 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Fact-Checking in Dialogue: Are Specialized Models Needed?
Nov 14, 2023Prior research has shown that typical fact-checking models for stand-alone claims struggle with claims made in dialogues. As a solution, fine-tuning these models on labelled dialogue data has been proposed. However, creating separate models for each use case is impractical, and we show that fine-tuning models for dialogue results in poor performance on typical fact-checking. To overcome this challenge, we present techniques that allow us to use the same models for both dialogue and typical fact-checking. These mainly focus on retrieval adaptation and transforming conversational inputs so that they can be accurately predicted by models trained on stand-alone claims. We demonstrate that a typical fact-checking model incorporating these techniques is competitive with state-of-the-art models fine-tuned for dialogue, while maintaining its accuracy on stand-alone claims.
TimelineQA: A Benchmark for Question Answering over Timelines
Jun 01, 2023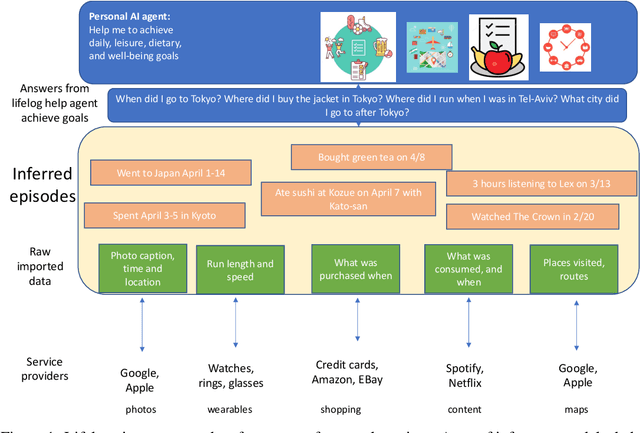



Lifelogs are descriptions of experiences that a person had during their life. Lifelogs are created by fusing data from the multitude of digital services, such as online photos, maps, shopping and content streaming services. Question answering over lifelogs can offer personal assistants a critical resource when they try to provide advice in context. However, obtaining answers to questions over lifelogs is beyond the current state of the art of question answering techniques for a variety of reasons, the most pronounced of which is that lifelogs combine free text with some degree of structure such as temporal and geographical information. We create and publicly release TimelineQA1, a benchmark for accelerating progress on querying lifelogs. TimelineQA generates lifelogs of imaginary people. The episodes in the lifelog range from major life episodes such as high school graduation to those that occur on a daily basis such as going for a run. We describe a set of experiments on TimelineQA with several state-of-the-art QA models. Our experiments reveal that for atomic queries, an extractive QA system significantly out-performs a state-of-the-art retrieval-augmented QA system. For multi-hop queries involving aggregates, we show that the best result is obtained with a state-of-the-art table QA technique, assuming the ground truth set of episodes for deriving the answer is available.
RQUGE: Reference-Free Metric for Evaluating Question Generation by Answering the Question
Nov 09, 2022Existing metrics for evaluating the quality of automatically generated questions such as BLEU, ROUGE, BERTScore, and BLEURT compare the reference and predicted questions, providing a high score when there is a considerable lexical overlap or semantic similarity between the candidate and the reference questions. This approach has two major shortcomings. First, we need expensive human-provided reference questions. Second, it penalises valid questions that may not have high lexical or semantic similarity to the reference questions. In this paper, we propose a new metric, RQUGE, based on the answerability of the candidate question given the context. The metric consists of a question-answering and a span scorer module, in which we use pre-trained models from the existing literature, and therefore, our metric can be used without further training. We show that RQUGE has a higher correlation with human judgment without relying on the reference question. RQUGE is shown to be significantly more robust to several adversarial corruptions. Additionally, we illustrate that we can significantly improve the performance of QA models on out-of-domain datasets by fine-tuning on the synthetic data generated by a question generation model and re-ranked by RQUGE.
