 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Pretraining for Heterogeneous Hypergraph Neural Networks
Nov 19, 2023



Recently, pretraining methods for the Graph Neural Networks (GNNs) have been successful at learning effective representations from unlabeled graph data. However, most of these methods rely on pairwise relations in the graph and do not capture the underling higher-order relations between entities. Hypergraphs are versatile and expressive structures that can effectively model higher-order relationships among entities in the data. Despite the efforts to adapt GNNs to hypergraphs (HyperGNN), there are currently no fully self-supervised pretraining methods for HyperGNN on heterogeneous hypergraphs. In this paper, we present SPHH, a novel self-supervised pretraining framework for heterogeneous HyperGNNs. Our method is able to effectively capture higher-order relations among entities in the data in a self-supervised manner. SPHH is consist of two self-supervised pretraining tasks that aim to simultaneously learn both local and global representations of the entities in the hypergraph by using informative representations derived from the hypergraph structure. Overall, our work presents a significant advancement in the field of self-supervised pretraining of HyperGNNs, and has the potential to improve the performance of various graph-based downstream tasks such as node classification and link prediction tasks which are mapped to hypergraph configuration. Our experiments on two real-world benchmarks using four different HyperGNN models show that our proposed SPHH framework consistently outperforms state-of-the-art baselines in various downstream tasks. The results demonstrate that SPHH is able to improve the performance of various HyperGNN models in various downstream tasks, regardless of their architecture or complexity, which highlights the robustness of our framework.
Is Meta-Learning the Right Approach for the Cold-Start Problem in Recommender Systems?
Aug 16, 2023



Recommender systems have become fundamental building blocks of modern online products and services, and have a substantial impact on user experience. In the past few years, deep learning methods have attracted a lot of research, and are now heavily used in modern real-world recommender systems. Nevertheless, dealing with recommendations in the cold-start setting, e.g., when a user has done limited interactions in the system, is a problem that remains far from solved. Meta-learning techniques, and in particular optimization-based meta-learning, have recently become the most popular approaches in the academic research literature for tackling the cold-start problem in deep learning models for recommender systems. However, current meta-learning approaches are not practical for real-world recommender systems, which have billions of users and items, and strict latency requirements. In this paper we show that it is possible to obtaining similar, or higher, performance on commonly used benchmarks for the cold-start problem without using meta-learning techniques. In more detail, we show that, when tuned correctly, standard and widely adopted deep learning models perform just as well as newer meta-learning models. We further show that an extremely simple modular approach using common representation learning techniques, can perform comparably to meta-learning techniques specifically designed for the cold-start setting while being much more easily deployable in real-world applications.
KILT: a Benchmark for Knowledge Intensive Language Tasks
Sep 04, 2020
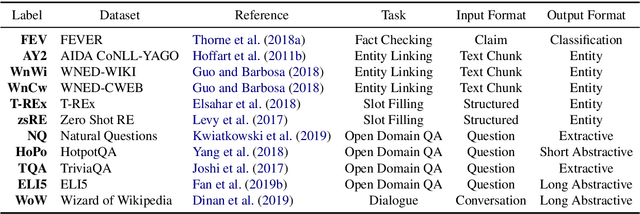
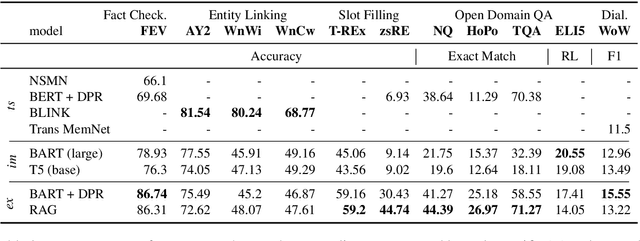
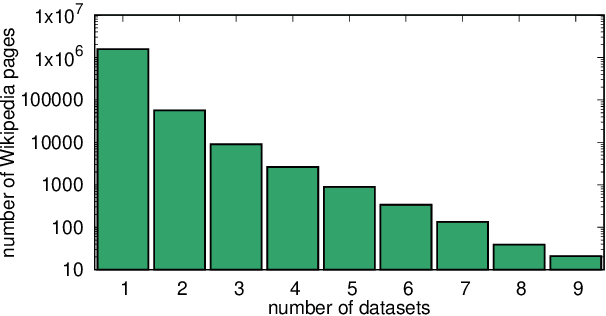
Challenging problems such as open-domain question answering, fact checking, slot filling and entity linking require access to large, external knowledge sources. While some models do well on individual tasks, developing general models is difficult as each task might require computationally expensive indexing of custom knowledge sources, in addition to dedicated infrastructure. To catalyze research on models that condition on specific information in large textual resources, we present a benchmark for knowledge-intensive language tasks (KILT). All tasks in KILT are grounded in the same snapshot of Wikipedia, reducing engineering turnaround through the re-use of components, as well as accelerating research into task-agnostic memory architectures. We test both task-specific and general baselines, evaluating downstream performance in addition to the ability of the models to provide provenance. We find that a shared dense vector index coupled with a seq2seq model is a strong baseline, outperforming more tailor-made approaches for fact checking, open-domain question answering and dialogue, and yielding competitive results on entity linking and slot filling, by generating disambiguated text. KILT data and code are available at https://github.com/facebookresearch/KILT.
Concept Matching for Low-Resource Classification
Jun 01, 2020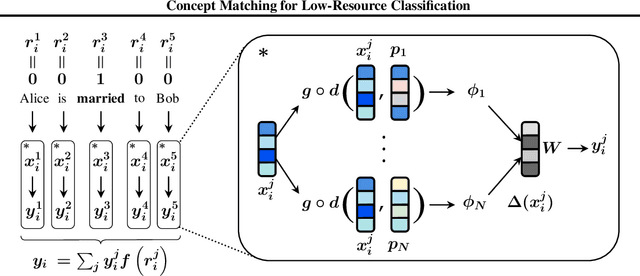


