 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgemmBERT: A Modern Multilingual Encoder with Annealed Language Learning
Sep 08, 2025Encoder-only languages models are frequently used for a variety of standard machine learning tasks, including classification and retrieval. However, there has been a lack of recent research for encoder models, especially with respect to multilingual models. We introduce mmBERT, an encoder-only language model pretrained on 3T tokens of multilingual text in over 1800 languages. To build mmBERT we introduce several novel elements, including an inverse mask ratio schedule and an inverse temperature sampling ratio. We add over 1700 low-resource languages to the data mix only during the decay phase, showing that it boosts performance dramatically and maximizes the gains from the relatively small amount of training data. Despite only including these low-resource languages in the short decay phase we achieve similar classification performance to models like OpenAI's o3 and Google's Gemini 2.5 Pro. Overall, we show that mmBERT significantly outperforms the previous generation of models on classification and retrieval tasks -- on both high and low-resource languages.
On the Theoretical Limitations of Embedding-Based Retrieval
Aug 28, 2025
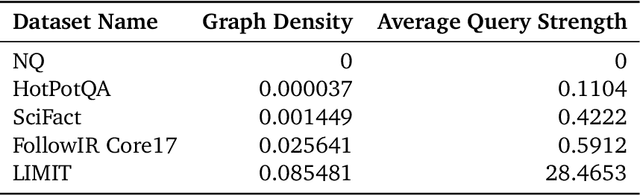


Vector embeddings have been tasked with an ever-increasing set of retrieval tasks over the years, with a nascent rise in using them for reasoning, instruction-following, coding, and more. These new benchmarks push embeddings to work for any query and any notion of relevance that could be given. While prior works have pointed out theoretical limitations of vector embeddings, there is a common assumption that these difficulties are exclusively due to unrealistic queries, and those that are not can be overcome with better training data and larger models. In this work, we demonstrate that we may encounter these theoretical limitations in realistic settings with extremely simple queries. We connect known results in learning theory, showing that the number of top-k subsets of documents capable of being returned as the result of some query is limited by the dimension of the embedding. We empirically show that this holds true even if we restrict to k=2, and directly optimize on the test set with free parameterized embeddings. We then create a realistic dataset called LIMIT that stress tests models based on these theoretical results, and observe that even state-of-the-art models fail on this dataset despite the simple nature of the task. Our work shows the limits of embedding models under the existing single vector paradigm and calls for future research to develop methods that can resolve this fundamental limitation.
Seq vs Seq: An Open Suite of Paired Encoders and Decoders
Jul 15, 2025The large language model (LLM) community focuses almost exclusively on decoder-only language models, since they are easier to use for text generation. However, a large subset of the community still uses encoder-only models for tasks such as classification or retrieval. Previous work has attempted to compare these architectures, but is forced to make comparisons with models that have different numbers of parameters, training techniques, and datasets. We introduce the SOTA open-data Ettin suite of models: paired encoder-only and decoder-only models ranging from 17 million parameters to 1 billion, trained on up to 2 trillion tokens. Using the same recipe for both encoder-only and decoder-only models produces SOTA recipes in both categories for their respective sizes, beating ModernBERT as an encoder and Llama 3.2 and SmolLM2 as decoders. Like previous work, we find that encoder-only models excel at classification and retrieval tasks while decoders excel at generative tasks. However, we show that adapting a decoder model to encoder tasks (and vice versa) through continued training is subpar compared to using only the reverse objective (i.e. a 400M encoder outperforms a 1B decoder on MNLI, and vice versa for generative tasks). We open-source all artifacts of this study including training data, training order segmented by checkpoint, and 200+ checkpoints to allow future work to analyze or extend all aspects of training.
Rank-K: Test-Time Reasoning for Listwise Reranking
May 20, 2025