Policy Compliance Detection via Expression Tree Inference
May 24, 2022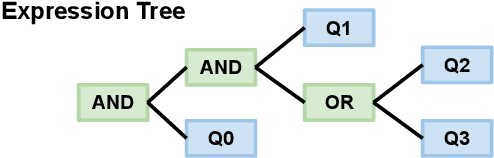

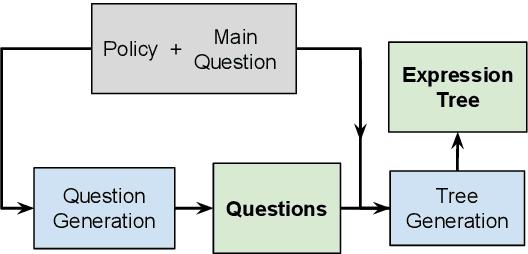
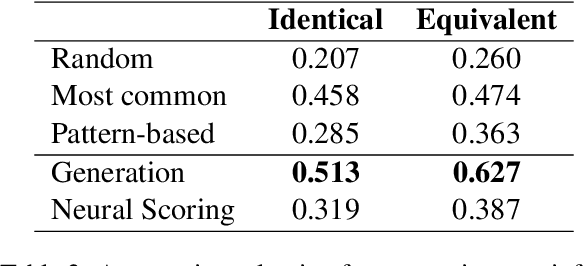
Policy Compliance Detection (PCD) is a task we encounter when reasoning over texts, e.g. legal frameworks. Previous work to address PCD relies heavily on modeling the task as a special case of Recognizing Textual Entailment. Entailment is applicable to the problem of PCD, however viewing the policy as a single proposition, as opposed to multiple interlinked propositions, yields poor performance and lacks explainability. To address this challenge, more recent proposals for PCD have argued for decomposing policies into expression trees consisting of questions connected with logic operators. Question answering is used to obtain answers to these questions with respect to a scenario. Finally, the expression tree is evaluated in order to arrive at an overall solution. However, this work assumes expression trees are provided by experts, thus limiting its applicability to new policies. In this work, we learn how to infer expression trees automatically from policy texts. We ensure the validity of the inferred trees by introducing constrained decoding using a finite state automaton to ensure the generation of valid trees. We determine through automatic evaluation that 63% of the expression trees generated by our constrained generation model are logically equivalent to gold trees. Human evaluation shows that 88% of trees generated by our model are correct.
PERFECT: Prompt-free and Efficient Few-shot Learning with Language Models
Apr 03, 2022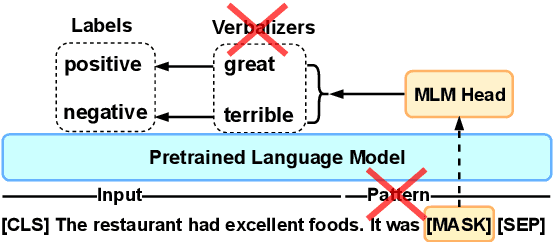
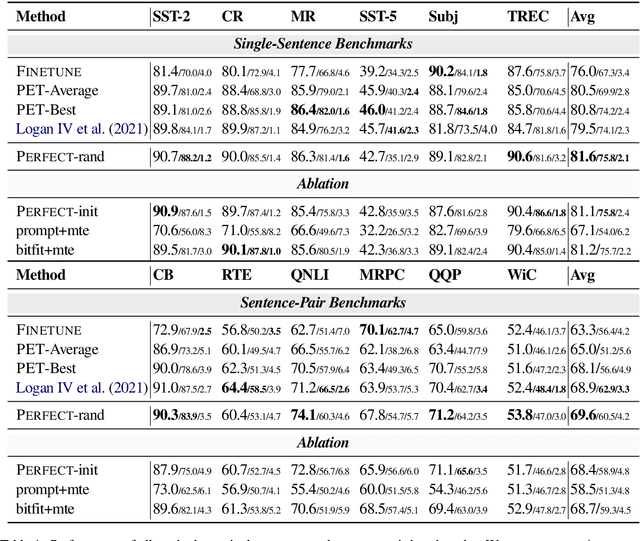
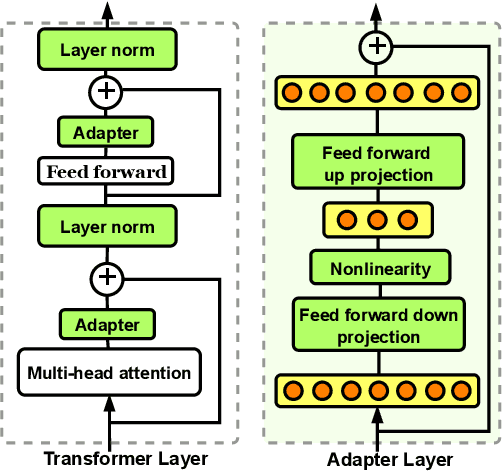
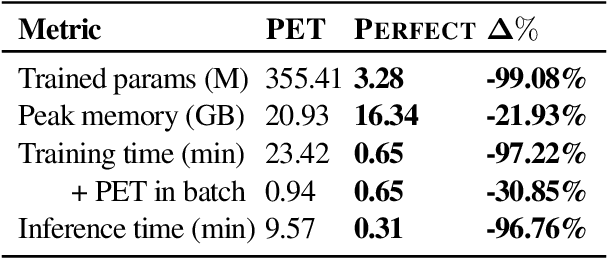
Current methods for few-shot fine-tuning of pretrained masked language models (PLMs) require carefully engineered prompts and verbalizers for each new task to convert examples into a cloze-format that the PLM can score. In this work, we propose PERFECT, a simple and efficient method for few-shot fine-tuning of PLMs without relying on any such handcrafting, which is highly effective given as few as 32 data points. PERFECT makes two