 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Lack of Robustness of Binary Function Similarity Systems
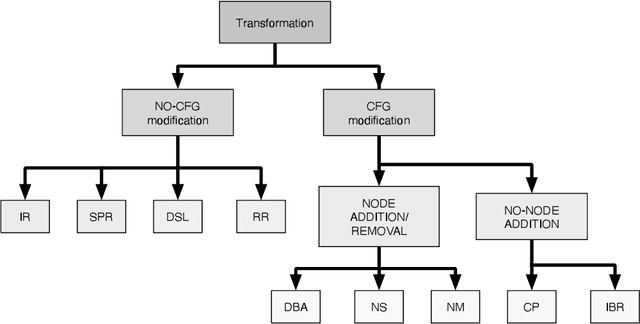
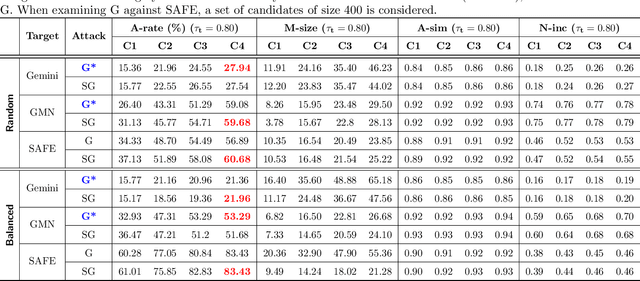
Dec 05, 2024Binary function similarity, which often relies on learning-based algorithms to identify what functions in a pool are most similar to a given query function, is a sought-after topic in different communities, including machine learning, software engineering, and security. Its importance stems from the impact it has in facilitating several crucial tasks, from reverse engineering and malware analysis to automated vulnerability detection. Whereas recent work cast light around performance on this long-studied problem, the research landscape remains largely lackluster in understanding the resiliency of the state-of-the-art machine learning models against adversarial attacks. As security requires to reason about adversaries, in this work we assess the robustness of such models through a simple yet effective black-box greedy attack, which modifies the topology and the content of the control flow of the attacked functions. We demonstrate that this attack is successful in compromising all the models, achieving average attack success rates of 57.06% and 95.81% depending on the problem settings (targeted and untargeted attacks). Our findings are insightful: top performance on clean data does not necessarily relate to top robustness properties, which explicitly highlights performance-robustness trade-offs one should consider when deploying such models, calling for further research.
Adversarial Attacks against Binary Similarity Systems
Mar 20, 2023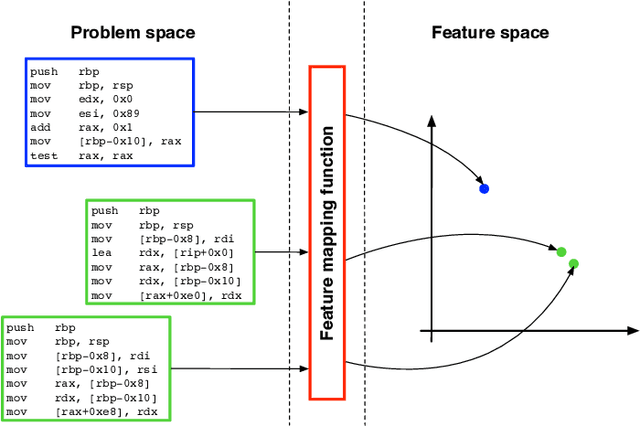

In recent years, binary analysis gained traction as a fundamental approach to inspect software and guarantee its security. Due to the exponential increase of devices running software, much research is now moving towards new autonomous solutions based on deep learning models, as they have been showing state-of-the-art performances in solving binary analysis problems. One of the hot topics in this context is binary similarity, which consists in determining if two functions in assembly code are compiled from the same source code. However, it is unclear how deep learning models for binary similarity behave in an adversarial context. In this paper, we study the resilience of binary similarity models against adversarial examples, showing that they are susceptible to both targeted and untargeted attacks (w.r.t. similarity goals) performed by black-box and white-box attackers. In more detail, we extensively test three current state-of-the-art solutions for binary similarity against two black-box greedy attacks, including a new technique that we call Spatial Greedy, and one white-box attack in which we repurpose a gradient-guided strategy used in attacks to image classifiers.
Function Naming in Stripped Binaries Using Neural Networks
Dec 17, 2019
In this paper we investigate the problem of automatically naming pieces of assembly code. Where by naming we mean assigning to portion of code the string of words that would be likely assigned by an human reverse engineer. We precisely define the framework in which our investigation takes place. That is we define problem, we provide reasonable justifications for the choice that we made during our designing of the training and test steps and we performed a statistical analysis of function names in a large real-world corpora of over 4 millions of functions. In such framework we test several baselines coming from the field of NLP.
