 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaps or Hallucinations? Gazing into Machine-Generated Legal Analysis for Fine-grained Text Evaluations
Sep 16, 2024Large Language Models (LLMs) show promise as a writing aid for professionals performing legal analyses. However, LLMs can often hallucinate in this setting, in ways difficult to recognize by non-professionals and existing text evaluation metrics. In this work, we pose the question: when can machine-generated legal analysis be evaluated as acceptable? We introduce the neutral notion of gaps, as opposed to hallucinations in a strict erroneous sense, to refer to the difference between human-written and machine-generated legal analysis. Gaps do not always equate to invalid generation. Working with legal experts, we consider the CLERC generation task proposed in Hou et al. (2024b), leading to a taxonomy, a fine-grained detector for predicting gap categories, and an annotated dataset for automatic evaluation. Our best detector achieves 67% F1 score and 80% precision on the test set. Employing this detector as an automated metric on legal analysis generated by SOTA LLMs, we find around 80% contain hallucinations of different kinds.
CLERC: A Dataset for Legal Case Retrieval and Retrieval-Augmented Analysis Generation
Jun 24, 2024
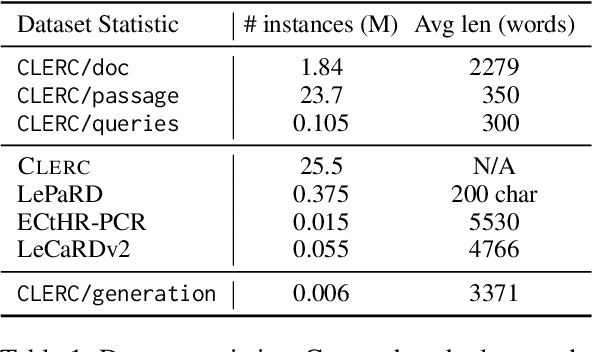


Legal professionals need to write analyses that rely on citations to relevant precedents, i.e., previous case decisions. Intelligent systems assisting legal professionals in writing such documents provide great benefits but are challenging to design. Such systems need to help locate, summarize, and reason over salient precedents in order to be useful. To enable systems for such tasks, we work with legal professionals to transform a large open-source legal corpus into a dataset supporting two important backbone tasks: information retrieval (IR) and retrieval-augmented generation (RAG). This dataset CLERC (Case Law Evaluation Retrieval Corpus), is constructed for training and evaluating models on their ability to (1) find corresponding citations for a given piece of legal analysis and to (2) compile the text of these citations (as well as previous context) into a cogent analysis that supports a reasoning goal. We benchmark state-of-the-art models on CLERC, showing that current approaches still struggle: GPT-4o generates analyses with the highest ROUGE F-scores but hallucinates the most, while zero-shot IR models only achieve 48.3% recall@1000.
BLT: Can Large Language Models Handle Basic Legal Text?
Nov 16, 2023
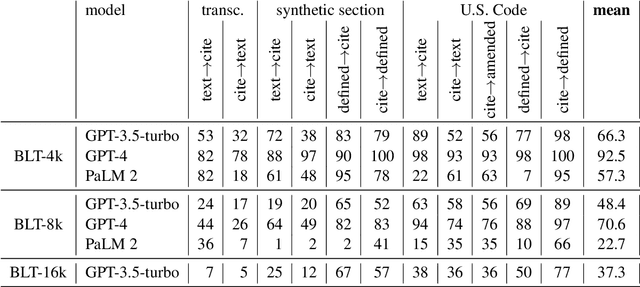
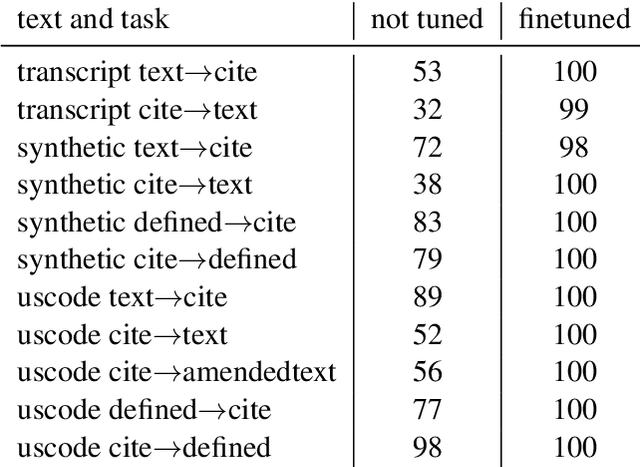
We find that the best publicly available LLMs like GPT-4 and PaLM 2 currently perform poorly at basic text handling required of lawyers or paralegals, such as looking up the text at a line of a witness deposition or at a subsection of a contract. We introduce a benchmark to quantify this poor performance, which casts into doubt LLMs' current reliability as-is for legal practice. Finetuning for these tasks brings an older LLM to near-perfect performance on our test set and also raises performance on a related legal task. This stark result highlights the need for more domain expertise in LLM training.
