 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSteering Safely or Off a Cliff? Rethinking Specificity and Robustness in Inference-Time Interventions
Feb 05, 2026Model steering, which involves intervening on hidden representations at inference time, has emerged as a lightweight alternative to finetuning for precisely controlling large language models. While steering efficacy has been widely studied, evaluations of whether interventions alter only the intended property remain limited, especially with respect to unintended changes in behaviors related to the target property. We call this notion specificity. We propose a framework that distinguishes three dimensions of specificity: general (preserving fluency and unrelated abilities), control (preserving related control properties), and robustness (preserving control properties under distribution shifts). We study two safety-critical use cases: steering models to reduce overrefusal and faithfulness hallucinations, and show that while steering achieves high efficacy and largely maintains general and control specificity, it consistently fails to preserve robustness specificity. In the case of overrefusal steering, for example, all steering methods reduce overrefusal without harming general abilities and refusal on harmful queries; however, they substantially increase vulnerability to jailbreaks. Our work provides the first systematic evaluation of specificity in model steering, showing that standard efficacy and specificity checks are insufficient, because without robustness evaluation, steering methods may appear reliable even when they compromise model safety.
Causal Effect of Group Diversity on Redundancy and Coverage in Peer-Reviewing
Nov 18, 2024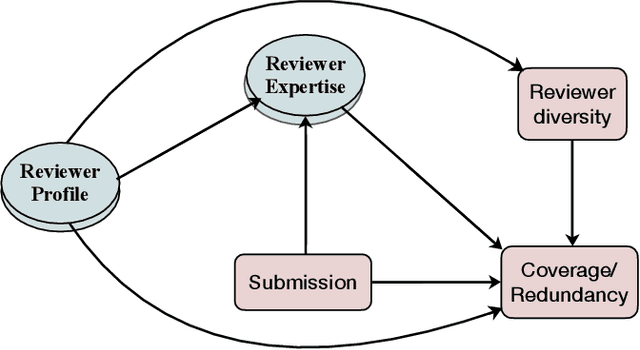

A large host of scientific journals and conferences solicit peer reviews from multiple reviewers for the same submission, aiming to gather a broader range of perspectives and mitigate individual biases. In this work, we reflect on the role of diversity in the slate of reviewers assigned to evaluate a submitted paper as a factor in diversifying perspectives and improving the utility of the peer-review process. We propose two measures for assessing review utility: review coverage -- reviews should cover most contents of the paper -- and review redundancy -- reviews should add information not already present in other reviews. We hypothesize that reviews from diverse reviewers will exhibit high coverage and low redundancy. We conduct a causal study of different measures of reviewer diversity on review coverage and redundancy using observational data from a peer-reviewed conference with approximately 5,000 submitted papers. Our study reveals disparate effects of different diversity measures on review coverage and redundancy. Our study finds that assigning a group of reviewers that are topically diverse, have different seniority levels, or have distinct publication networks leads to broader coverage of the paper or review criteria, but we find no evidence of an increase in coverage for reviewer slates with reviewers from diverse organizations or geographical locations. Reviewers from different organizations, seniority levels, topics, or publications networks (all except geographical diversity) lead to a decrease in redundancy in reviews. Furthermore, publication network-based diversity alone also helps bring in varying perspectives (that is, low redundancy), even within specific review criteria. Our study adopts a group decision-making perspective for reviewer assignments in peer review and suggests dimensions of diversity that can help guide the reviewer assignment process.
Explaining with Contrastive Phrasal Highlighting: A Case Study in Assisting Humans to Detect Translation Differences
Dec 04, 2023Explainable NLP techniques primarily explain by answering "Which tokens in the input are responsible for this prediction?''. We argue that for NLP models that make predictions by comparing two input texts, it is more useful to explain by answering "What differences between the two inputs explain this prediction?''. We introduce a technique to generate contrastive highlights that explain the predictions of a semantic divergence model via phrase-alignment-guided erasure. We show that the resulting highlights match human rationales of cross-lingual semantic differences better than popular post-hoc saliency techniques and that they successfully help people detect fine-grained meaning differences in human translations and critical machine translation errors.
