 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeElectra: Conditional Generative Model based Predicate-Aware Query Approximation
Jan 28, 2022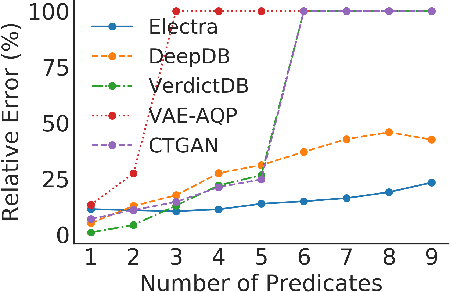
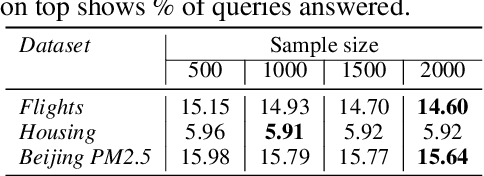
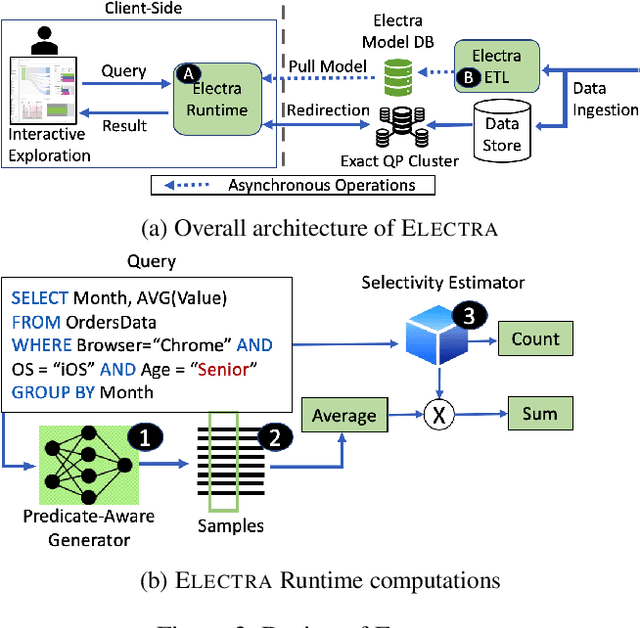
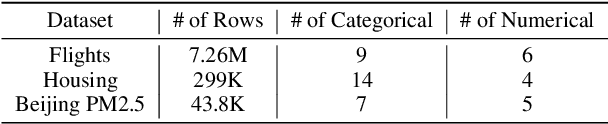
The goal of Approximate Query Processing (AQP) is to provide very fast but "accurate enough" results for costly aggregate queries thereby improving user experience in interactive exploration of large datasets. Recently proposed Machine-Learning based AQP techniques can provide very low latency as query execution only involves model inference as compared to traditional query processing on database clusters. However, with increase in the number of filtering predicates(WHERE clauses), the approximation error significantly increases for these methods. Analysts often use queries with a large number of predicates for insights discovery. Thus, maintaining low approximation error is important to prevent analysts from drawing misleading conclusions. In this paper, we propose ELECTRA, a predicate-aware AQP system that can answer analytics-style queries with a large number of predicates with much smaller approximation errors. ELECTRA uses a conditional generative model that learns the conditional distribution of the data and at runtime generates a small (~1000 rows) but representative sample, on which the query is executed to compute the approximate result. Our evaluations with four different baselines on three real-world datasets show that ELECTRA provides lower AQP error for large number of predicates compared to baselines.
