 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Lack of Robustness of Binary Function Similarity Systems
Dec 05, 2024Binary function similarity, which often relies on learning-based algorithms to identify what functions in a pool are most similar to a given query function, is a sought-after topic in different communities, including machine learning, software engineering, and security. Its importance stems from the impact it has in facilitating several crucial tasks, from reverse engineering and malware analysis to automated vulnerability detection. Whereas recent work cast light around performance on this long-studied problem, the research landscape remains largely lackluster in understanding the resiliency of the state-of-the-art machine learning models against adversarial attacks. As security requires to reason about adversaries, in this work we assess the robustness of such models through a simple yet effective black-box greedy attack, which modifies the topology and the content of the control flow of the attacked functions. We demonstrate that this attack is successful in compromising all the models, achieving average attack success rates of 57.06% and 95.81% depending on the problem settings (targeted and untargeted attacks). Our findings are insightful: top performance on clean data does not necessarily relate to top robustness properties, which explicitly highlights performance-robustness trade-offs one should consider when deploying such models, calling for further research.
Depersonalized Federated Learning: Tackling Statistical Heterogeneity by Alternating Stochastic Gradient Descent
Oct 07, 2022

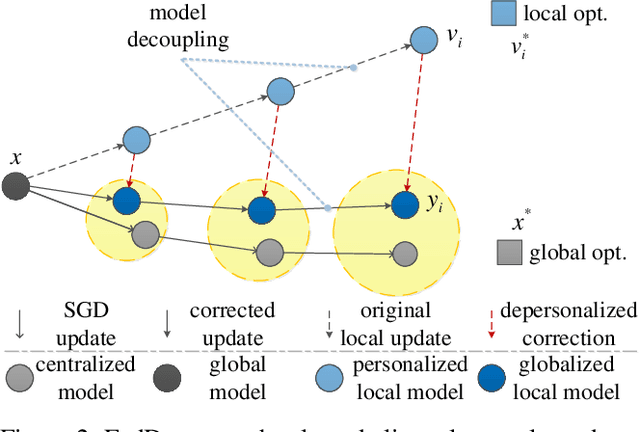
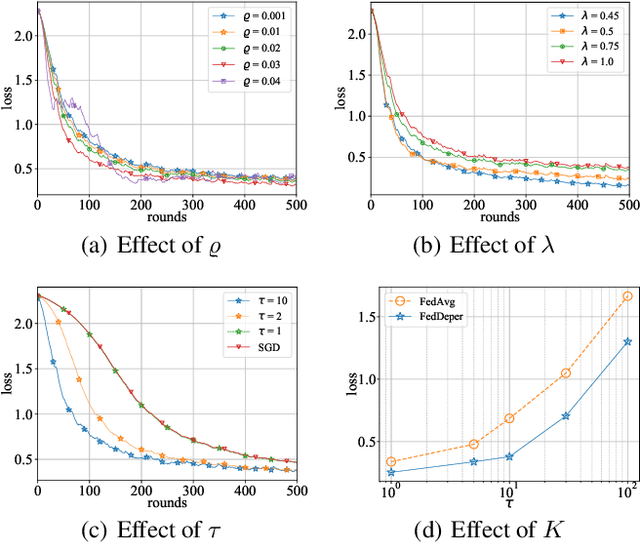
Federated learning (FL) has gained increasing attention recently, which enables distributed devices to train a common machine learning (ML) model for intelligent inference cooperatively without data sharing. However, the raw data held by various involved participators are always non-independent-and-identically-distributed (non-i.i.d), which results in slow convergence of the FL training process. To address this issue, we propose a new FL method that can significantly mitigate statistical heterogeneity by the depersonalized mechanism. Particularly, we decouple the global and local objectives optimized by performing stochastic gradient descent alternately to reduce the accumulated variance on the global model (generated in local update phases) hence accelerating the FL convergence. Then we analyze the proposed method detailedly to show the proposed method converging at a sublinear speed in the general non-convex setting. Finally, extensive numerical results are conducted with experiments on public datasets to verify the effectiveness of our proposed method.