Retrieve-and-rerank is a popular retrieval pipeline because of its ability to make slow but effective rerankers efficient enough at query time by reducing the number of comparisons. Recent works in neural rerankers take advantage of large language models for their capability in reasoning between queries and passages and have achieved state-of-the-art retrieval effectiveness. However, such rerankers are resource-intensive, even after heavy optimization. In this work, we introduce Rank-K, a listwise passage reranking model that leverages the reasoning capability of the reasoning language model at query time that provides test time scalability to serve hard queries. We show that Rank-K improves retrieval effectiveness by 23\% over the RankZephyr, the state-of-the-art listwise reranker, when reranking a BM25 initial ranked list and 19\% when reranking strong retrieval results by SPLADE-v3. Since Rank-K is inherently a multilingual model, we found that it ranks passages based on queries in different languages as effectively as it does in monolingual retrieval.
Beyond RAG: Task-Aware KV Cache Compression for Comprehensive Knowledge Reasoning
Mar 06, 2025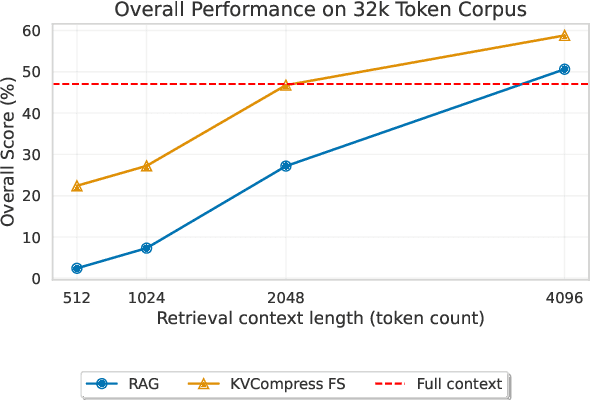

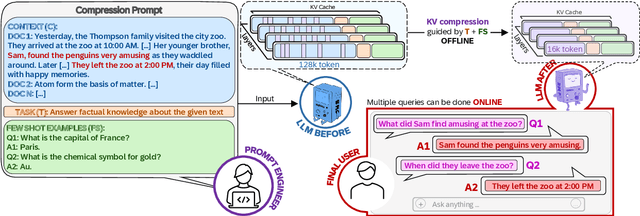

Incorporating external knowledge in large language models (LLMs) enhances their utility across diverse applications, but existing methods have trade-offs. Retrieval-Augmented Generation (RAG) fetches evidence via similarity search, but key information may fall outside top ranked results. Long-context models can process multiple documents but are computationally expensive and limited by context window size. Inspired by students condensing study material for open-book exams, we propose task-aware key-value (KV) cache compression, which compresses external knowledge in a zero- or few-shot setup. This enables LLMs to reason efficiently over a compacted representation of all relevant information. Experiments show our approach outperforms both RAG and task-agnostic compression methods. On LongBench v2, it improves accuracy by up to 7 absolute points over RAG with a 30x compression rate, while reducing inference latency from 0.43s to 0.16s. A synthetic dataset highlights that RAG performs well when sparse evidence suffices, whereas task-aware compression is superior for broad knowledge tasks.
Rank1: Test-Time Compute for Reranking in Information Retrieval
Feb 25, 2025



