 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteractiveIE: Towards Assessing the Strength of Human-AI Collaboration in Improving the Performance of Information Extraction
May 24, 2023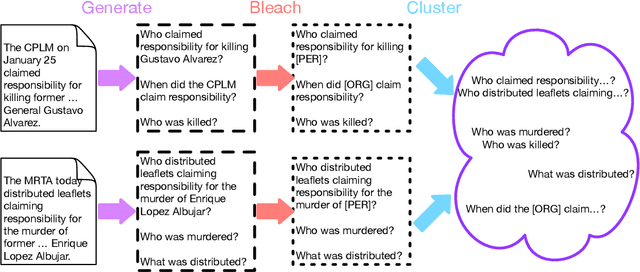



Learning template based information extraction from documents is a crucial yet difficult task. Prior template-based IE approaches assume foreknowledge of the domain templates; however, real-world IE do not have pre-defined schemas and it is a figure-out-as you go phenomena. To quickly bootstrap templates in a real-world setting, we need to induce template slots from documents with zero or minimal supervision. Since the purpose of question answering intersect with the goal of information extraction, we use automatic question generation to induce template slots from the documents and investigate how a tiny amount of a proxy human-supervision on-the-fly (termed as InteractiveIE) can further boost the performance. Extensive experiments on biomedical and legal documents, where obtaining training data is expensive, reveal encouraging trends of performance improvement using InteractiveIE over AI-only baseline.
CLAUSEREC: A Clause Recommendation Framework for AI-aided Contract Authoring
Oct 26, 2021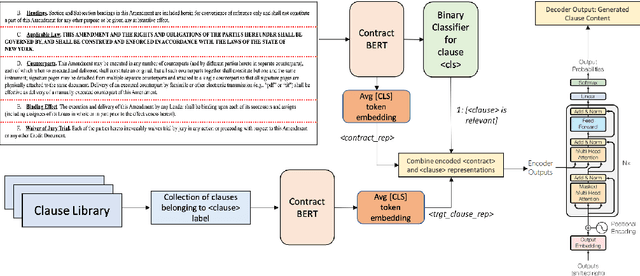
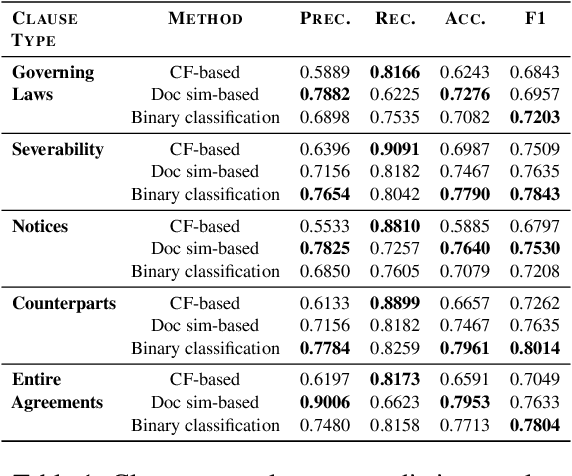
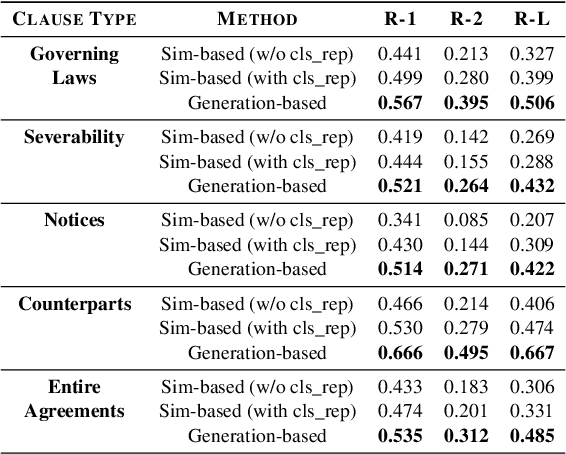
Contracts are a common type of legal document that frequent in several day-to-day business workflows. However, there has been very limited NLP research in processing such documents, and even lesser in generating them. These contracts are made up of clauses, and the unique nature of these clauses calls for specific methods to understand and generate such documents. In this paper, we introduce the task of clause recommendation, asa first step to aid and accelerate the author-ing of contract documents. We propose a two-staged pipeline to first predict if a specific clause type is relevant to be added in a contract, and then recommend the top clauses for the given type based on the contract context. We pretrain BERT on an existing library of clauses with two additional tasks and use it for our prediction and recommendation. We experiment with classification methods and similarity-based heuristics for clause relevance prediction, and generation-based methods for clause recommendation, and evaluate the results from various methods on several clause types. We provide analyses on the results, and further outline the advantages and limitations of the various methods for this line of research.
Multi-dimensional Style Transfer for Partially Annotated Data using Language Models as Discriminators
Oct 22, 2020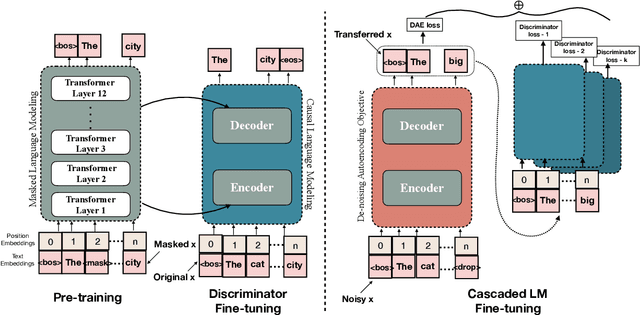

