 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Methodologies for Agentic Evaluations Across Domains: Leakage of Sensitive Information, Fraud and Cybersecurity Threats
Jan 22, 2026The rapid rise of autonomous AI systems and advancements in agent capabilities are introducing new risks due to reduced oversight of real-world interactions. Yet agent testing remains nascent and is still a developing science. As AI agents begin to be deployed globally, it is important that they handle different languages and cultures accurately and securely. To address this, participants from The International Network for Advanced AI Measurement, Evaluation and Science, including representatives from Singapore, Japan, Australia, Canada, the European Commission, France, Kenya, South Korea, and the United Kingdom have come together to align approaches to agentic evaluations. This is the third exercise, building on insights from two earlier joint testing exercises conducted by the Network in November 2024 and February 2025. The objective is to further refine best practices for testing advanced AI systems. The exercise was split into two strands: (1) common risks, including leakage of sensitive information and fraud, led by Singapore AISI; and (2) cybersecurity, led by UK AISI. A mix of open and closed-weight models were evaluated against tasks from various public agentic benchmarks. Given the nascency of agentic testing, our primary focus was on understanding methodological issues in conducting such tests, rather than examining test results or model capabilities. This collaboration marks an important step forward as participants work together to advance the science of agentic evaluations.
Function Naming in Stripped Binaries Using Neural Networks
Dec 17, 2019
In this paper we investigate the problem of automatically naming pieces of assembly code. Where by naming we mean assigning to portion of code the string of words that would be likely assigned by an human reverse engineer. We precisely define the framework in which our investigation takes place. That is we define problem, we provide reasonable justifications for the choice that we made during our designing of the training and test steps and we performed a statistical analysis of function names in a large real-world corpora of over 4 millions of functions. In such framework we test several baselines coming from the field of NLP.
How Decoding Strategies Affect the Verifiability of Generated Text
Nov 09, 2019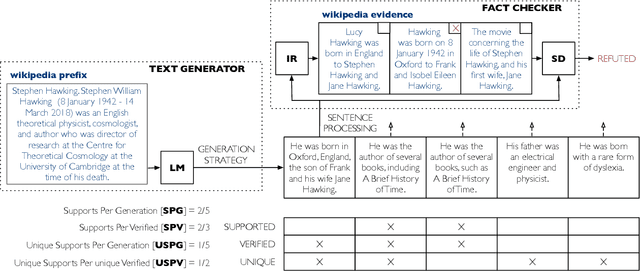
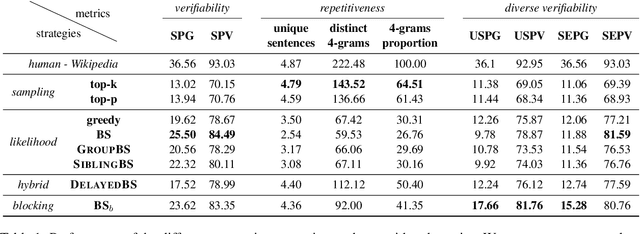
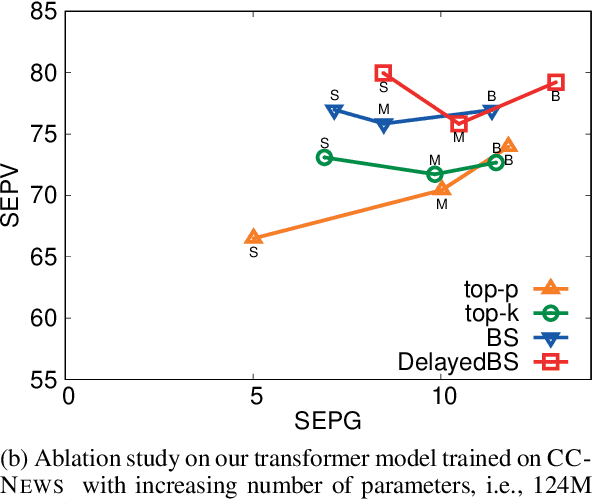

Language models are of considerable importance. They are used for pretraining, finetuning, and rescoring in downstream applications, and as is as a test-bed and benchmark for progress in natural language understanding. One fundamental question regards the way we should generate text from a language model. It is well known that different decoding strategies can have dramatic impact on the quality of the generated text and using the most likely sequence under the model distribution, e.g., via beam search, generally leads to degenerate and repetitive outputs. While generation strategies such as top-k and nucleus sampling lead to more natural and less repetitive generations, the true cost of avoiding the highest scoring solution is hard to quantify. In this paper, we argue that verifiability, i.e., the consistency of the generated text with factual knowledge, is a suitable metric for measuring this cost. We use an automatic fact-checking system to calculate new metrics as a function of the number of supported claims per sentence and find that sampling-based generation strategies, such as top-k, indeed lead to less verifiable text. This finding holds across various dimensions, such as model size, training data size and parameters of the generation strategy. Based on this finding, we introduce a simple and effective generation strategy for producing non-repetitive and more verifiable (in comparison to other methods) text.
