 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSlot Abstractors: Toward Scalable Abstract Visual Reasoning
Mar 06, 2024



Abstract visual reasoning is a characteristically human ability, allowing the identification of relational patterns that are abstracted away from object features, and the systematic generalization of those patterns to unseen problems. Recent work has demonstrated strong systematic generalization in visual reasoning tasks involving multi-object inputs, through the integration of slot-based methods used for extracting object-centric representations coupled with strong inductive biases for relational abstraction. However, this approach was limited to problems containing a single rule, and was not scalable to visual reasoning problems containing a large number of objects. Other recent work proposed Abstractors, an extension of Transformers that incorporates strong relational inductive biases, thereby inheriting the Transformer's scalability and multi-head architecture, but it has yet to be demonstrated how this approach might be applied to multi-object visual inputs. Here we combine the strengths of the above approaches and propose Slot Abstractors, an approach to abstract visual reasoning that can be scaled to problems involving a large number of objects and multiple relations among them. The approach displays state-of-the-art performance across four abstract visual reasoning tasks.
A Prefrontal Cortex-inspired Architecture for Planning in Large Language Models
Sep 30, 2023Large language models (LLMs) demonstrate impressive performance on a wide variety of tasks, but they often struggle with tasks that require multi-step reasoning or goal-directed planning. To address this, we take inspiration from the human brain, in which planning is accomplished via the recurrent interaction of specialized modules in the prefrontal cortex (PFC). These modules perform functions such as conflict monitoring, state prediction, state evaluation, task decomposition, and task coordination. We find that LLMs are sometimes capable of carrying out these functions in isolation, but struggle to autonomously coordinate them in the service of a goal. Therefore, we propose a black box architecture with multiple LLM-based (GPT-4) modules. The architecture improves planning through the interaction of specialized PFC-inspired modules that break down a larger problem into multiple brief automated calls to the LLM. We evaluate the combined architecture on two challenging planning tasks -- graph traversal and Tower of Hanoi -- finding that it yields significant improvements over standard LLM methods (e.g., zero-shot prompting or in-context learning). These results demonstrate the benefit of utilizing knowledge from cognitive neuroscience to improve planning in LLMs.
Systematic Visual Reasoning through Object-Centric Relational Abstraction
Jun 04, 2023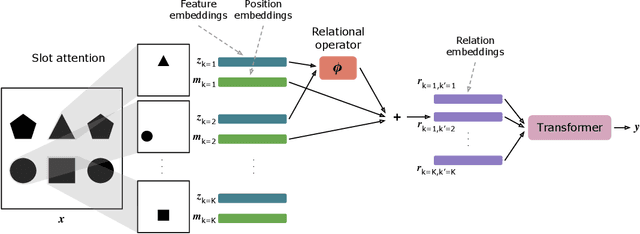



Human visual reasoning is characterized by an ability to identify abstract patterns from only a small number of examples, and to systematically generalize those patterns to novel inputs. This capacity depends in large part on our ability to represent complex visual inputs in terms of both objects and relations. Recent work in computer vision has introduced models with the capacity to extract object-centric representations, leading to the ability to process multi-object visual inputs, but falling short of the systematic generalization displayed by human reasoning. Other recent models have employed inductive biases for relational abstraction to achieve systematic generalization of learned abstract rules, but have generally assumed the presence of object-focused inputs. Here, we combine these two approaches, introducing Object-Centric Relational Abstraction (OCRA), a model that extracts explicit representations of both objects and abstract relations, and achieves strong systematic generalization in tasks involving complex visual displays.
