 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Pretraining for Heterogeneous Hypergraph Neural Networks
Nov 19, 2023



Recently, pretraining methods for the Graph Neural Networks (GNNs) have been successful at learning effective representations from unlabeled graph data. However, most of these methods rely on pairwise relations in the graph and do not capture the underling higher-order relations between entities. Hypergraphs are versatile and expressive structures that can effectively model higher-order relationships among entities in the data. Despite the efforts to adapt GNNs to hypergraphs (HyperGNN), there are currently no fully self-supervised pretraining methods for HyperGNN on heterogeneous hypergraphs. In this paper, we present SPHH, a novel self-supervised pretraining framework for heterogeneous HyperGNNs. Our method is able to effectively capture higher-order relations among entities in the data in a self-supervised manner. SPHH is consist of two self-supervised pretraining tasks that aim to simultaneously learn both local and global representations of the entities in the hypergraph by using informative representations derived from the hypergraph structure. Overall, our work presents a significant advancement in the field of self-supervised pretraining of HyperGNNs, and has the potential to improve the performance of various graph-based downstream tasks such as node classification and link prediction tasks which are mapped to hypergraph configuration. Our experiments on two real-world benchmarks using four different HyperGNN models show that our proposed SPHH framework consistently outperforms state-of-the-art baselines in various downstream tasks. The results demonstrate that SPHH is able to improve the performance of various HyperGNN models in various downstream tasks, regardless of their architecture or complexity, which highlights the robustness of our framework.
Graph-based Modeling of Online Communities for Fake News Detection
Sep 14, 2020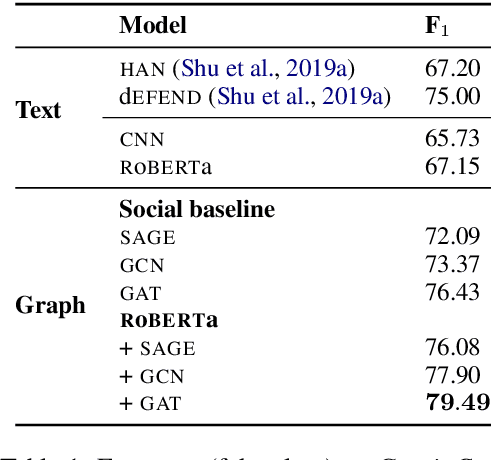
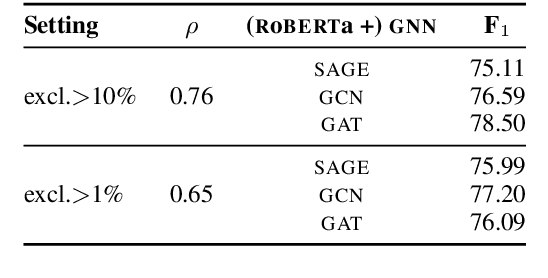
Over the past few years, there has been a substantial effort towards automated detection of fake news on social media platforms. Existing research has modeled the structure, style, content, and patterns in dissemination of online posts, as well as the demographic traits of users who interact with them. However, no attention has been directed towards modeling the properties of online communities that interact with the posts. In this work, we propose a novel social context-aware fake news detection framework, SAFER, based on graph neural networks (GNNs). The proposed framework aggregates information with respect to: 1) the nature of the content disseminated, 2) content-sharing behavior of users, and 3) the social network of those users. We furthermore perform a systematic comparison of several GNN models for this task and introduce novel methods based on relational and hyperbolic GNNs, which have not been previously used for user or community modeling within NLP. We empirically demonstrate that our framework yields significant improvements over existing text-based techniques and achieves state-of-the-art results on fake news datasets from two different domains.
HyperGCN: Hypergraph Convolutional Networks for Semi-Supervised Classification
Sep 07, 2018
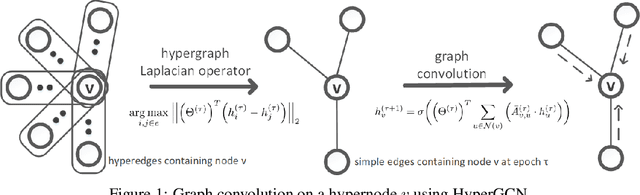