SAFE: Self-Attentive Function Embeddings for Binary Similarity
Nov 21, 2018
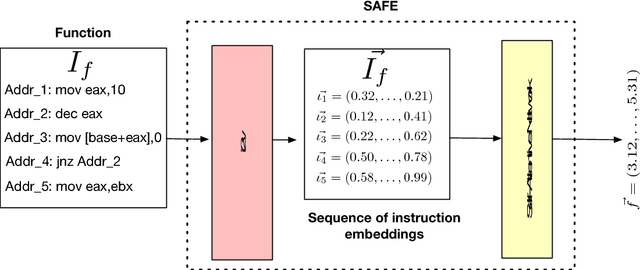
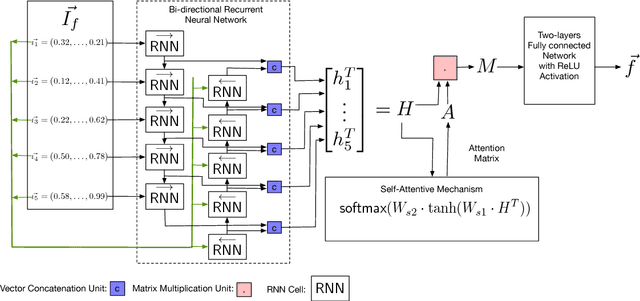
The binary similarity problem consists in determining if two functions are similar by only considering their compiled form. Advanced techniques for binary similarity recently gained momentum as they can be applied in several fields, such as copyright disputes, malware analysis, vulnerability detection, etc., and thus have an immediate practical impact. Current solutions compare functions by first transforming their binary code in multi-dimensional vector representations (embeddings), and then comparing vectors through simple and efficient geometric operations. However, embeddings are usually derived from binary code using manual feature extraction, that may fail in considering important function characteristics, or may consider features that are not important for the binary similarity problem. In this paper we propose SAFE, a novel architecture for the embedding of functions based on a self-attentive neural network. SAFE works directly on disassembled binary functions, does not require manual feature extraction, is computationally more efficient than existing solutions (i.e., it does not incur in the computational overhead of building or manipulating control flow graphs), and is more general as it works on stripped binaries and on multiple architectures. We report the results from a quantitative and qualitative analysis that show how SAFE provides a noticeable performance improvement with respect to previous solutions. Furthermore, we show how clusters of our embedding vectors are closely related to the semantic of the implemented algorithms, paving the way for further interesting applications (e.g. semantic-based binary function search).
Unsupervised Features Extraction for Binary Similarity Using Graph Embedding Neural Networks
Oct 23, 2018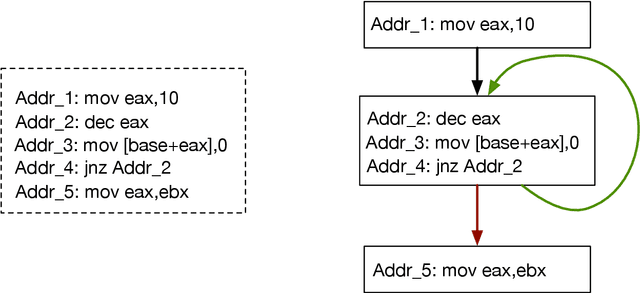
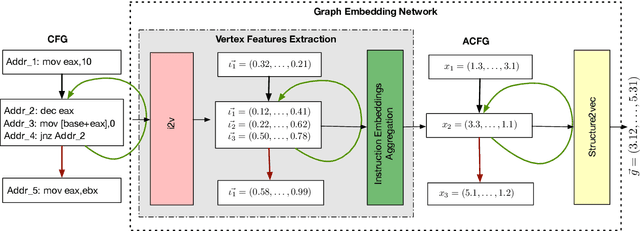
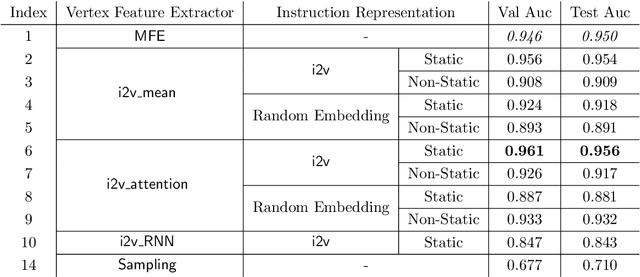
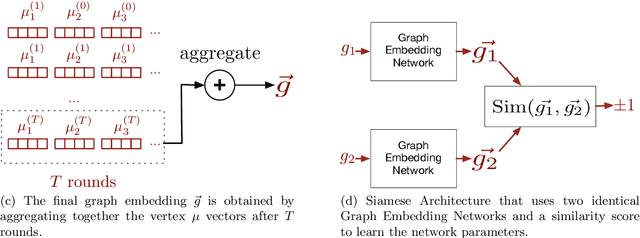
In this paper we consider the binary similarity problem that consists in determining if two binary functions are similar only considering their compiled form. This problem is know to be crucial in several application scenarios, such as copyright disputes, malware analysis, vulnerability detection, etc. The current state-of-the-art solutions in this field work by creating an embedding model that maps binary functions into vectors in $\mathbb{R}^{n}$. Such embedding model captures syntactic and semantic similarity between binaries, i.e., similar binary functions are mapped to points that are close in the vector space. This strategy has many advantages, one of them is the possibility to precompute embeddings of several binary functions, and then compare them with simple geometric operations (e.g., dot product). In [32] functions are first transformed in Annotated Control Flow Graphs (ACFGs) constituted by manually engineered features and then graphs are embedded into vectors using a deep neural network architecture. In this paper we propose and test several ways to compute annotated control flow graphs that use unsupervised approaches for feature learning, without incurring a human bias. Our methods are inspired after techniques used in the natural language processing community (e.g., we use word2vec to encode assembly instructions). We show that our approach is indeed successful, and it leads to better performance than previous state-of-the-art solutions. Furthermore, we report on a qualitative analysis of functions embeddings. We found interesting cases in which embeddings are clustered according to the semantic of the original binary function.