Large Language Models Help Humans Verify Truthfulness -- Except When They Are Convincingly Wrong
Oct 19, 2023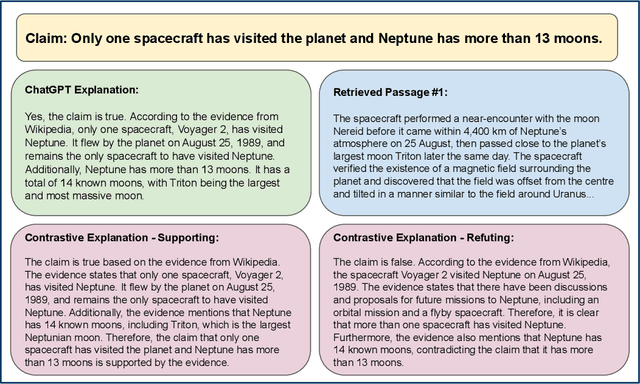
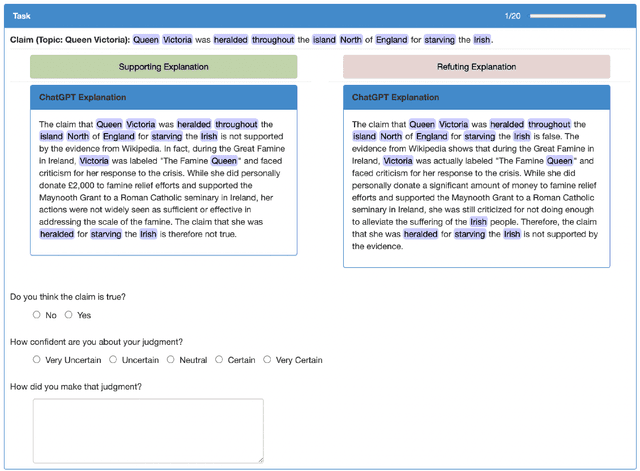
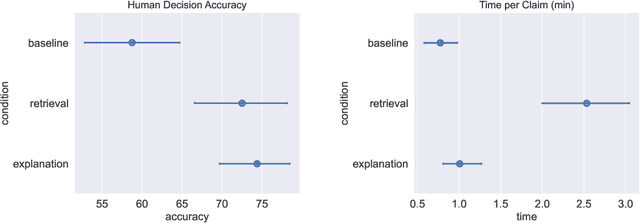
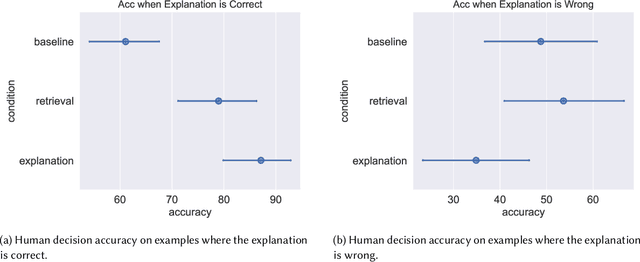
Large Language Models (LLMs) are increasingly used for accessing information on the web. Their truthfulness and factuality are thus of great interest. To help users make the right decisions about the information they're getting, LLMs should not only provide but also help users fact-check information. In this paper, we conduct experiments with 80 crowdworkers in total to compare language models with search engines (information retrieval systems) at facilitating fact-checking by human users. We prompt LLMs to validate a given claim and provide corresponding explanations. Users reading LLM explanations are significantly more efficient than using search engines with similar accuracy. However, they tend to over-rely the LLMs when the explanation is wrong. To reduce over-reliance on LLMs, we ask LLMs to provide contrastive information - explain both why the claim is true and false, and then we present both sides of the explanation to users. This contrastive explanation mitigates users' over-reliance on LLMs, but cannot significantly outperform search engines. However, showing both search engine results and LLM explanations offers no complementary benefits as compared to search engines alone. Taken together, natural language explanations by LLMs may not be a reliable replacement for reading the retrieved passages yet, especially in high-stakes settings where over-relying on wrong AI explanations could lead to critical consequences.
The Impact of Explanations on Fairness in Human-AI Decision-Making: Protected vs Proxy Features
Oct 12, 2023



AI systems have been known to amplify biases in real world data. Explanations may help human-AI teams address these biases for fairer decision-making. Typically, explanations focus on salient input features. If a model is biased against some protected group, explanations may include features that demonstrate this bias, but when biases are realized through proxy features, the relationship between this proxy feature and the protected one may be less clear to a human. In this work, we study the effect of the presence of protected and proxy features on participants' perception of model fairness and their ability to improve demographic parity over an AI alone. Further, we examine how different treatments -- explanations, model bias disclosure and proxy correlation disclosure -- affect fairness perception and parity. We find that explanations help people detect direct biases but not indirect biases. Additionally, regardless of bias type, explanations tend to increase agreement with model biases. Disclosures can help mitigate this effect for indirect biases, improving both unfairness recognition and the decision-making fairness. We hope that our findings can help guide further research into advancing explanations in support of fair human-AI decision-making.