OpenAI Cribbed Our Tax Example, But Can GPT-4 Really Do Tax?
Sep 15, 2023The authors explain where OpenAI got the tax law example in its livestream demonstration of GPT-4, why GPT-4 got the wrong answer, and how it fails to reliably calculate taxes.
* 5 pages
InteractiveIE: Towards Assessing the Strength of Human-AI Collaboration in Improving the Performance of Information Extraction
May 24, 2023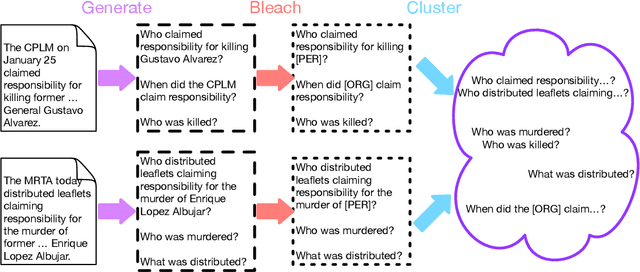



Learning template based information extraction from documents is a crucial yet difficult task. Prior template-based IE approaches assume foreknowledge of the domain templates; however, real-world IE do not have pre-defined schemas and it is a figure-out-as you go phenomena. To quickly bootstrap templates in a real-world setting, we need to induce template slots from documents with zero or minimal supervision. Since the purpose of question answering intersect with the goal of information extraction, we use automatic question generation to induce template slots from the documents and investigate how a tiny amount of a proxy human-supervision on-the-fly (termed as InteractiveIE) can further boost the performance. Extensive experiments on biomedical and legal documents, where obtaining training data is expensive, reveal encouraging trends of performance improvement using InteractiveIE over AI-only baseline.
Can GPT-3 Perform Statutory Reasoning?
Feb 13, 2023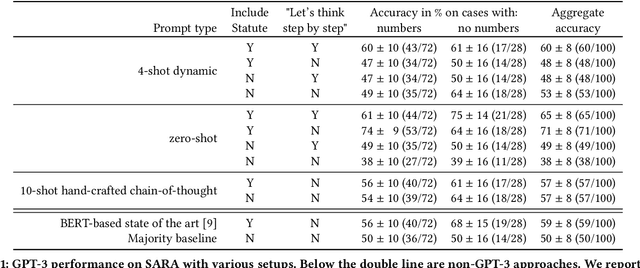



Statutory reasoning is the task of reasoning with facts and statutes, which are rules written in natural language by a legislature. It is a basic legal skill. In this paper we explore the capabilities of the most capable GPT-3 model, text-davinci-003, on an established statutory-reasoning dataset called SARA. We consider a variety of approaches, including dynamic few-shot prompting, chain-of-thought prompting, and zero-shot prompting. While we achieve results with GPT-3 that are better than the previous best published results, we also identify several types of clear errors it makes. In investigating why these happen, we discover that GPT-3 has imperfect prior knowledge of the actual U.S. statutes on which SARA is based. More importantly, GPT-3 performs poorly at answering straightforward questions about simple synthetic statutes. By also posing the same questions when the synthetic statutes are written in sentence form, we find that some of GPT-3's poor performance results from difficulty in parsing the typical structure of statutes, containing subsections and paragraphs.
