 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond RAG: Task-Aware KV Cache Compression for Comprehensive Knowledge Reasoning
Mar 06, 2025Incorporating external knowledge in large language models (LLMs) enhances their utility across diverse applications, but existing methods have trade-offs. Retrieval-Augmented Generation (RAG) fetches evidence via similarity search, but key information may fall outside top ranked results. Long-context models can process multiple documents but are computationally expensive and limited by context window size. Inspired by students condensing study material for open-book exams, we propose task-aware key-value (KV) cache compression, which compresses external knowledge in a zero- or few-shot setup. This enables LLMs to reason efficiently over a compacted representation of all relevant information. Experiments show our approach outperforms both RAG and task-agnostic compression methods. On LongBench v2, it improves accuracy by up to 7 absolute points over RAG with a 30x compression rate, while reducing inference latency from 0.43s to 0.16s. A synthetic dataset highlights that RAG performs well when sparse evidence suffices, whereas task-aware compression is superior for broad knowledge tasks.
Lost in the Middle: How Language Models Use Long Contexts
Jul 31, 2023While recent language models have the ability to take long contexts as input, relatively little is known about how well they use longer context. We analyze language model performance on two tasks that require identifying relevant information within their input contexts: multi-document question answering and key-value retrieval. We find that performance is often highest when relevant information occurs at the beginning or end of the input context, and significantly degrades when models must access relevant information in the middle of long contexts. Furthermore, performance substantially decreases as the input context grows longer, even for explicitly long-context models. Our analysis provides a better understanding of how language models use their input context and provides new evaluation protocols for future long-context models.
Can discrete information extraction prompts generalize across language models?
Mar 07, 2023We study whether automatically-induced prompts that effectively extract information from a language model can also be used, out-of-the-box, to probe other language models for the same information. After confirming that discrete prompts induced with the AutoPrompt algorithm outperform manual and semi-manual prompts on the slot-filling task, we demonstrate a drop in performance for AutoPrompt prompts learned on a model and tested on another. We introduce a way to induce prompts by mixing language models at training time that results in prompts that generalize well across models. We conduct an extensive analysis of the induced prompts, finding that the more general prompts include a larger proportion of existing English words and have a less order-dependent and more uniform distribution of information across their component tokens. Our work provides preliminary evidence that it's possible to generate discrete prompts that can be induced once and used with a number of different models, and gives insights on the properties characterizing such prompts.