We introduce Rank1, the first reranking model trained to take advantage of test-time compute. Rank1 demonstrates the applicability within retrieval of using a reasoning language model (i.e. OpenAI's o1, Deepseek's R1, etc.) for distillation in order to rapidly improve the performance of a smaller model. We gather and open-source a dataset of more than 600,000 examples of R1 reasoning traces from queries and passages in MS MARCO. Models trained on this dataset show: (1) state-of-the-art performance on advanced reasoning and instruction following datasets; (2) work remarkably well out of distribution due to the ability to respond to user-input prompts; and (3) have explainable reasoning chains that can be given to users or RAG-based systems. Further, we demonstrate that quantized versions of these models retain strong performance while using less compute/memory. Overall, Rank1 shows that test-time compute allows for a fundamentally new type of explainable and performant reranker model for search.
MMTEB: Massive Multilingual Text Embedding Benchmark
Feb 19, 2025Text embeddings are typically evaluated on a limited set of tasks, which are constrained by language, domain, and task diversity. To address these limitations and provide a more comprehensive evaluation, we introduce the Massive Multilingual Text Embedding Benchmark (MMTEB) - a large-scale, community-driven expansion of MTEB, covering over 500 quality-controlled evaluation tasks across 250+ languages. MMTEB includes a diverse set of challenging, novel tasks such as instruction following, long-document retrieval, and code retrieval, representing the largest multilingual collection of evaluation tasks for embedding models to date. Using this collection, we develop several highly multilingual benchmarks, which we use to evaluate a representative set of models. We find that while large language models (LLMs) with billions of parameters can achieve state-of-the-art performance on certain language subsets and task categories, the best-performing publicly available model is multilingual-e5-large-instruct with only 560 million parameters. To facilitate accessibility and reduce computational cost, we introduce a novel downsampling method based on inter-task correlation, ensuring a diverse selection while preserving relative model rankings. Furthermore, we optimize tasks such as retrieval by sampling hard negatives, creating smaller but effective splits. These optimizations allow us to introduce benchmarks that drastically reduce computational demands. For instance, our newly introduced zero-shot English benchmark maintains a ranking order similar to the full-scale version but at a fraction of the computational cost.
mFollowIR: a Multilingual Benchmark for Instruction Following in Retrieval
Jan 31, 2025



Retrieval systems generally focus on web-style queries that are short and underspecified. However, advances in language models have facilitated the nascent rise of retrieval models that can understand more complex queries with diverse intents. However, these efforts have focused exclusively on English; therefore, we do not yet understand how they work across languages. We introduce mFollowIR, a multilingual benchmark for measuring instruction-following ability in retrieval models. mFollowIR builds upon the TREC NeuCLIR narratives (or instructions) that span three diverse languages (Russian, Chinese, Persian) giving both query and instruction to the retrieval models. We make small changes to the narratives and isolate how well retrieval models can follow these nuanced changes. We present results for both multilingual (XX-XX) and cross-lingual (En-XX) performance. We see strong cross-lingual performance with English-based retrievers that trained using instructions, but find a notable drop in performance in the multilingual setting, indicating that more work is needed in developing data for instruction-based multilingual retrievers.
Humanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.
From Models to Microtheories: Distilling a Model's Topical Knowledge for Grounded Question Answering
Dec 24, 2024



Recent reasoning methods (e.g., chain-of-thought, entailment reasoning) help users understand how language models (LMs) answer a single question, but they do little to reveal the LM's overall understanding, or "theory," about the question's topic, making it still hard to trust the model. Our goal is to materialize such theories - here called microtheories (a linguistic analog of logical microtheories) - as a set of sentences encapsulating an LM's core knowledge about a topic. These statements systematically work together to entail answers to a set of questions to both engender trust and improve performance. Our approach is to first populate a knowledge store with (model-generated) sentences that entail answers to training questions and then distill those down to a core microtheory that is concise, general, and non-redundant. We show that, when added to a general corpus (e.g., Wikipedia), microtheories can supply critical, topical information not necessarily present in the corpus, improving both a model's ability to ground its answers to verifiable knowledge (i.e., show how answers are systematically entailed by documents in the corpus, fully grounding up to +8% more answers), and the accuracy of those grounded answers (up to +8% absolute). We also show that, in a human evaluation in the medical domain, our distilled microtheories contain a significantly higher concentration of topically critical facts than the non-distilled knowledge store. Finally, we show we can quantify the coverage of a microtheory for a topic (characterized by a dataset) using a notion of $p$-relevance. Together, these suggest that microtheories are an efficient distillation of an LM's topic-relevant knowledge, that they can usefully augment existing corpora, and can provide both performance gains and an interpretable, verifiable window into the model's knowledge of a topic.