key design choices: First, we show that manually engineered task prompts can be replaced with task-specific adapters that enable sample-efficient fine-tuning and reduce memory and storage costs by roughly factors of 5 and 100, respectively. Second, instead of using handcrafted verbalizers, we learn new multi-token label embeddings during fine-tuning, which are not tied to the model vocabulary and which allow us to avoid complex auto-regressive decoding. These embeddings are not only learnable from limited data but also enable nearly 100x faster training and inference. Experiments on a wide range of few-shot NLP tasks demonstrate that PERFECT, while being simple and efficient, also outperforms existing state-of-the-art few-shot learning methods. Our code is publicly available at https://github.com/rabeehk/perfect.
Cross-Policy Compliance Detection via Question Answering
Sep 08, 2021


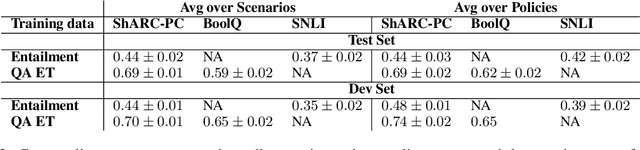
Policy compliance detection is the task of ensuring that a scenario conforms to a policy (e.g. a claim is valid according to government rules or a post in an online platform conforms to community guidelines). This task has been previously instantiated as a form of textual entailment, which results in poor accuracy due to the complexity of the policies. In this paper we propose to address policy compliance detection via decomposing it into question answering, where questions check whether the conditions stated in the policy apply to the scenario, and an expression tree combines the answers to obtain the label. Despite the initial upfront annotation cost, we demonstrate that this approach results in better accuracy, especially in the cross-policy setup where the policies during testing are unseen in training. In addition, it allows us to use existing question answering models pre-trained on existing large datasets. Finally, it explicitly identifies the information missing from a scenario in case policy compliance cannot be determined. We conduct our experiments using a recent dataset consisting of government policies, which we augment with expert annotations and find that the cost of annotating question answering decomposition is largely offset by improved inter-annotator agreement and speed.