Determinantal Point Process Attention Over Grid Codes Supports Out of Distribution Generalization
May 28, 2023



Deep neural networks have made tremendous gains in emulating human-like intelligence, and have been used increasingly as ways of understanding how the brain may solve the complex computational problems on which this relies. However, these still fall short of, and therefore fail to provide insight into how the brain supports strong forms of generalization of which humans are capable. One such case is out-of-distribution (OOD) generalization -- successful performance on test examples that lie outside the distribution of the training set. Here, we identify properties of processing in the brain that may contribute to this ability. We describe a two-part algorithm that draws on specific features of neural computation to achieve OOD generalization, and provide a proof of concept by evaluating performance on two challenging cognitive tasks. First we draw on the fact that the mammalian brain represents metric spaces using grid-like representations (e.g., in entorhinal cortex): abstract representations of relational structure, organized in recurring motifs that cover the representational space. Second, we propose an attentional mechanism that operates over these grid representations using determinantal point process (DPP-A) -- a transformation that ensures maximum sparseness in the coverage of that space. We show that a loss function that combines standard task-optimized error with DPP-A can exploit the recurring motifs in grid codes, and can be integrated with common architectures to achieve strong OOD generalization performance on analogy and arithmetic tasks. This provides both an interpretation of how grid codes in the mammalian brain may contribute to generalization performance, and at the same time a potential means for improving such capabilities in artificial neural networks.
Learning to reason over visual objects
Mar 03, 2023



A core component of human intelligence is the ability to identify abstract patterns inherent in complex, high-dimensional perceptual data, as exemplified by visual reasoning tasks such as Raven's Progressive Matrices (RPM). Motivated by the goal of designing AI systems with this capacity, recent work has focused on evaluating whether neural networks can learn to solve RPM-like problems. Previous work has generally found that strong performance on these problems requires the incorporation of inductive biases that are specific to the RPM problem format, raising the question of whether such models might be more broadly useful. Here, we investigated the extent to which a general-purpose mechanism for processing visual scenes in terms of objects might help promote abstract visual reasoning. We found that a simple model, consisting only of an object-centric encoder and a transformer reasoning module, achieved state-of-the-art results on both of two challenging RPM-like benchmarks (PGM and I-RAVEN), as well as a novel benchmark with greater visual complexity (CLEVR-Matrices). These results suggest that an inductive bias for object-centric processing may be a key component of abstract visual reasoning, obviating the need for problem-specific inductive biases.
DeepPlace: Learning to Place Applications in Multi-Tenant Clusters
Jul 30, 2019
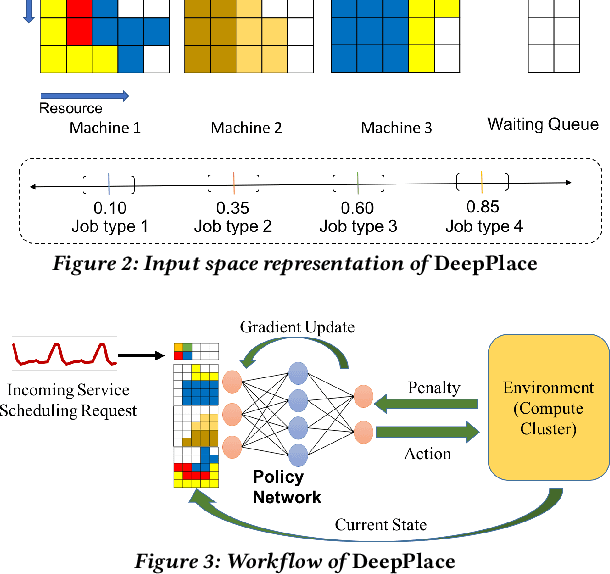
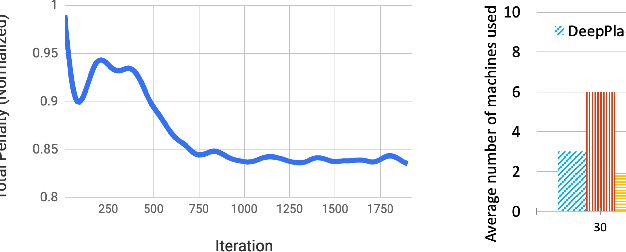
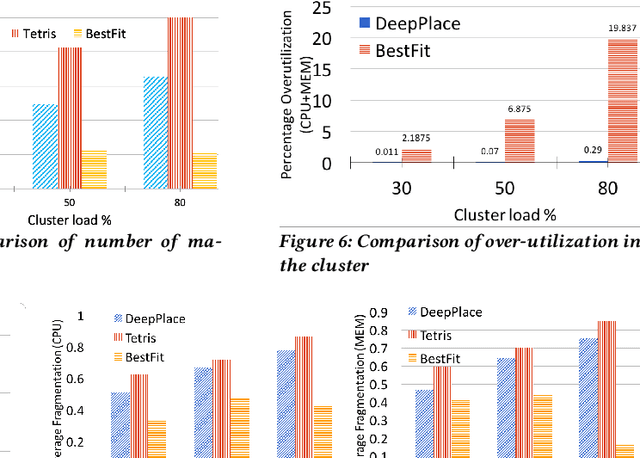
Large multi-tenant production clusters often have to handle a variety of jobs and applications with a variety of complex resource usage characteristics. It is non-trivial and non-optimal to manually create placement rules for scheduling that would decide which applications should co-locate. In this paper, we present DeepPlace, a scheduler that learns to exploits various temporal resource usage patterns of applications using Deep Reinforcement Learning (Deep RL) to reduce resource competition across jobs running in the same machine while at the same time optimizing for overall cluster utilization.