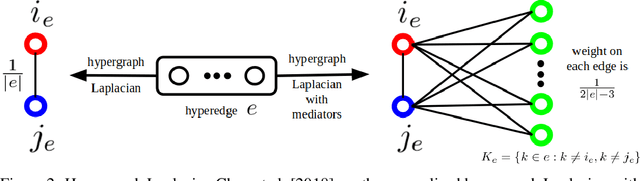
Graph-based semi-supervised learning (SSL) is an important learning problem where the goal is to assign labels to initially unlabeled nodes in a graph. Graph Convolutional Networks (GCNs) have recently been shown to be effective for graph-based SSL problems. GCNs inherently assume existence of pairwise relationships in the graph-structured data. However, in many real-world problems, relationships go beyond pairwise connections and hence are more complex. Hypergraphs provide a natural modeling tool to capture such complex relationships. In this work, we explore the use of GCNs for hypergraph-based SSL. In particular, we propose HyperGCN, an SSL method which uses a layer-wise propagation rule for convolutional neural networks operating directly on hypergraphs. To the best of our knowledge, this is the first principled adaptation of GCNs to hypergraphs. HyperGCN is able to encode both the hypergraph structure and hypernode features in an effective manner. Through detailed experimentation, we demonstrate HyperGCN's effectiveness at hypergraph-based SSL.
Inductive Framework for Multi-Aspect Streaming Tensor Completion with Side Information
Sep 01, 2018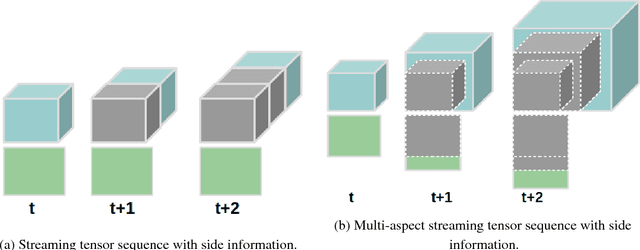

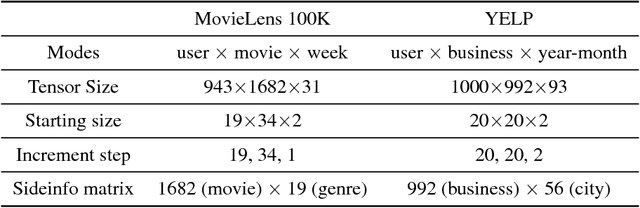

Low rank tensor completion is a well studied problem and has applications in various fields. However, in many real world applications the data is dynamic, i.e., new data arrives at different time intervals. As a result, the tensors used to represent the data grow in size. Besides the tensors, in many real world scenarios, side information is also available in the form of matrices which also grow in size with time. The problem of predicting missing values in the dynamically growing tensor is called dynamic tensor completion. Most of the previous work in dynamic tensor completion make an assumption that the tensor grows only in one mode. To the best of our Knowledge, there is no previous work which incorporates side information with dynamic tensor completion. We bridge this gap in this paper by proposing a dynamic tensor completion framework called Side Information infused Incremental Tensor Analysis (SIITA), which incorporates side information and works for general incremental tensors. We also show how non-negative constraints can be incorporated with SIITA, which is essential for mining interpretable latent clusters. We carry out extensive experiments on multiple real world datasets to demonstrate the effectiveness of SIITA in various different settings.
Lovasz Convolutional Networks
May 29, 2018
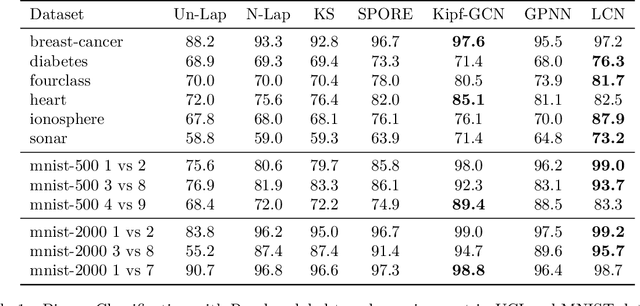
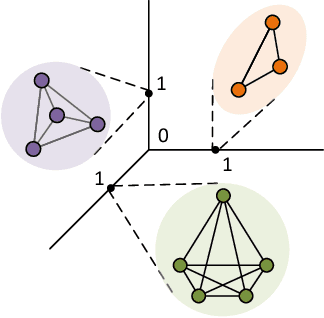

Semi-supervised learning on graph structured data has received significant attention with the recent introduction of graph convolution networks (GCN). While traditional methods have focused on optimizing a loss augmented with Laplacian regularization framework, GCNs perform an implicit Laplacian type regularization to capture local graph structure. In this work, we propose Lovasz convolutional network (LCNs) which are capable of incorporating global graph properties. LCNs achieve this by utilizing Lovasz's orthonormal embeddings of the nodes. We analyse local and global properties of graphs and demonstrate settings where LCNs tend to work better than GCNs. We validate the proposed method on standard random graph models such as stochastic block models (SBM) and certain community structure based graphs where LCNs outperform GCNs and learn more intuitive embeddings. We also perform extensive binary and multi-class classification experiments on real world datasets to demonstrate LCN's effectiveness. In addition to simple graphs, we also demonstrate the use of LCNs on hypergraphs by identifying settings where they are expected to work better than GCNs.
Higher-order Relation Schema Induction using Tensor Factorization with Back-off and Aggregation
May 29, 2018
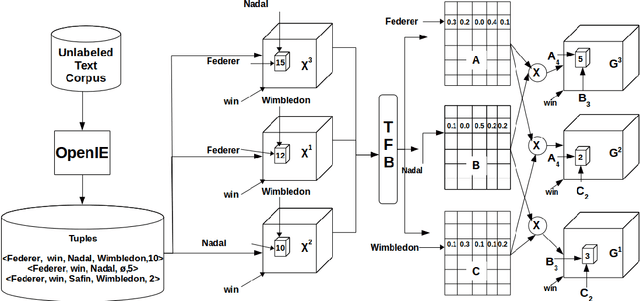
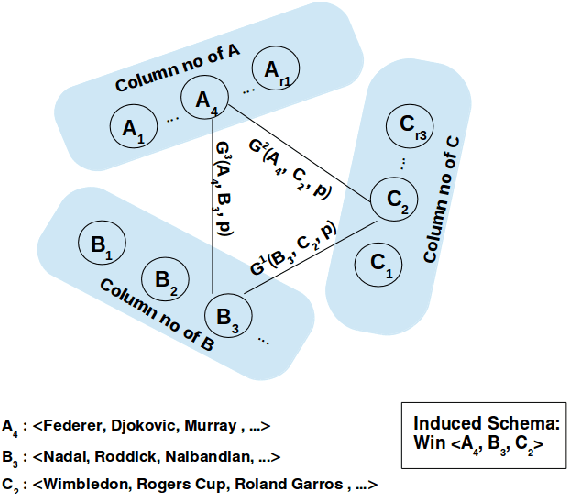