SAFE: Self-Attentive Function Embeddings for Binary Similarity
Nov 21, 2018
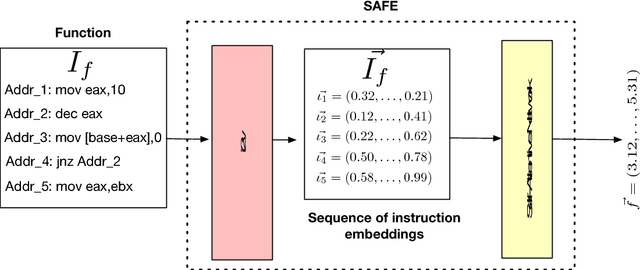
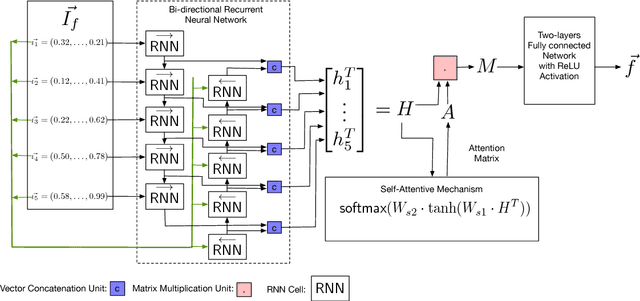
The binary similarity problem consists in determining if two functions are similar by only considering their compiled form. Advanced techniques for binary similarity recently gained momentum as they can be applied in several fields, such as copyright disputes, malware analysis, vulnerability detection, etc., and thus have an immediate practical impact. Current solutions compare functions by first transforming their binary code in multi-dimensional vector representations (embeddings), and then comparing vectors through simple and efficient geometric operations. However, embeddings are usually derived from binary code using manual feature extraction, that may fail in considering important function characteristics, or may consider features that are not important for the binary similarity problem. In this paper we propose SAFE, a novel architecture for the embedding of functions based on a self-attentive neural network. SAFE works directly on disassembled binary functions, does not require manual feature extraction, is computationally more efficient than existing solutions (i.e., it does not incur in the computational overhead of building or manipulating control flow graphs), and is more general as it works on stripped binaries and on multiple architectures. We report the results from a quantitative and qualitative analysis that show how SAFE provides a noticeable performance improvement with respect to previous solutions. Furthermore, we show how clusters of our embedding vectors are closely related to the semantic of the implemented algorithms, paving the way for further interesting applications (e.g. semantic-based binary function search).
Unsupervised Features Extraction for Binary Similarity Using Graph Embedding Neural Networks
Oct 23, 2018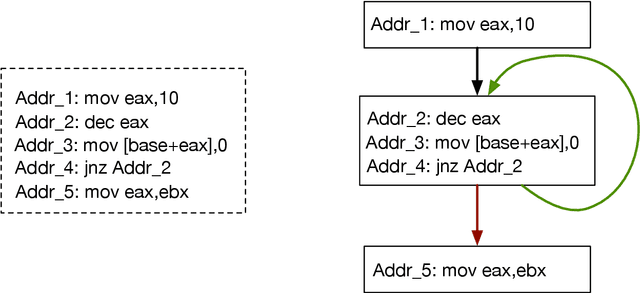
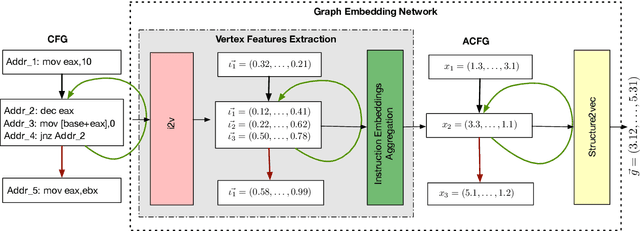
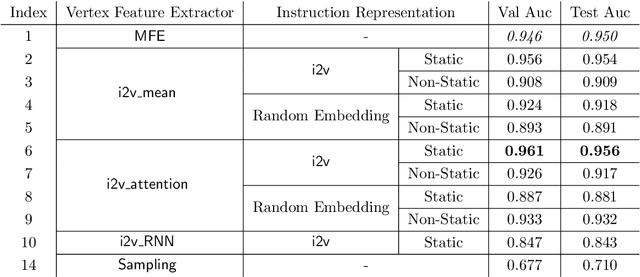
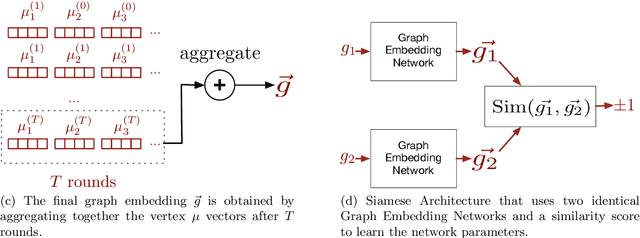
In this paper we consider the binary similarity problem that consists in determining if two binary functions are similar only considering their compiled form. This problem is know to be crucial in several application scenarios, such as copyright disputes, malware analysis, vulnerability detection, etc. The current state-of-the-art solutions in this field work by creating an embedding model that maps binary functions into vectors in $\mathbb{R}^{n}$. Such embedding model captures syntactic and semantic similarity between binaries, i.e., similar binary functions are mapped to points that are close in the vector space. This strategy has many advantages, one of them is the possibility to precompute embeddings of several binary functions, and then compare them with simple geometric operations (e.g., dot product). In [32] functions are first transformed in Annotated Control Flow Graphs (ACFGs) constituted by manually engineered features and then graphs are embedded into vectors using a deep neural network architecture. In this paper we propose and test several ways to compute annotated control flow graphs that use unsupervised approaches for feature learning, without incurring a human bias. Our methods are inspired after techniques used in the natural language processing community (e.g., we use word2vec to encode assembly instructions). We show that our approach is indeed successful, and it leads to better performance than previous state-of-the-art solutions. Furthermore, we report on a qualitative analysis of functions embeddings. We found interesting cases in which embeddings are clustered according to the semantic of the original binary function.