Investment Ranking Challenge: Identifying the best performing stocks based on their semi-annual returns
Jun 20, 2019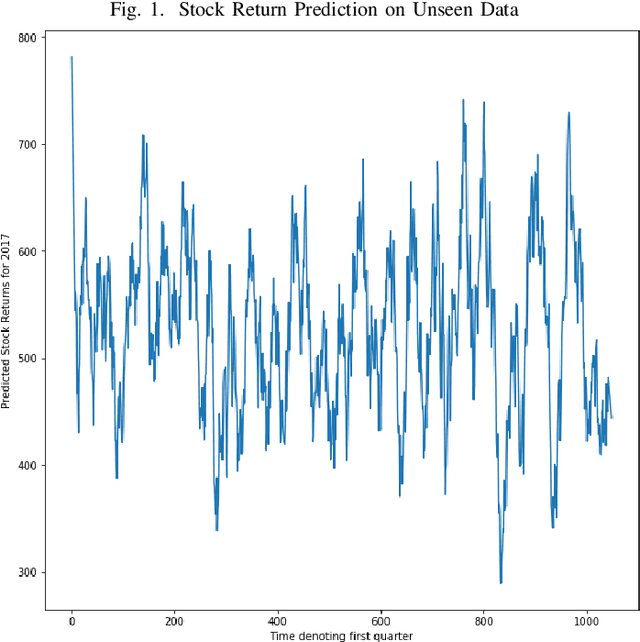
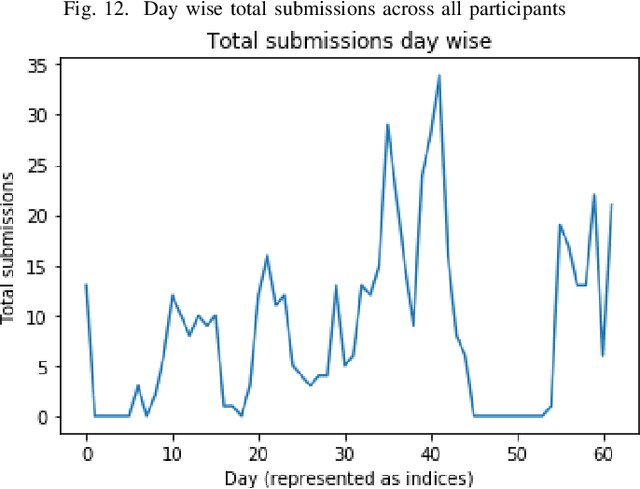
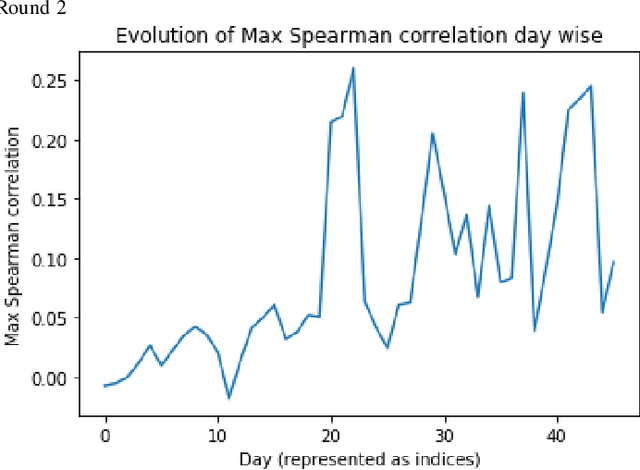
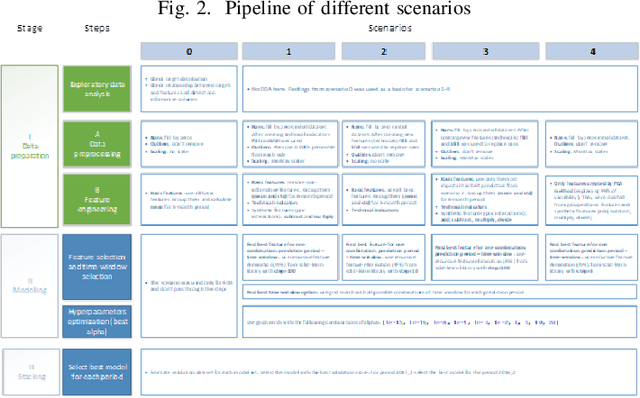
In the IEEE Investment ranking challenge 2018, participants were asked to build a model which would identify the best performing stocks based on their returns over a forward six months window. Anonymized financial predictors and semi-annual returns were provided for a group of anonymized stocks from 1996 to 2017, which were divided into 42 non-overlapping six months period. The second half of 2017 was used as an out-of-sample test of the model's performance. Metrics used were Spearman's Rank Correlation Coefficient and Normalized Discounted Cumulative Gain (NDCG) of the top 20% of a model's predicted rankings. The top six participants were invited to describe their approach. The solutions used were varied and were based on selecting a subset of data to train, combination of deep and shallow neural networks, different boosting algorithms, different models with different sets of features, linear support vector machine, combination of convoltional neural network (CNN) and Long short term memory (LSTM).
KarNet: An Efficient Boolean Function Simplifier
Jun 04, 2019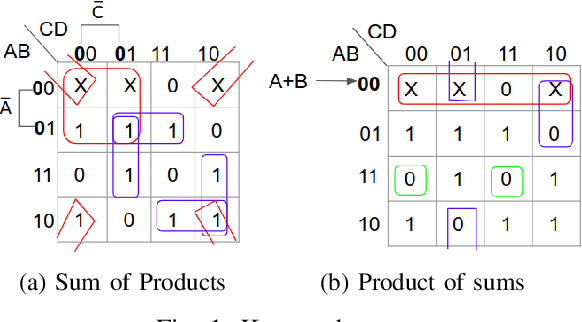