EditEval: An Instruction-Based Benchmark for Text Improvements
Sep 27, 2022
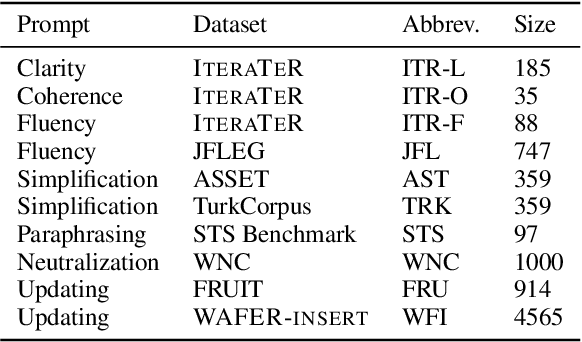
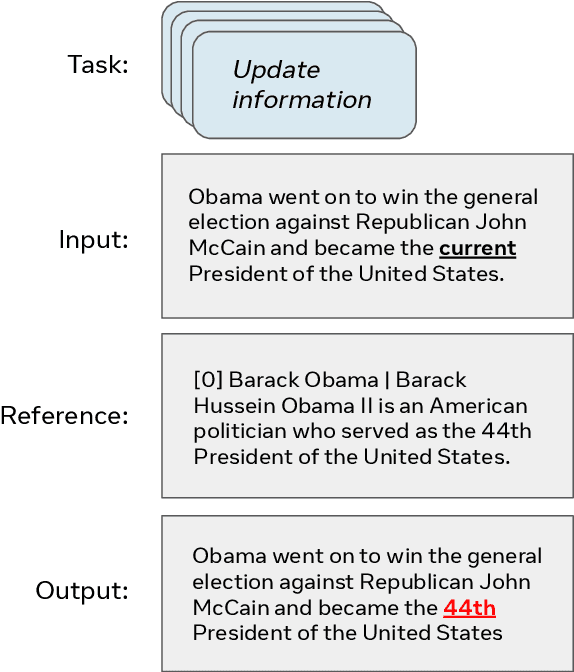
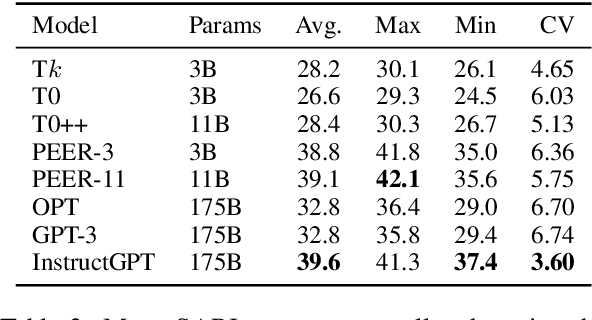
Evaluation of text generation to date has primarily focused on content created sequentially, rather than improvements on a piece of text. Writing, however, is naturally an iterative and incremental process that requires expertise in different modular skills such as fixing outdated information or making the style more consistent. Even so, comprehensive evaluation of a model's capacity to perform these skills and the ability to edit remains sparse. This work presents EditEval: An instruction-based, benchmark and evaluation suite that leverages high-quality existing and new datasets for automatic evaluation of editing capabilities such as making text more cohesive and paraphrasing. We evaluate several pre-trained models, which shows that InstructGPT and PEER perform the best, but that most baselines fall below the supervised SOTA, particularly when neutralizing and updating information. Our analysis also shows that commonly used metrics for editing tasks do not always correlate well, and that optimization for prompts with the highest performance does not necessarily entail the strongest robustness to different models. Through the release of this benchmark and a publicly available leaderboard challenge, we hope to unlock future research in developing models capable of iterative and more controllable editing.
Entity Tagging: Extracting Entities in Text Without Mention Supervision
Sep 13, 2022
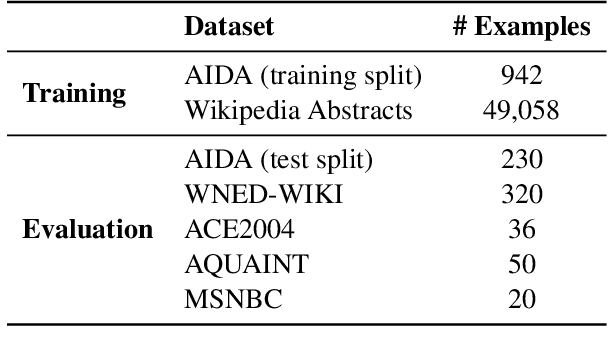

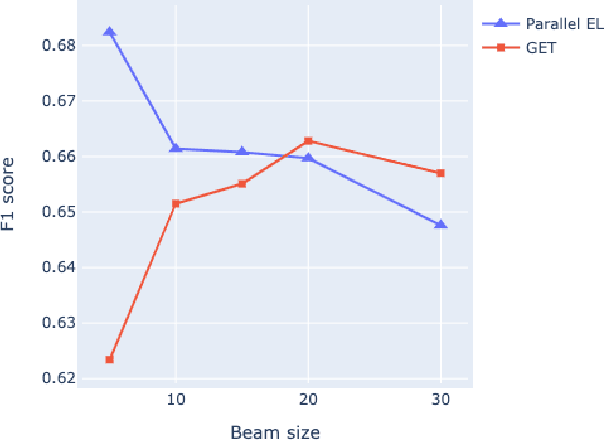
Detection and disambiguation of all entities in text is a crucial task for a wide range of applications. The typical formulation of the problem involves two stages: detect mention boundaries and link all mentions to a knowledge base. For a long time, mention detection has been considered as a necessary step for extracting all entities in a piece of text, even if the information about mention spans is ignored by some downstream applications that merely focus on the set of extracted entities. In this paper we show that, in such cases, detection of mention boundaries does not bring any considerable performance gain in extracting entities, and therefore can be skipped. To conduct our analysis, we propose an "Entity Tagging" formulation of the problem, where models are evaluated purely on the set of extracted entities without considering mentions. We compare a state-of-the-art mention-aware entity linking solution against GET, a mention-agnostic sequence-to-sequence model that simply outputs a list of disambiguated entities given an input context. We find that these models achieve comparable performance when trained both on a fully and partially annotated dataset across multiple benchmarks, demonstrating that GET can extract disambiguated entities with strong performance without explicit mention boundaries supervision.