What Else Do I Need to Know? The Effect of Background Information on Users' Reliance on AI Systems
May 23, 2023AI systems have shown impressive performance at answering questions by retrieving relevant context. However, with the increasingly large models, it is impossible and often undesirable to constrain models' knowledge or reasoning to only the retrieved context. This leads to a mismatch between the information that these models access to derive the answer and the information available to the user consuming the AI predictions to assess the AI predicted answer. In this work, we study how users interact with AI systems in absence of sufficient information to assess AI predictions. Further, we ask the question of whether adding the requisite background alleviates the concerns around over-reliance in AI predictions. Our study reveals that users rely on AI predictions even in the absence of sufficient information needed to assess its correctness. Providing the relevant background, however, helps users catch AI errors better, reducing over-reliance on incorrect AI predictions. On the flip side, background information also increases users' confidence in their correct as well as incorrect judgments. Contrary to common expectation, aiding a user's perusal of the context and the background through highlights is not helpful in alleviating the issue of over-confidence stemming from availability of more information. Our work aims to highlight the gap between how NLP developers perceive informational need in human-AI interaction and the actual human interaction with the information available to them.
Personalized Detection of Cognitive Biases in Actions of Users from Their Logs: Anchoring and Recency Biases
Jul 01, 2022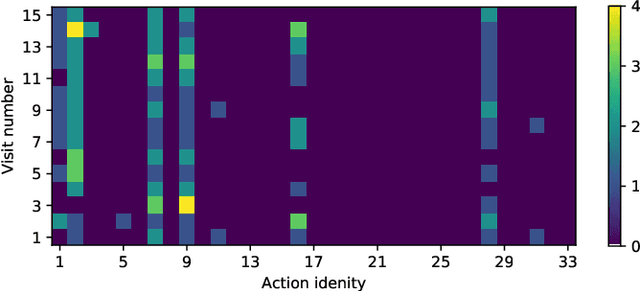

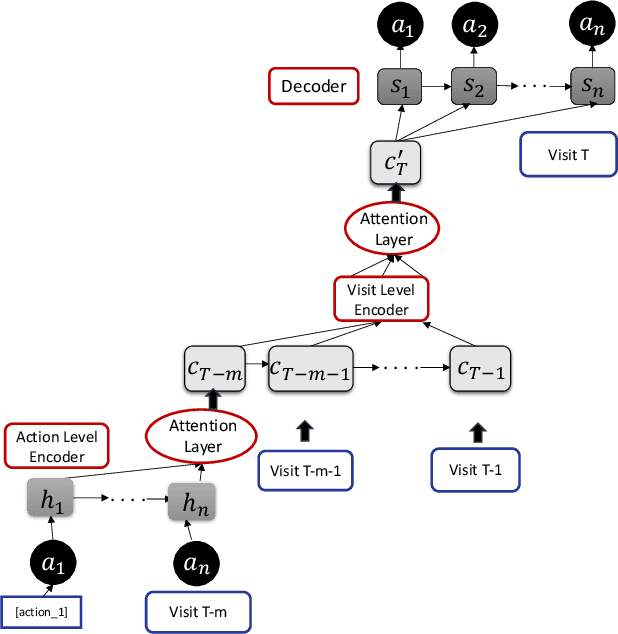
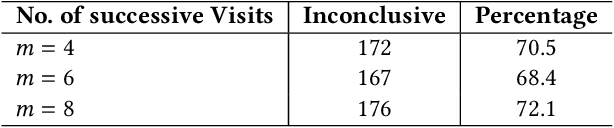
Cognitive biases are mental shortcuts humans use in dealing with information and the environment, and which result in biased actions and behaviors (or, actions), unbeknownst to themselves. Biases take many forms, with cognitive biases occupying a central role that inflicts fairness, accountability, transparency, ethics, law, medicine, and discrimination. Detection of biases is considered a necessary step toward their mitigation. Herein, we focus on two cognitive biases - anchoring and recency. The recognition of cognitive bias in computer science is largely in the domain of information retrieval, and bias is identified at an aggregate level with the help of annotated data. Proposing a different direction for bias detection, we offer a principled approach along with Machine Learning to detect these two cognitive biases from Web logs of users' actions. Our individual user level detection makes it truly personalized, and does not rely on annotated data. Instead, we start with two basic principles established in cognitive psychology, use modified training of an attention network, and interpret attention weights in a novel way according to those principles, to infer and distinguish between these two biases. The personalized approach allows detection for specific users who are susceptible to these biases when performing their tasks, and can help build awareness among them so as to undertake bias mitigation.
