 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestment Ranking Challenge: Identifying the best performing stocks based on their semi-annual returns
Jun 20, 2019
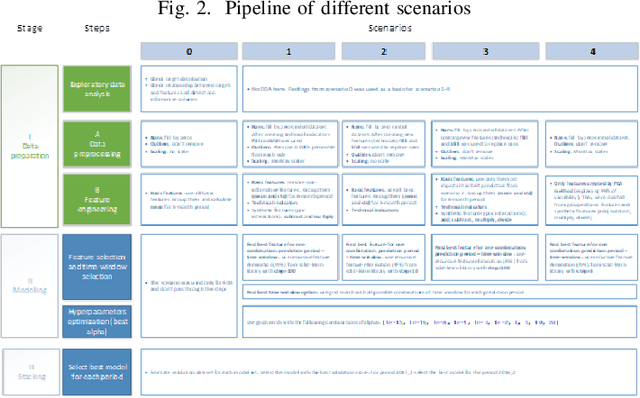
In the IEEE Investment ranking challenge 2018, participants were asked to build a model which would identify the best performing stocks based on their returns over a forward six months window. Anonymized financial predictors and semi-annual returns were provided for a group of anonymized stocks from 1996 to 2017, which were divided into 42 non-overlapping six months period. The second half of 2017 was used as an out-of-sample test of the model's performance. Metrics used were Spearman's Rank Correlation Coefficient and Normalized Discounted Cumulative Gain (NDCG) of the top 20% of a model's predicted rankings. The top six participants were invited to describe their approach. The solutions used were varied and were based on selecting a subset of data to train, combination of deep and shallow neural networks, different boosting algorithms, different models with different sets of features, linear support vector machine, combination of convoltional neural network (CNN) and Long short term memory (LSTM).
Using Deep Learning for Image-Based Plant Disease Detection
Apr 15, 2016

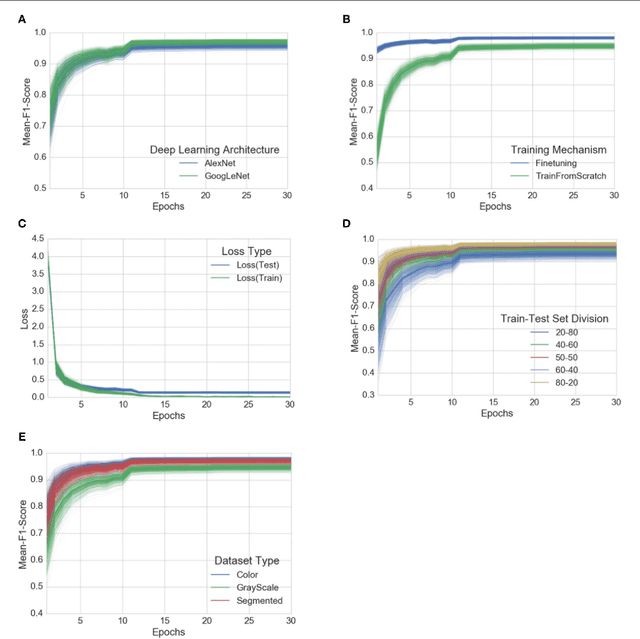
Crop diseases are a major threat to food security, but their rapid identification remains difficult in many parts of the world due to the lack of the necessary infrastructure. The combination of increasing global smartphone penetration and recent advances in computer vision made possible by deep learning has paved the way for smartphone-assisted disease diagnosis. Using a public dataset of 54,306 images of diseased and healthy plant leaves collected under controlled conditions, we train a deep convolutional neural network to identify 14 crop species and 26 diseases (or absence thereof). The trained model achieves an accuracy of 99.35% on a held-out test set, demonstrating the feasibility of this approach. When testing the model on a set of images collected from trusted online sources - i.e. taken under conditions different from the images used for training - the model still achieves an accuracy of 31.4%. While this accuracy is much higher than the one based on random selection (2.6%), a more diverse set of training data is needed to improve the general accuracy. Overall, the approach of training deep learning models on increasingly large and publicly available image datasets presents a clear path towards smartphone-assisted crop disease diagnosis on a massive global scale.
Targeting HIV-related Medication Side Effects and Sentiment Using Twitter Data
Apr 11, 2014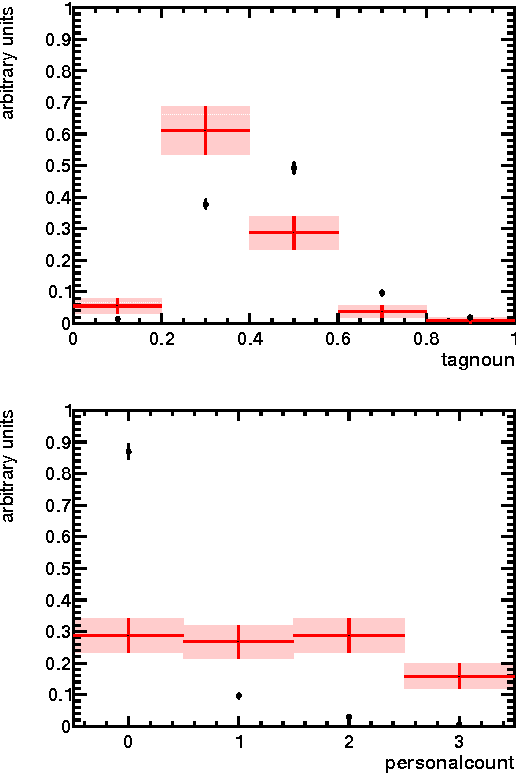

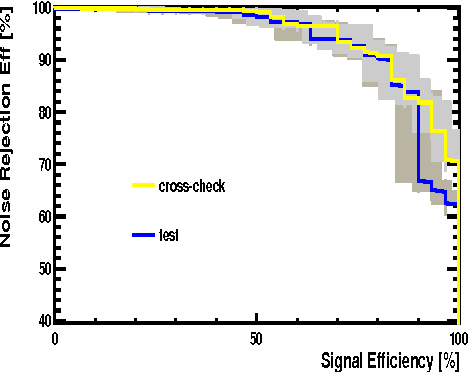
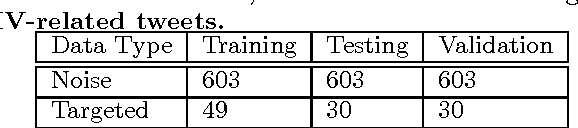
We present a descriptive analysis of Twitter data. Our study focuses on extracting the main side effects associated with HIV treatments. The crux of our work was the identification of personal tweets referring to HIV. We summarize our results in an infographic aimed at the general public. In addition, we present a measure of user sentiment based on hand-rated tweets.