 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLERC: A Dataset for Legal Case Retrieval and Retrieval-Augmented Analysis Generation
Paper and Code

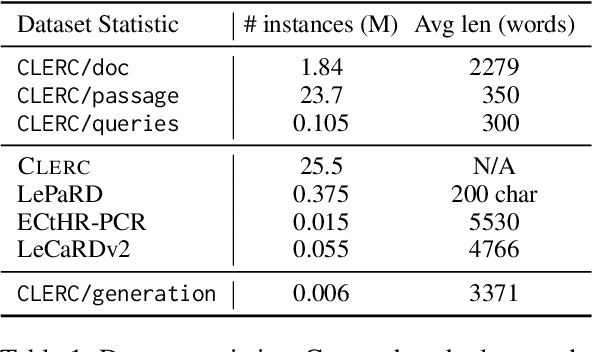


Legal professionals need to write analyses that rely on citations to relevant precedents, i.e., previous case decisions. Intelligent systems assisting legal professionals in writing such documents provide great benefits but are challenging to design. Such systems need to help locate, summarize, and reason over salient precedents in order to be useful. To enable systems for such tasks, we work with legal professionals to transform a large open-source legal corpus into a dataset supporting two important backbone tasks: information retrieval (IR) and retrieval-augmented generation (RAG). This dataset CLERC (Case Law Evaluation Retrieval Corpus), is constructed for training and evaluating models on their ability to (1) find corresponding citations for a given piece of legal analysis and to (2) compile the text of these citations (as well as previous context) into a cogent analysis that supports a reasoning goal. We benchmark state-of-the-art models on CLERC, showing that current approaches still struggle: GPT-4o generates analyses with the highest ROUGE F-scores but hallucinates the most, while zero-shot IR models only achieve 48.3% recall@1000.