Relation Schema Induction (RSI) is the problem of identifying type signatures of arguments of relations from unlabeled text. Most of the previous work in this area have focused only on binary RSI, i.e., inducing only the subject and object type signatures per relation. However, in practice, many relations are high-order, i.e., they have more than two arguments and inducing type signatures of all arguments is necessary. For example, in the sports domain, inducing a schema win(WinningPlayer, OpponentPlayer, Tournament, Location) is more informative than inducing just win(WinningPlayer, OpponentPlayer). We refer to this problem as Higher-order Relation Schema Induction (HRSI). In this paper, we propose Tensor Factorization with Back-off and Aggregation (TFBA), a novel framework for the HRSI problem. To the best of our knowledge, this is the first attempt at inducing higher-order relation schemata from unlabeled text. Using the experimental analysis on three real world datasets, we show how TFBA helps in dealing with sparsity and induce higher order schemata.
A Riemannian approach to trace norm regularized low-rank tensor completion
May 25, 2018

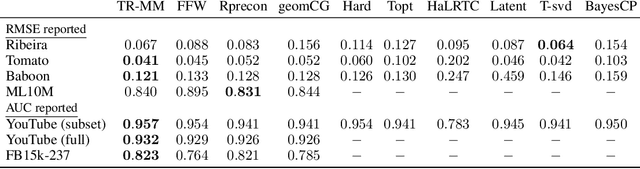
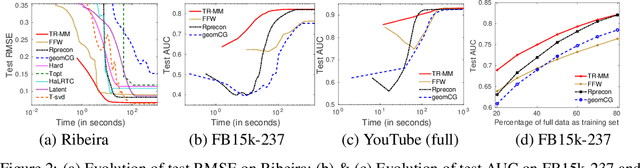
One of the popular approaches for low-rank tensor completion is to use the {\it latent trace norm} regularization. However, most existing works in this direction learn a sparse combination of tensors. In this work, we fill this gap by proposing a variant of the latent trace norm that helps in learning a non-sparse combination of tensors. We develop a dual framework for solving the proposed low-rank tensor completion problem. In this framework, we first show a novel characterization of the solution space with an interesting factorization of the optimal solution. This allows to propose two scalable optimization formulations. The problems are shown to lie on a Cartesian product of Riemannian spectrahedron manifolds. We exploit the versatile Riemannian optimization framework for proposing computationally efficient trust region algorithms. The experiments illustrate the efficacy of the proposed algorithms on several real-world datasets across applications.
Relation Schema Induction using Tensor Factorization with Side Information
Nov 16, 2016


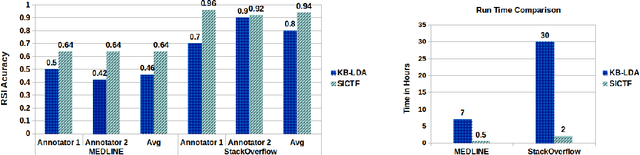
Given a set of documents from a specific domain (e.g., medical research journals), how do we automatically build a Knowledge Graph (KG) for that domain? Automatic identification of relations and their schemas, i.e., type signature of arguments of relations (e.g., undergo(Patient, Surgery)), is an important first step towards this goal. We refer to this problem as Relation Schema Induction (RSI). In this paper, we propose Schema Induction using Coupled Tensor Factorization (SICTF), a novel tensor factorization method for relation schema induction. SICTF factorizes Open Information Extraction (OpenIE) triples extracted from a domain corpus along with additional side information in a principled way to induce relation schemas. To the best of our knowledge, this is the first application of tensor factorization for the RSI problem. Through extensive experiments on multiple real-world datasets, we find that SICTF is not only more accurate than state-of-the-art baselines, but also significantly faster (about 14x faster).