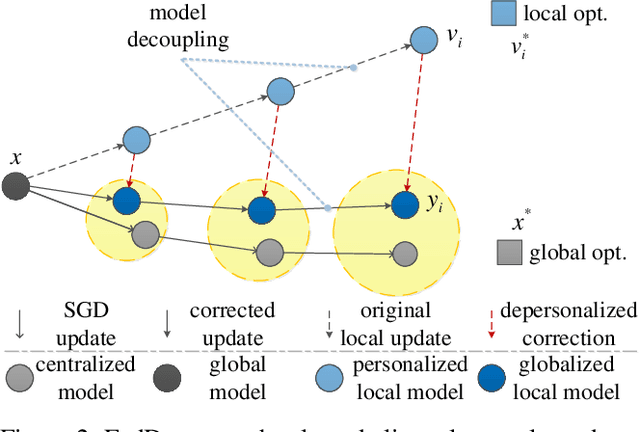
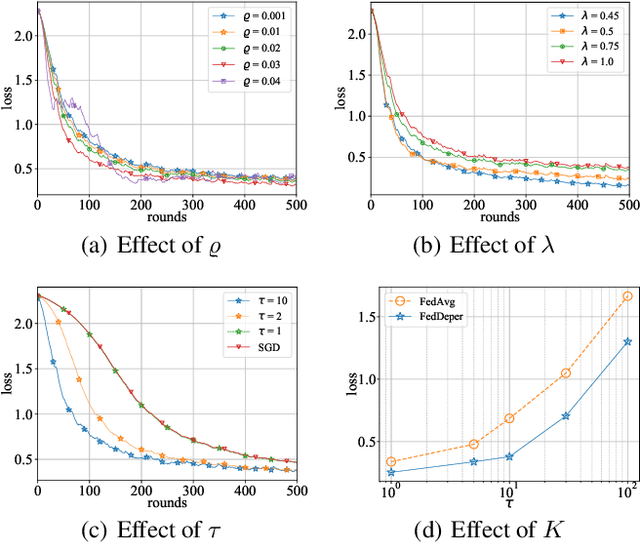
Federated learning (FL) has gained increasing attention recently, which enables distributed devices to train a common machine learning (ML) model for intelligent inference cooperatively without data sharing. However, the raw data held by various involved participators are always non-independent-and-identically-distributed (non-i.i.d), which results in slow convergence of the FL training process. To address this issue, we propose a new FL method that can significantly mitigate statistical heterogeneity by the depersonalized mechanism. Particularly, we decouple the global and local objectives optimized by performing stochastic gradient descent alternately to reduce the accumulated variance on the global model (generated in local update phases) hence accelerating the FL convergence. Then we analyze the proposed method detailedly to show the proposed method converging at a sublinear speed in the general non-convex setting. Finally, extensive numerical results are conducted with experiments on public datasets to verify the effectiveness of our proposed method.