PEER: A Collaborative Language Model
Aug 24, 2022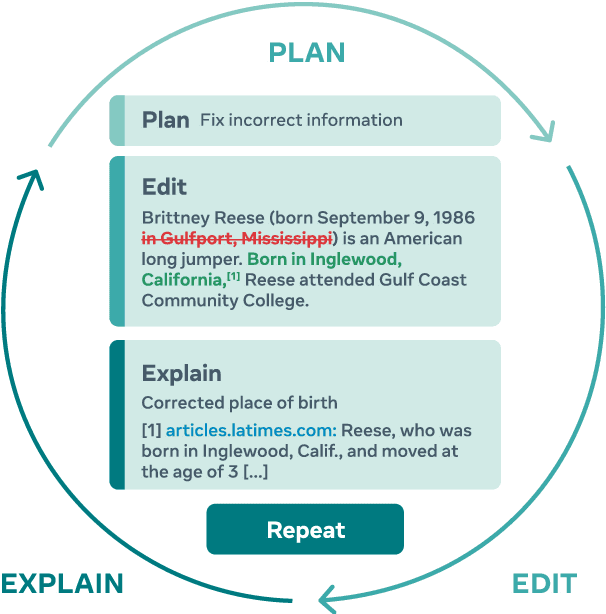
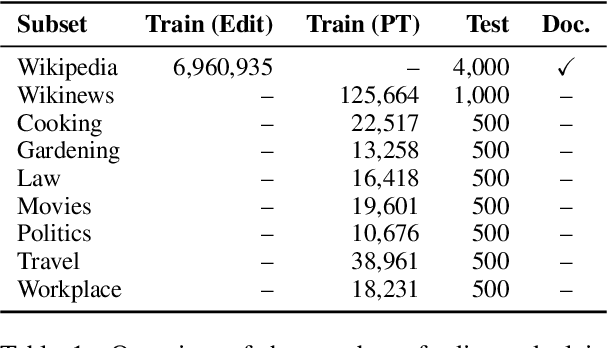
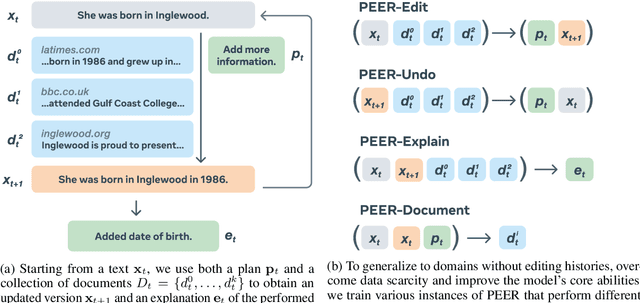
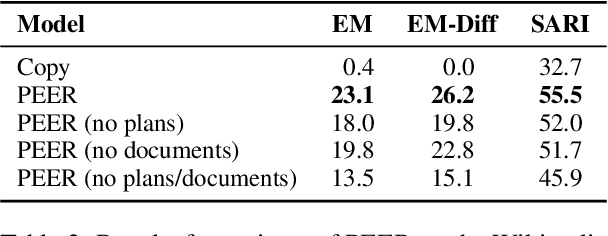
Textual content is often the output of a collaborative writing process: We start with an initial draft, ask for suggestions, and repeatedly make changes. Agnostic of this process, today's language models are trained to generate only the final result. As a consequence, they lack several abilities crucial for collaborative writing: They are unable to update existing texts, difficult to control and incapable of verbally planning or explaining their actions. To address these shortcomings, we introduce PEER, a collaborative language model that is trained to imitate the entire writing process itself: PEER can write drafts, add suggestions, propose edits and provide explanations for its actions. Crucially, we train multiple instances of PEER able to infill various parts of the writing process, enabling the use of self-training techniques for increasing the quality, amount and diversity of training data. This unlocks PEER's full potential by making it applicable in domains for which no edit histories are available and improving its ability to follow instructions, to write useful comments, and to explain its actions. We show that PEER achieves strong performance across various domains and editing tasks.