Database Reasoning Over Text
Jun 02, 2021

Neural models have shown impressive performance gains in answering queries from natural language text. However, existing works are unable to support database queries, such as "List/Count all female athletes who were born in 20th century", which require reasoning over sets of relevant facts with operations such as join, filtering and aggregation. We show that while state-of-the-art transformer models perform very well for small databases, they exhibit limitations in processing noisy data, numerical operations, and queries that aggregate facts. We propose a modular architecture to answer these database-style queries over multiple spans from text and aggregating these at scale. We evaluate the architecture using WikiNLDB, a novel dataset for exploring such queries. Our architecture scales to databases containing thousands of facts whereas contemporary models are limited by how many facts can be encoded. In direct comparison on small databases, our approach increases overall answer accuracy from 85% to 90%. On larger databases, our approach retains its accuracy whereas transformer baselines could not encode the context.
Generating Fact Checking Briefs
Nov 10, 2020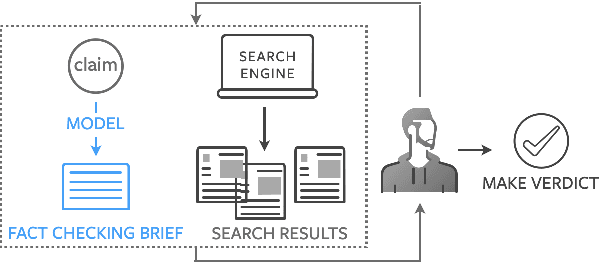
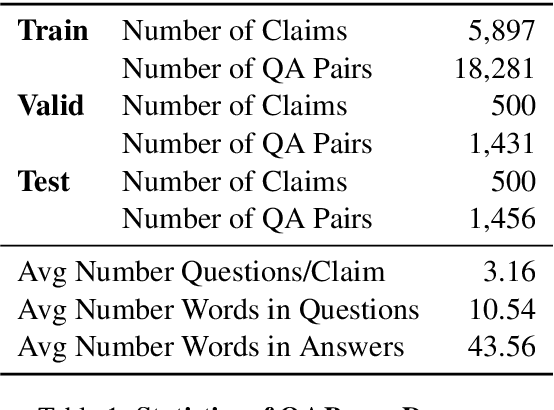

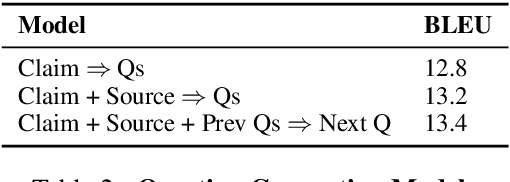
Fact checking at scale is difficult -- while the number of active fact checking websites is growing, it remains too small for the needs of the contemporary media ecosystem. However, despite good intentions, contributions from volunteers are often error-prone, and thus in practice restricted to claim detection. We investigate how to increase the accuracy and efficiency of fact checking by providing information about the claim before performing the check, in the form of natural language briefs. We investigate passage-based briefs, containing a relevant passage from Wikipedia, entity-centric ones consisting of Wikipedia pages of mentioned entities, and Question-Answering Briefs, with questions decomposing the claim, and their answers. To produce QABriefs, we develop QABriefer, a model that generates a set of questions conditioned on the claim, searches the web for evidence, and generates answers. To train its components, we introduce QABriefDataset which we collected via crowdsourcing. We show that fact checking with briefs -- in particular QABriefs -- increases the accuracy of crowdworkers by 10% while slightly decreasing the time taken. For volunteer (unpaid) fact checkers, QABriefs slightly increase accuracy and reduce the time required by around 20%.