A Dataset for Statutory Reasoning in Tax Law Entailment and Question Answering
May 17, 2020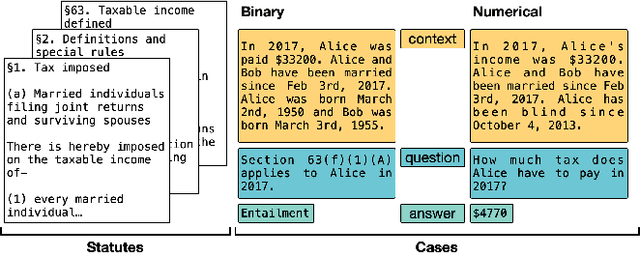
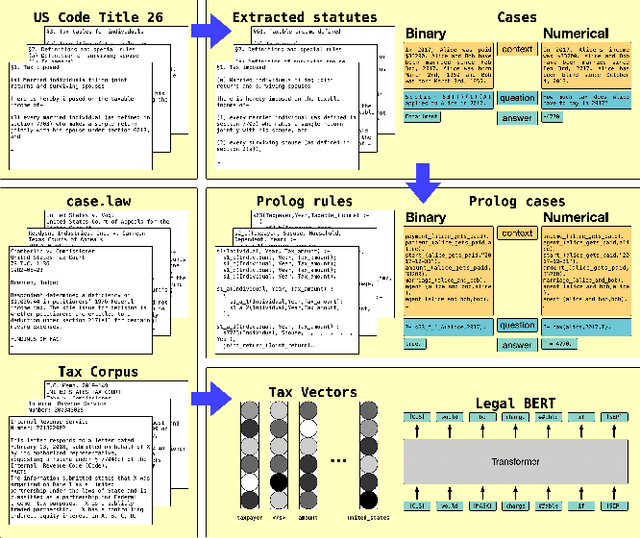
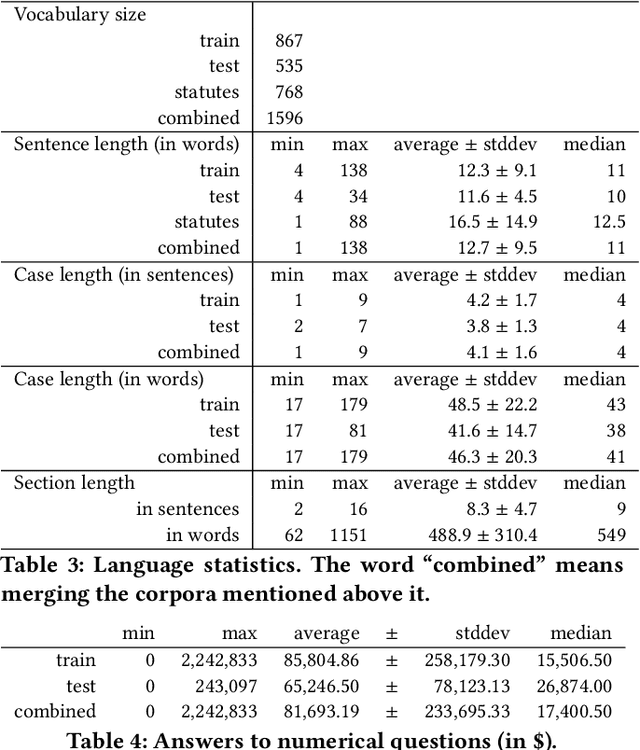
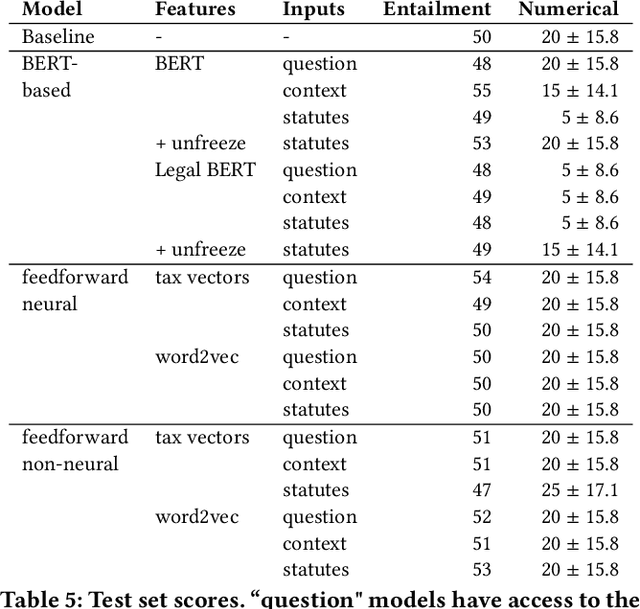
Legislation can be viewed as a body of prescriptive rules expressed in natural language. The application of legislation to facts of a case we refer to as statutory reasoning, where those facts are also expressed in natural language. Computational statutory reasoning is distinct from most existing work in machine reading, in that much of the information needed for deciding a case is declared exactly once (a law), while the information needed in much of machine reading tends to be learned through distributional language statistics. To investigate the performance of natural language understanding approaches on statutory reasoning, we introduce a dataset, together with a legal-domain text corpus. Straightforward application of machine reading models exhibits low out-of-the-box performance on our questions, whether or not they have been fine-tuned to the legal domain. We contrast this with a hand-constructed Prolog-based system, designed to fully solve the task. These experiments support a discussion of the challenges facing statutory reasoning moving forward, which we argue is an interesting real-world task that can motivate the development of models able to utilize prescriptive rules specified in natural language.