Few-shot Learning with Retrieval Augmented Language Models
Aug 08, 2022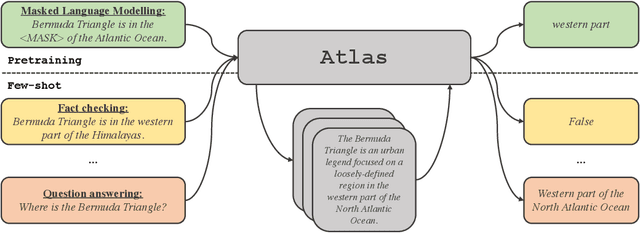
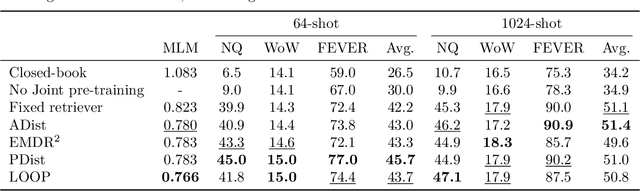


Large language models have shown impressive few-shot results on a wide range of tasks. However, when knowledge is key for such results, as is the case for tasks such as question answering and fact checking, massive parameter counts to store knowledge seem to be needed. Retrieval augmented models are known to excel at knowledge intensive tasks without the need for as many parameters, but it is unclear whether they work in few-shot settings. In this work we present Atlas, a carefully designed and pre-trained retrieval augmented language model able to learn knowledge intensive tasks with very few training examples. We perform evaluations on a wide range of tasks, including MMLU, KILT and NaturalQuestions, and study the impact of the content of the document index, showing that it can easily be updated. Notably, Atlas reaches over 42% accuracy on Natural Questions using only 64 examples, outperforming a 540B parameters model by 3% despite having 50x fewer parameters.
Improving Wikipedia Verifiability with AI
Jul 08, 2022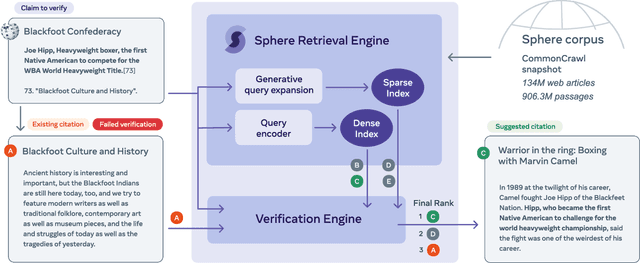

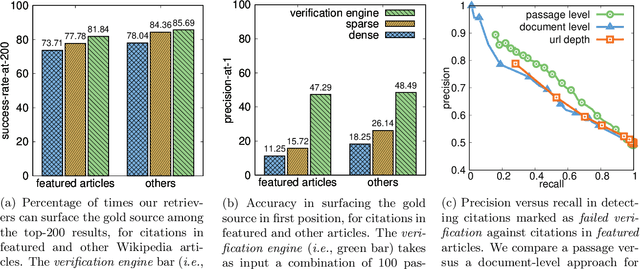
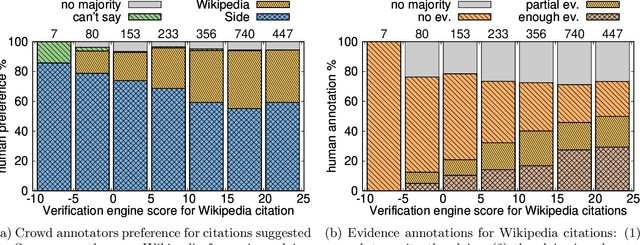
Verifiability is a core content policy of Wikipedia: claims that are likely to be challenged need to be backed by citations. There are millions of articles available online and thousands of new articles are released each month. For this reason, finding relevant sources is a difficult task: many claims do not have any references that support them. Furthermore, even existing citations might not support a given claim or become obsolete once the original source is updated or deleted. Hence, maintaining and improving the quality of Wikipedia references is an important challenge and there is a pressing need for better tools to assist humans in this effort. Here, we show that the process of improving references can be tackled with the help of artificial intelligence (AI). We develop a neural network based system, called Side, to identify Wikipedia citations that are unlikely to support their claims, and subsequently recommend better ones from the web. We train this model on existing Wikipedia references, therefore learning from the contributions and combined wisdom of thousands of Wikipedia editors. Using crowd-sourcing, we observe that for the top 10% most likely citations to be tagged as unverifiable by our system, humans prefer our system's suggested alternatives compared to the originally cited reference 70% of the time. To validate the applicability of our system, we built a demo to engage with the English-speaking Wikipedia community and find that Side's first citation recommendation collects over 60% more preferences than existing Wikipedia citations for the same top 10% most likely unverifiable claims according to Side. Our results indicate that an AI-based system could be used, in tandem with humans, to improve the verifiability of Wikipedia. More generally, we hope that our work can be used to assist fact checking efforts and increase the general trustworthiness of information online.