Neural Databases
Oct 14, 2020
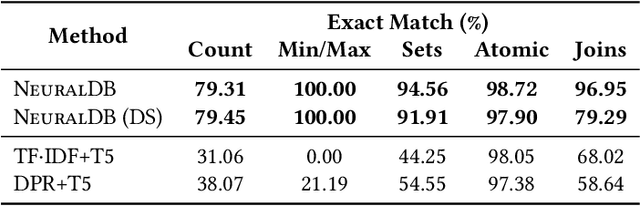
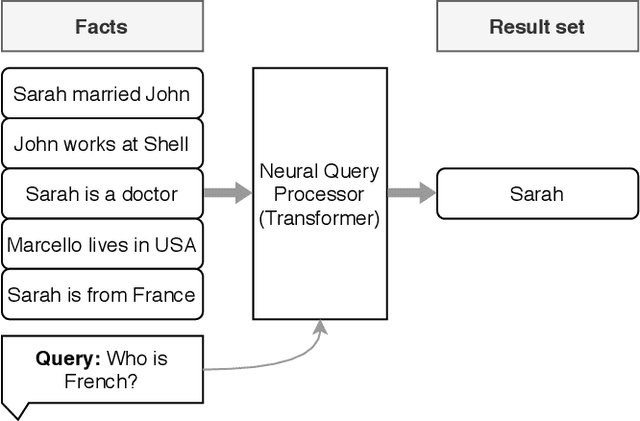

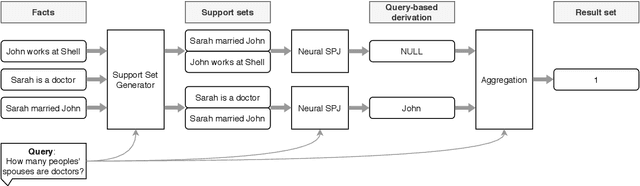
In recent years, neural networks have shown impressive performance gains on long-standing AI problems, and in particular, answering queries from natural language text. These advances raise the question of whether they can be extended to a point where we can relax the fundamental assumption of database management, namely, that our data is represented as fields of a pre-defined schema. This paper presents a first step in answering that question. We describe NeuralDB, a database system with no pre-defined schema, in which updates and queries are given in natural language. We develop query processing techniques that build on the primitives offered by the state of the art Natural Language Processing methods. We begin by demonstrating that at the core, recent NLP transformers, powered by pre-trained language models, can answer select-project-join queries if they are given the exact set of relevant facts. However, they cannot scale to non-trivial databases and cannot perform aggregation queries. Based on these findings, we describe a NeuralDB architecture that runs multiple Neural SPJ operators in parallel, each with a set of database sentences that can produce one of the answers to the query. The result of these operators is fed to an aggregation operator if needed. We describe an algorithm that learns how to create the appropriate sets of facts to be fed into each of the Neural SPJ operators. Importantly, this algorithm can be trained by the Neural SPJ operator itself. We experimentally validate the accuracy of NeuralDB and its components, showing that we can answer queries over thousands of sentences with very high accuracy.