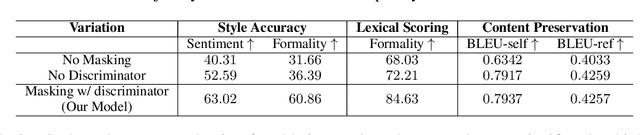

Style transfer has been widely explored in natural language generation with non-parallel corpus by directly or indirectly extracting a notion of style from source and target domain corpus. A common aspect among the existing approaches is the prerequisite of joint annotations across all the stylistic dimensions under consideration. Availability of such dataset across a combination of styles is a limiting factor in extending state-of-the art style transfer setups to multiple style dimensions. While cascading single-dimensional models across multiple styles is a possibility, it suffers from content loss, especially when the style dimensions are not completely independent of each other. In our work, we attempt to relax this restriction on requirement of jointly annotated data across multiple styles being inspected and make use of independently acquired data across different style dimensions without any additional annotations. We initialize an encoder-decoder setup with large transformer-based language models pre-trained on a generic corpus and enhance its re-writing capability to multiple styles by employing multiple language models as discriminators. Through quantitative and qualitative evaluation, we show the ability of our model to control for styles across multiple style-dimensions while preserving content of the input text and compare it against baselines which involve cascaded state-of-the-art uni-dimensional style transfer models.
Adapting Language Models for Non-Parallel Author-Stylized Rewriting
Sep 22, 2019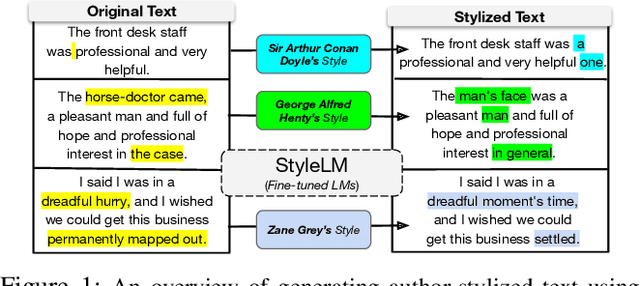
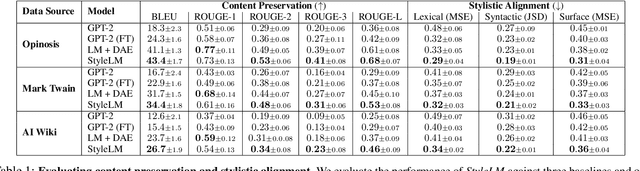
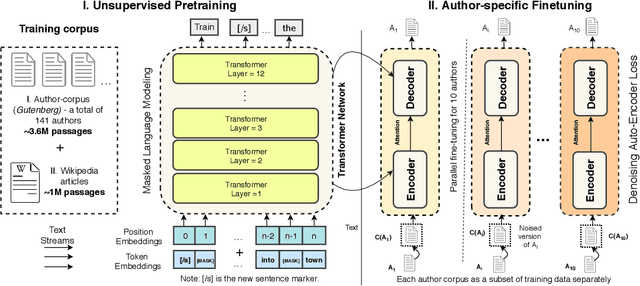

Given the recent progress in language modeling using Transformer-based neural models and an active interest in generating stylized text, we present an approach to leverage the generalization capabilities of a language model to rewrite an input text in a target author's style. Our proposed approach adapts a pre-trained language model to generate author-stylized text by fine-tuning on the author-specific corpus using a denoising autoencoder (DAE) loss in a cascaded encoder-decoder framework. Optimizing over DAE loss allows our model to learn the nuances of an author's style without relying on parallel data, which has been a severe limitation of the previous related works in this space. To evaluate the efficacy of our approach, we propose a linguistically-motivated framework to quantify stylistic alignment of the generated text to the target author at lexical, syntactic and surface levels. The evaluation framework is both interpretable as it leads to several insights about the model, and self-contained as it does not rely on external classifiers, e.g. sentiment or formality classifiers. Qualitative and quantitative assessment indicates that the proposed approach rewrites the input text with better alignment to the target style while preserving the original content better than state-of-the-art baselines.