EDIN: An End-to-end Benchmark and Pipeline for Unknown Entity Discovery and Indexing
May 25, 2022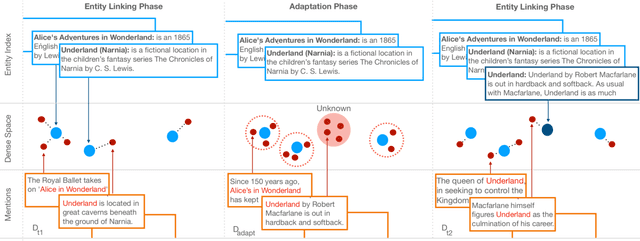



Existing work on Entity Linking mostly assumes that the reference knowledge base is complete, and therefore all mentions can be linked. In practice this is hardly ever the case, as knowledge bases are incomplete and because novel concepts arise constantly. This paper created the Unknown Entity Discovery and Indexing (EDIN) benchmark where unknown entities, that is entities without a description in the knowledge base and labeled mentions, have to be integrated into an existing entity linking system. By contrasting EDIN with zero-shot entity linking, we provide insight on the additional challenges it poses. Building on dense-retrieval based entity linking, we introduce the end-to-end EDIN pipeline that detects, clusters, and indexes mentions of unknown entities in context. Experiments show that indexing a single embedding per entity unifying the information of multiple mentions works better than indexing mentions independently.
Open Vocabulary Extreme Classification Using Generative Models
May 12, 2022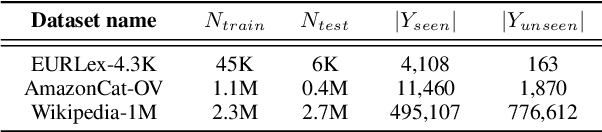
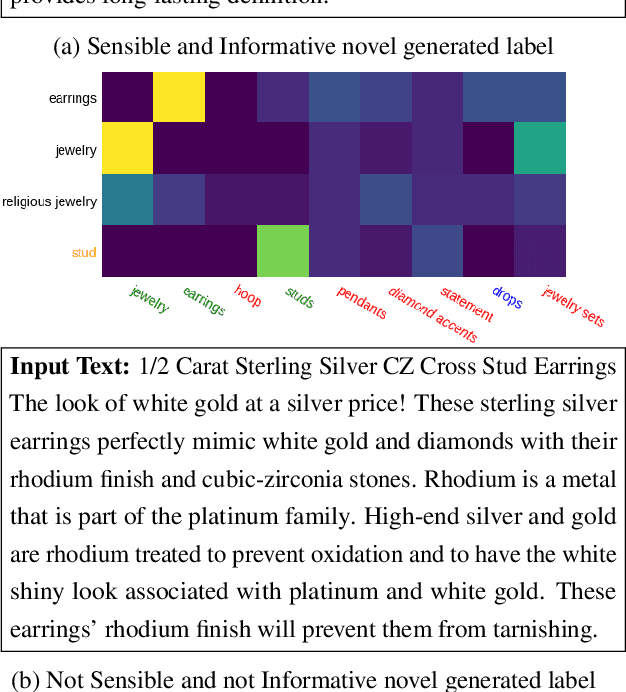
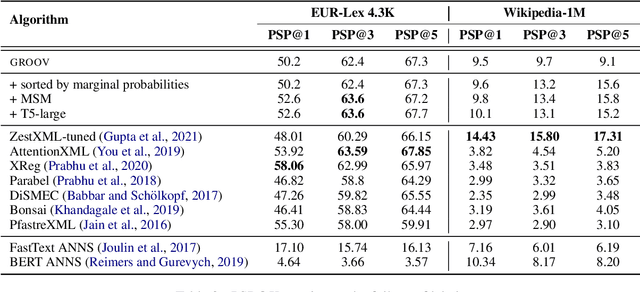

The extreme multi-label classification (XMC) task aims at tagging content with a subset of labels from an extremely large label set. The label vocabulary is typically defined in advance by domain experts and assumed to capture all necessary tags. However in real world scenarios this label set, although large, is often incomplete and experts frequently need to refine it. To develop systems that simplify this process, we introduce the task of open vocabulary XMC (OXMC): given a piece of content, predict a set of labels, some of which may be outside of the known tag set. Hence, in addition to not having training data for some labels - as is the case in zero-shot classification - models need to invent some labels on-the-fly. We propose GROOV, a fine-tuned seq2seq model for OXMC that generates the set of labels as a flat sequence and is trained using a novel loss independent of predicted label order. We show the efficacy of the approach, experimenting with popular XMC datasets for which GROOV is able to predict meaningful labels outside the given vocabulary while performing on par with state-of-the-art solutions for known labels.