 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Infer Unobserved Behaviors: Estimating User's Preference for a Site over Other Sites
Dec 15, 2023A site's recommendation system relies on knowledge of its users' preferences to offer relevant recommendations to them. These preferences are for attributes that comprise items and content shown on the site, and are estimated from the data of users' interactions with the site. Another form of users' preferences is material too, namely, users' preferences for the site over other sites, since that shows users' base level propensities to engage with the site. Estimating users' preferences for the site, however, faces major obstacles because (a) the focal site usually has no data of its users' interactions with other sites; these interactions are users' unobserved behaviors for the focal site; and (b) the Machine Learning literature in recommendation does not offer a model of this situation. Even if (b) is resolved, the problem in (a) persists since without access to data of its users' interactions with other sites, there is no ground truth for evaluation. Moreover, it is most useful when (c) users' preferences for the site can be estimated at the individual level, since the site can then personalize recommendations to individual users. We offer a method to estimate individual user's preference for a focal site, under this premise. In particular, we compute the focal site's share of a user's online engagements without any data from other sites. We show an evaluation framework for the model using only the focal site's data, allowing the site to test the model. We rely upon a Hierarchical Bayes Method and perform estimation in two different ways - Markov Chain Monte Carlo and Stochastic Gradient with Langevin Dynamics. Our results find good support for the approach to computing personalized share of engagement and for its evaluation.
Personalized Detection of Cognitive Biases in Actions of Users from Their Logs: Anchoring and Recency Biases
Jul 01, 2022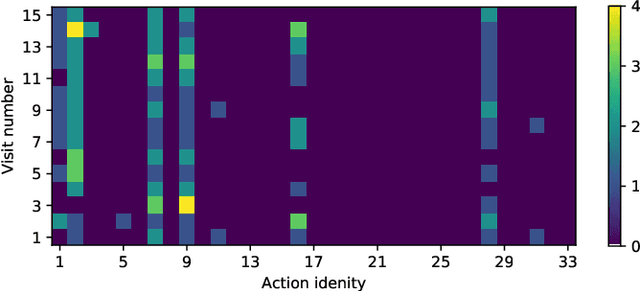

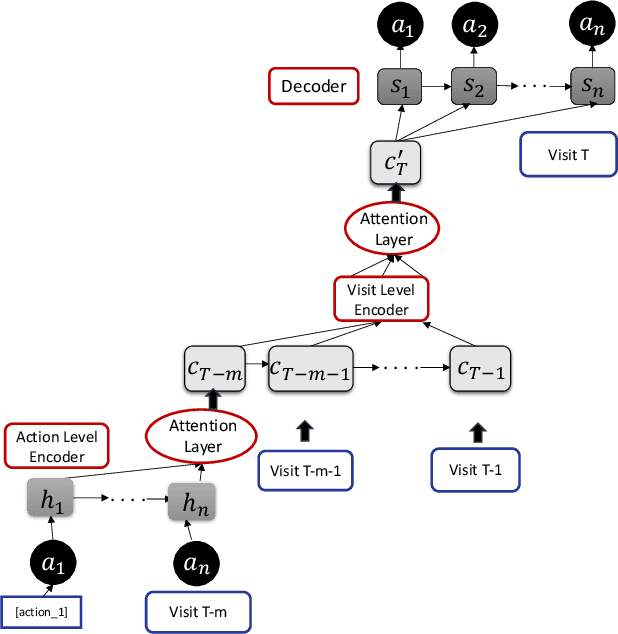
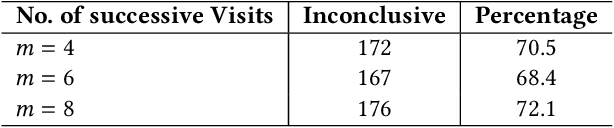
Cognitive biases are mental shortcuts humans use in dealing with information and the environment, and which result in biased actions and behaviors (or, actions), unbeknownst to themselves. Biases take many forms, with cognitive biases occupying a central role that inflicts fairness, accountability, transparency, ethics, law, medicine, and discrimination. Detection of biases is considered a necessary step toward their mitigation. Herein, we focus on two cognitive biases - anchoring and recency. The recognition of cognitive bias in computer science is largely in the domain of information retrieval, and bias is identified at an aggregate level with the help of annotated data. Proposing a different direction for bias detection, we offer a principled approach along with Machine Learning to detect these two cognitive biases from Web logs of users' actions. Our individual user level detection makes it truly personalized, and does not rely on annotated data. Instead, we start with two basic principles established in cognitive psychology, use modified training of an attention network, and interpret attention weights in a novel way according to those principles, to infer and distinguish between these two biases. The personalized approach allows detection for specific users who are susceptible to these biases when performing their tasks, and can help build awareness among them so as to undertake bias mitigation.