Preserving Integrity in Online Social Networks
Sep 25, 2020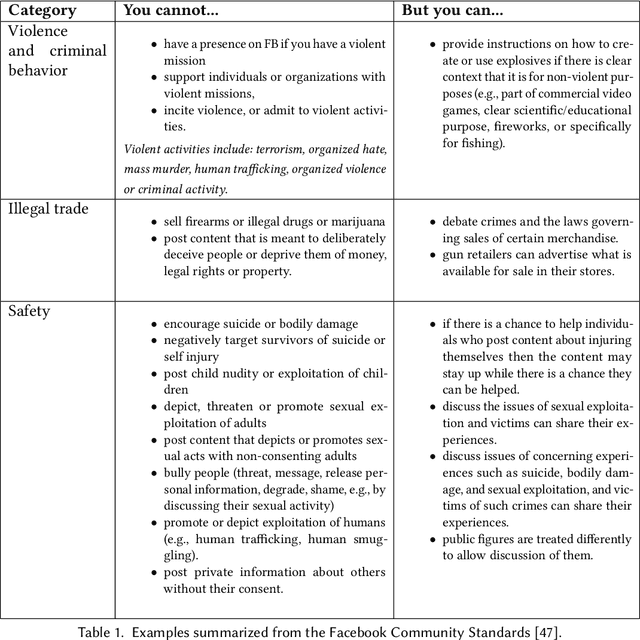
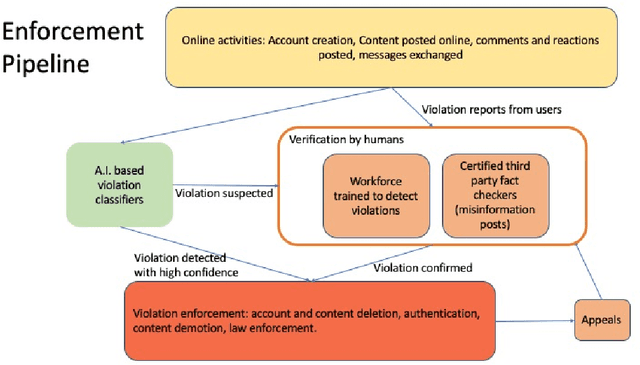
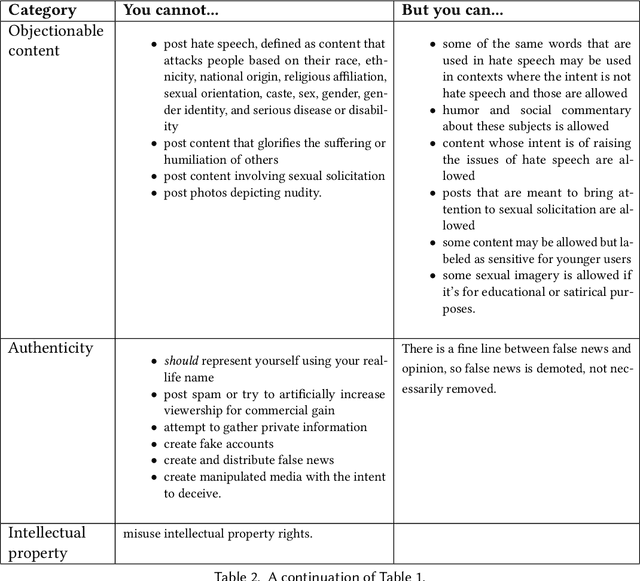
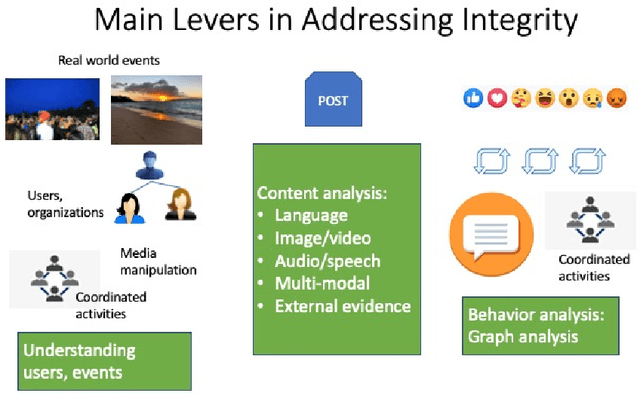
Online social networks provide a platform for sharing information and free expression. However, these networks are also used for malicious purposes, such as distributing misinformation and hate speech, selling illegal drugs, and coordinating sex trafficking or child exploitation. This paper surveys the state of the art in keeping online platforms and their users safe from such harm, also known as the problem of preserving integrity. This survey comes from the perspective of having to combat a broad spectrum of integrity violations at Facebook. We highlight the techniques that have been proven useful in practice and that deserve additional attention from the academic community. Instead of discussing the many individual violation types, we identify key aspects of the social-media eco-system, each of which is common to a wide variety violation types. Furthermore, each of these components represents an area for research and development, and the innovations that are found can be applied widely.