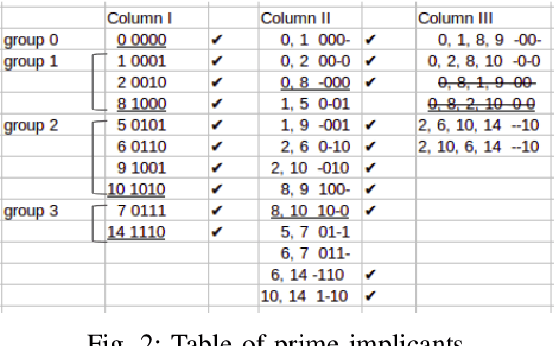
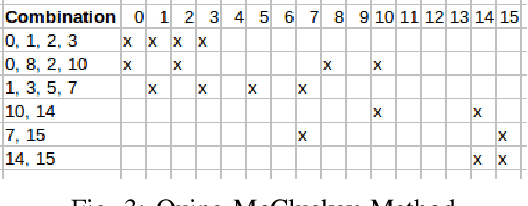
Many approaches such as Quine-McCluskey algorithm, Karnaugh map solving, Petrick's method and McBoole's method have been devised to simplify Boolean expressions in order to optimize hardware implementation of digital circuits. However, the algorithmic implementations of these methods are hard-coded and also their computation time is proportional to the number of minterms involved in the expression. In this paper, we propose KarNet, where the ability of Convolutional Neural Networks to model relationships between various cell locations and values by capturing spatial dependencies is exploited to solve Karnaugh maps. In order to do so, a Karnaugh map is represented as an image signal, where each cell is considered as a pixel. Experimental results show that the computation time of KarNet is independent of the number of minterms and is of the order of one-hundredth to one-tenth that of the rule-based methods. KarNet being a learned system is found to achieve nearly a hundred percent accuracy, precision, and recall. We train KarNet to solve four variable Karnaugh maps and also show that a similar method can be applied on Karnaugh maps with more variables. Finally, we show a way to build a fully accurate and computationally fast system using KarNet.