Surveys without Questions: A Reinforcement Learning Approach
Jun 11, 2020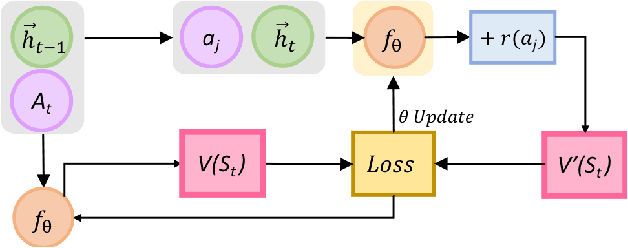

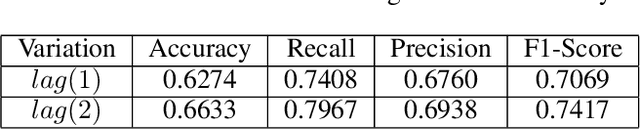
The 'old world' instrument, survey, remains a tool of choice for firms to obtain ratings of satisfaction and experience that customers realize while interacting online with firms. While avenues for survey have evolved from emails and links to pop-ups while browsing, the deficiencies persist. These include - reliance on ratings of very few respondents to infer about all customers' online interactions; failing to capture a customer's interactions over time since the rating is a one-time snapshot; and inability to tie back customers' ratings to specific interactions because ratings provided relate to all interactions. To overcome these deficiencies we extract proxy ratings from clickstream data, typically collected for every customer's online interactions, by developing an approach based on Reinforcement Learning (RL). We introduce a new way to interpret values generated by the value function of RL, as proxy ratings. Our approach does not need any survey data for training. Yet, on validation against actual survey data, proxy ratings yield reasonable performance results. Additionally, we offer a new way to draw insights from values of the value function, which allow associating specific interactions to their proxy ratings. We introduce two new metrics to represent ratings - one, customer-level and the other, aggregate-level for click actions across customers. Both are defined around proportion of all pairwise, successive actions that show increase in proxy ratings. This intuitive customer-level metric enables gauging the dynamics of ratings over time and is a better predictor of purchase than customer ratings from survey. The aggregate-level metric allows pinpointing actions that help or hurt experience. In sum, proxy ratings computed unobtrusively from clickstream, for every action, for each customer, and for every session can offer interpretable and more insightful alternative to surveys.
* The Thirty-Third AAAI Conference on Artificial Intelligence (AAAI-19)
Forecasting Granular Audience Size for Online Advertising
Jan 08, 2019
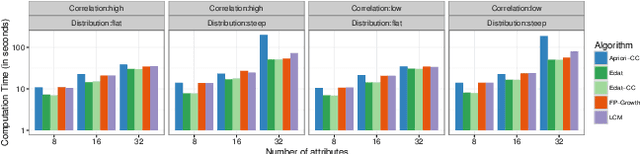
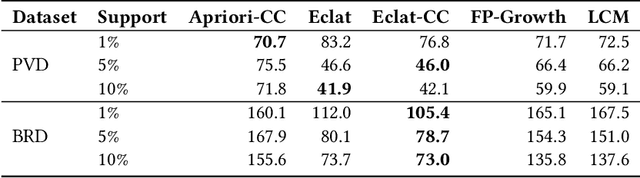
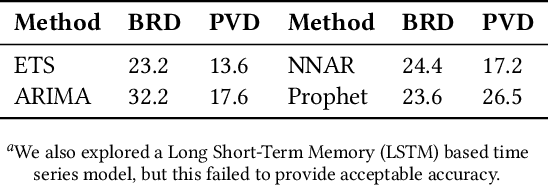
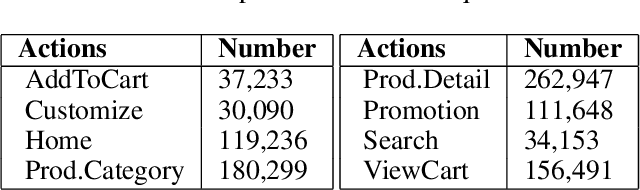
Orchestration of campaigns for online display advertising requires marketers to forecast audience size at the granularity of specific attributes of web traffic, characterized by the categorical nature of all attributes (e.g. {US, Chrome, Mobile}). With each attribute taking many values, the very large attribute combination set makes estimating audience size for any specific attribute combination challenging. We modify Eclat, a frequent itemset mining (FIM) algorithm, to accommodate categorical variables. For consequent frequent and infrequent itemsets, we then provide forecasts using time series analysis with conditional probabilities to aid approximation. An extensive simulation, based on typical characteristics of audience data, is built to stress test our modified-FIM approach. In two real datasets, comparison with baselines including neural network models, shows that our method lowers computation time of FIM for categorical data. On hold out samples we show that the proposed forecasting method outperforms these baselines.