We propose a model to tackle classification tasks in the presence of very little training data. To this aim, we approximate the notion of exact match with a theoretically sound mechanism that computes a probability of matching in the input space. Importantly, the model learns to focus on elements of the input that are relevant for the task at hand; by leveraging highlighted portions of the training data, an error boosting technique guides the learning process. In practice, it increases the error associated with relevant parts of the input by a given factor. Remarkable results on text classification tasks confirm the benefits of the proposed approach in both balanced and unbalanced cases, thus being of practical use when labeling new examples is expensive. In addition, by inspecting its weights, it is often possible to gather insights on what the model has learned.
How Decoding Strategies Affect the Verifiability of Generated Text
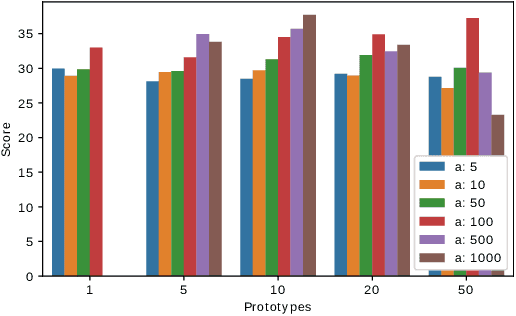
Nov 09, 2019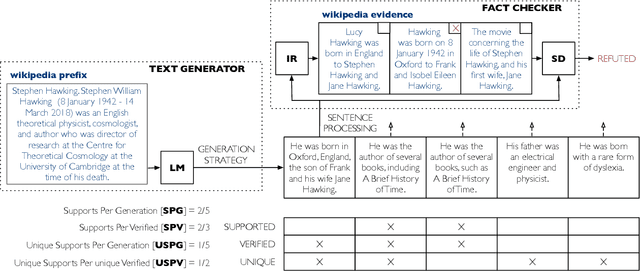
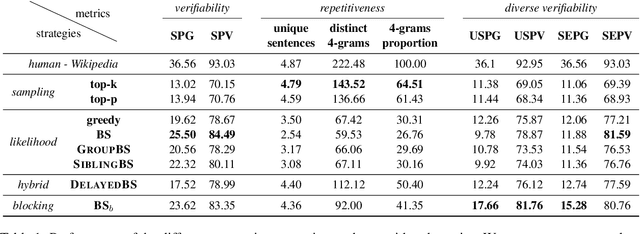
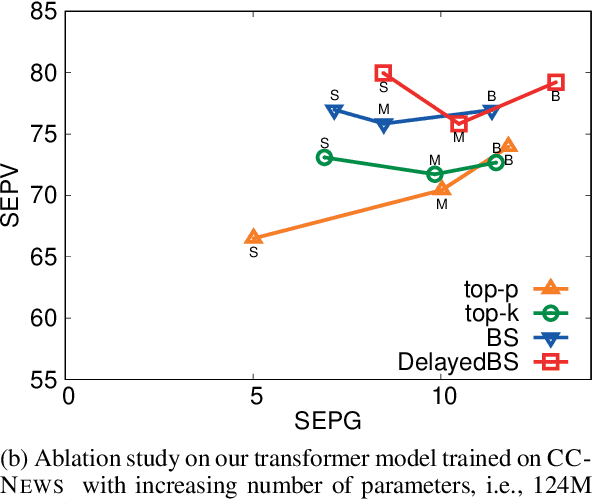

Language models are of considerable importance. They are used for pretraining, finetuning, and rescoring in downstream applications, and as is as a test-bed and benchmark for progress in natural language understanding. One fundamental question regards the way we should generate text from a language model. It is well known that different decoding strategies can have dramatic impact on the quality of the generated text and using the most likely sequence under the model distribution, e.g., via beam search, generally leads to degenerate and repetitive outputs. While generation strategies such as top-k and nucleus sampling lead to more natural and less repetitive generations, the true cost of avoiding the highest scoring solution is hard to quantify. In this paper, we argue that verifiability, i.e., the consistency of the generated text with factual knowledge, is a suitable metric for measuring this cost. We use an automatic fact-checking system to calculate new metrics as a function of the number of supported claims per sentence and find that sampling-based generation strategies, such as top-k, indeed lead to less verifiable text. This finding holds across various dimensions, such as model size, training data size and parameters of the generation strategy. Based on this finding, we introduce a simple and effective generation strategy for producing non-repetitive and more verifiable (in comparison to other methods) text.