Multitask Learning of Temporal Connectionism in Convolutional Networks using a Joint Distribution Loss Function to Simultaneously Identify Tools and Phase in Surgical Videos
May 25, 2019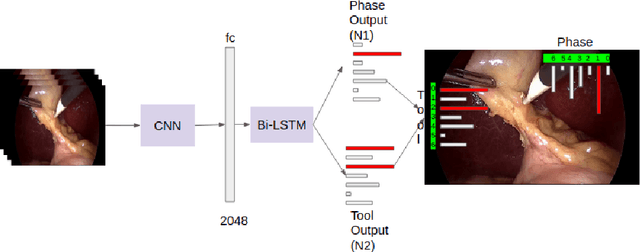
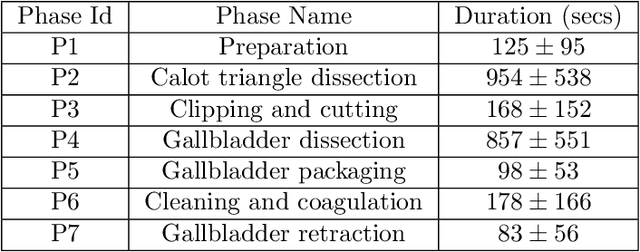
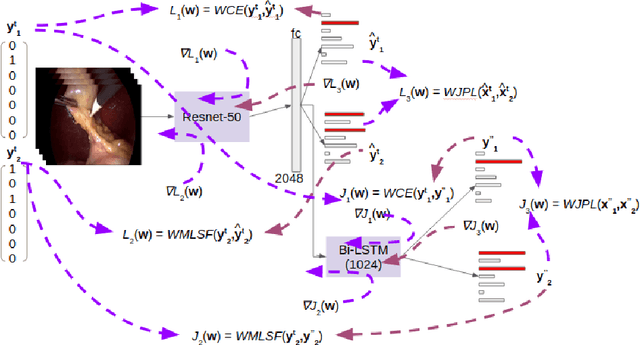
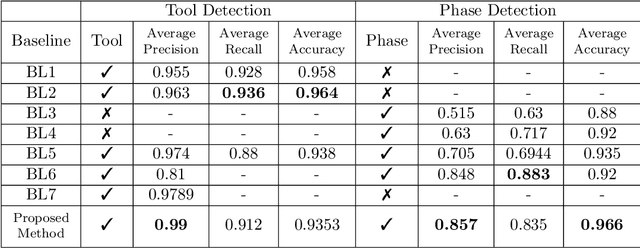
Surgical workflow analysis is of importance for understanding onset and persistence of surgical phases and individual tool usage across surgery and in each phase. It is beneficial for clinical quality control and to hospital administrators for understanding surgery planning. Video acquired during surgery typically can be leveraged for this task. Currently, a combination of convolutional neural network (CNN) and recurrent neural networks (RNN) are popularly used for video analysis in general, not only being restricted to surgical videos. In this paper, we propose a multi-task learning framework using CNN followed by a bi-directional long short term memory (Bi-LSTM) to learn to encapsulate both forward and backward temporal dependencies. Further, the joint distribution indicating set of tools associated with a phase is used as an additional loss during learning to correct for their co-occurrence in any predictions. Experimental evaluation is performed using the Cholec80 dataset. We report a mean average precision (mAP) score of 0.99 and 0.86 for tool and phase identification respectively which are higher compared to prior-art in the field.