CaM-Gen:Causally-aware Metric-guided Text Generation
Oct 24, 2020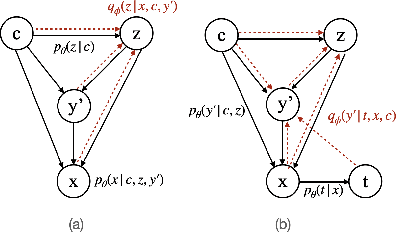
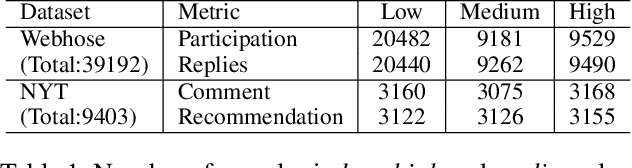
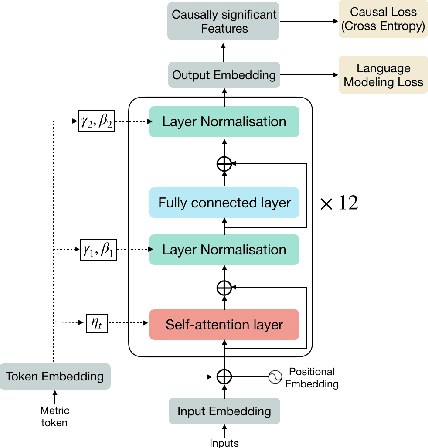
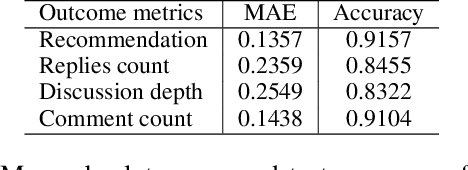
Content is created for a well-defined purpose, often described by a metric or a signal represented in the form of structured information. The relationship between the metrics or the goal of a target content and the content itself are non-trivial. While large scale language models show promising text generation capabilities, guiding and informing the generated text with external metrics is challenging. These metrics and the content tend to have inherent relationships and not all of them may directly impact the content. We introduce a CaM-Gen: Causally-aware Generative Networks guided by user-defined input metrics incorporating the causal relationships between the metric and the content features. We leverage causal inference techniques to identify the causally significant aspects of text that leads to the target metric and then explicitly guide the generative model towards these by a feedback mechanism. We propose this mechanism for variational autoencoder-based and transformer-based generative models. The proposed models beat baselines in terms of the target metric accuracy while maintaining the fluency and the language quality of the generated text. To the best of our knowledge, this is one of the early attempts at incorporating a metric-guide using causal inference towards controlled generation.
Multi-dimensional Style Transfer for Partially Annotated Data using Language Models as Discriminators
Oct 22, 2020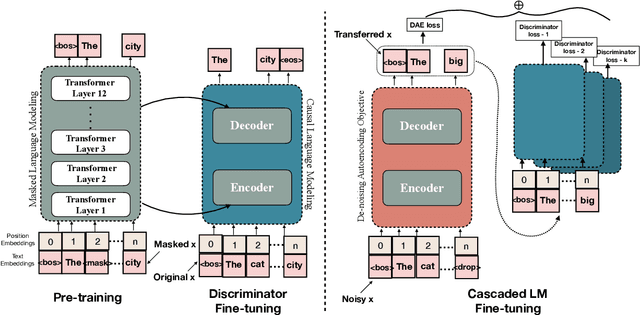

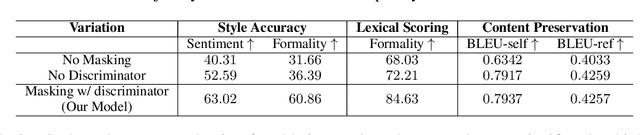

Style transfer has been widely explored in natural language generation with non-parallel corpus by directly or indirectly extracting a notion of style from source and target domain corpus. A common aspect among the existing approaches is the prerequisite of joint annotations across all the stylistic dimensions under consideration. Availability of such dataset across a combination of styles is a limiting factor in extending state-of-the art style transfer setups to multiple style dimensions. While cascading single-dimensional models across multiple styles is a possibility, it suffers from content loss, especially when the style dimensions are not completely independent of each other. In our work, we attempt to relax this restriction on requirement of jointly annotated data across multiple styles being inspected and make use of independently acquired data across different style dimensions without any additional annotations. We initialize an encoder-decoder setup with large transformer-based language models pre-trained on a generic corpus and enhance its re-writing capability to multiple styles by employing multiple language models as discriminators. Through quantitative and qualitative evaluation, we show the ability of our model to control for styles across multiple style-dimensions while preserving content of the input text and compare it against baselines which involve cascaded state-of-the-art uni-dimensional style transfer models.