Surveys without Questions: A Reinforcement Learning Approach
Jun 11, 2020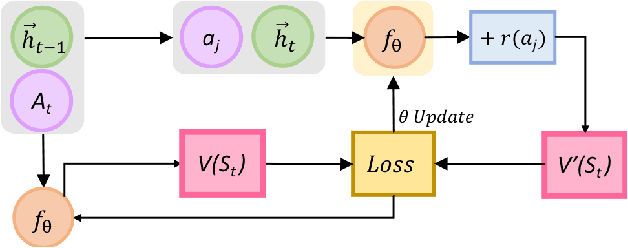
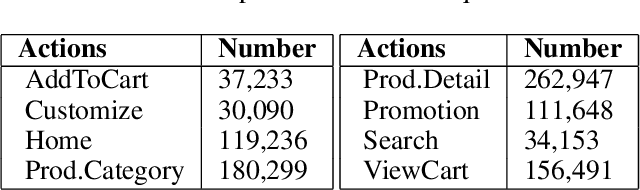

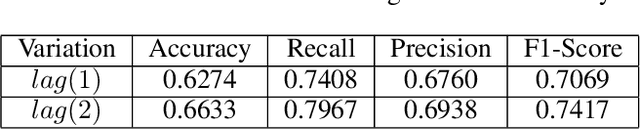
The 'old world' instrument, survey, remains a tool of choice for firms to obtain ratings of satisfaction and experience that customers realize while interacting online with firms. While avenues for survey have evolved from emails and links to pop-ups while browsing, the deficiencies persist. These include - reliance on ratings of very few respondents to infer about all customers' online interactions; failing to capture a customer's interactions over time since the rating is a one-time snapshot; and inability to tie back customers' ratings to specific interactions because ratings provided relate to all interactions. To overcome these deficiencies we extract proxy ratings from clickstream data, typically collected for every customer's online interactions, by developing an approach based on Reinforcement Learning (RL). We introduce a new way to interpret values generated by the value function of RL, as proxy ratings. Our approach does not need any survey data for training. Yet, on validation against actual survey data, proxy ratings yield reasonable performance results. Additionally, we offer a new way to draw insights from values of the value function, which allow associating specific interactions to their proxy ratings. We introduce two new metrics to represent ratings - one, customer-level and the other, aggregate-level for click actions across customers. Both are defined around proportion of all pairwise, successive actions that show increase in proxy ratings. This intuitive customer-level metric enables gauging the dynamics of ratings over time and is a better predictor of purchase than customer ratings from survey. The aggregate-level metric allows pinpointing actions that help or hurt experience. In sum, proxy ratings computed unobtrusively from clickstream, for every action, for each customer, and for every session can offer interpretable and more insightful alternative to surveys.
* The Thirty-Third AAAI Conference on Artificial Intelligence (AAAI-19)
DeepPlace: Learning to Place Applications in Multi-Tenant Clusters
Jul 30, 2019
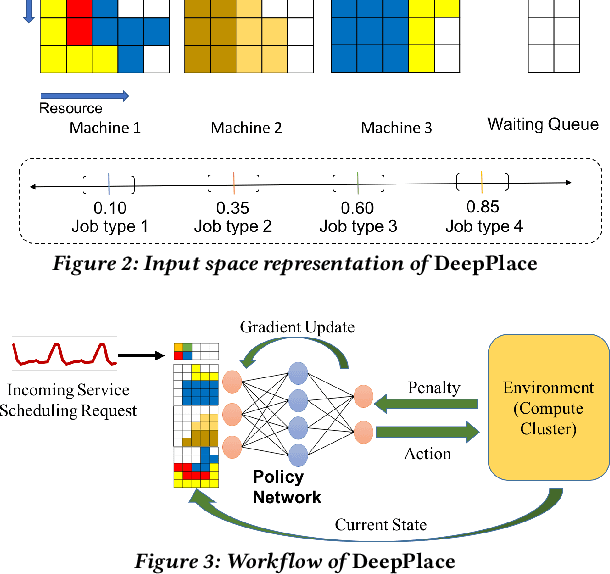
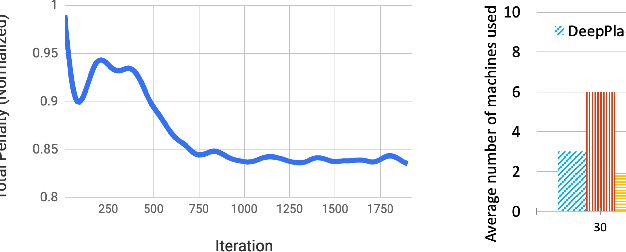
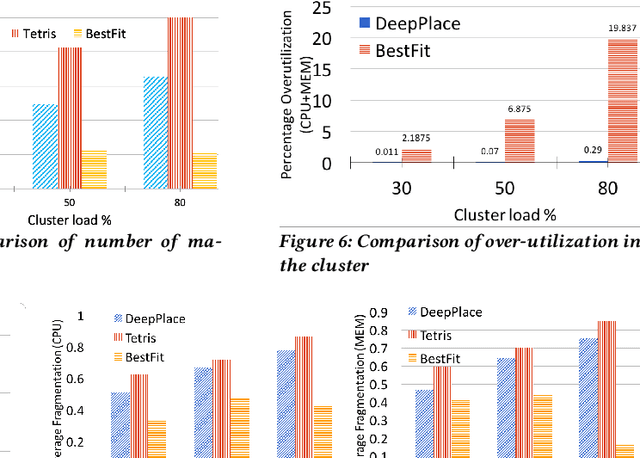
Large multi-tenant production clusters often have to handle a variety of jobs and applications with a variety of complex resource usage characteristics. It is non-trivial and non-optimal to manually create placement rules for scheduling that would decide which applications should co-locate. In this paper, we present DeepPlace, a scheduler that learns to exploits various temporal resource usage patterns of applications using Deep Reinforcement Learning (Deep RL) to reduce resource competition across jobs running in the same machine while at the same time optimizing for overall cluster utilization.