 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Food Recognition Benchmark: Using DeepLearning to Recognize Food on Images
Jun 30, 2021

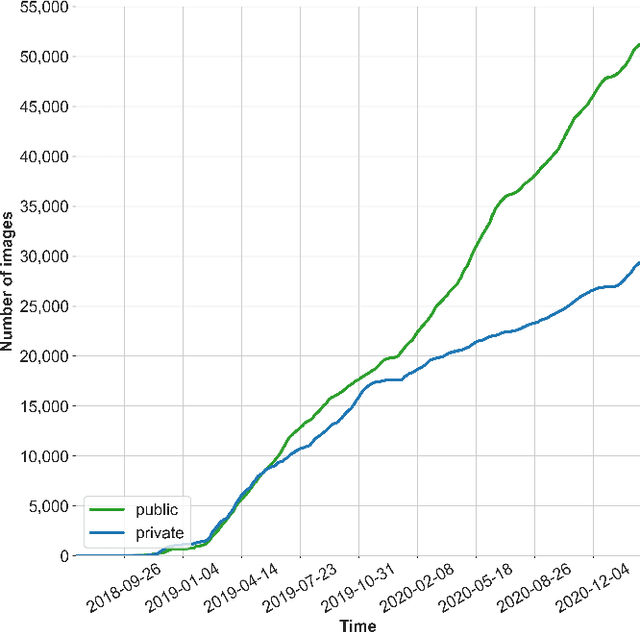
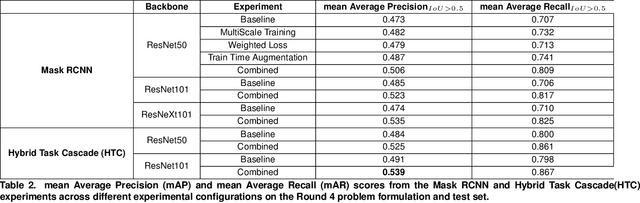
The automatic recognition of food on images has numerous interesting applications, including nutritional tracking in medical cohorts. The problem has received significant research attention, but an ongoing public benchmark to develop open and reproducible algorithms has been missing. Here, we report on the setup of such a benchmark using publicly available food images sourced through the mobile MyFoodRepo app. Through four rounds, the benchmark released the MyFoodRepo-273 dataset constituting 24,119 images and a total of 39,325 segmented polygons categorized in 273 different classes. Models were evaluated on private tests sets from the same platform with 5,000 images and 7,865 annotations in the final round. Top-performing models on the 273 food categories reached a mean average precision of 0.568 (round 4) and a mean average recall of 0.885 (round 3). We present experimental validation of round 4 results, and discuss implications of the benchmark setup designed to increase the size and diversity of the dataset for future rounds.
Investment Ranking Challenge: Identifying the best performing stocks based on their semi-annual returns
Jun 20, 2019
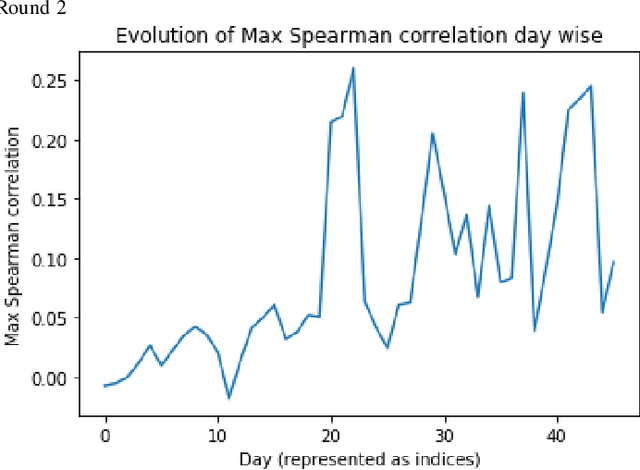
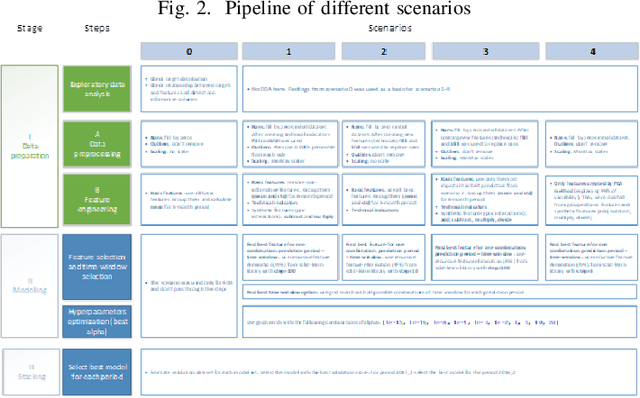
In the IEEE Investment ranking challenge 2018, participants were asked to build a model which would identify the best performing stocks based on their returns over a forward six months window. Anonymized financial predictors and semi-annual returns were provided for a group of anonymized stocks from 1996 to 2017, which were divided into 42 non-overlapping six months period. The second half of 2017 was used as an out-of-sample test of the model's performance. Metrics used were Spearman's Rank Correlation Coefficient and Normalized Discounted Cumulative Gain (NDCG) of the top 20% of a model's predicted rankings. The top six participants were invited to describe their approach. The solutions used were varied and were based on selecting a subset of data to train, combination of deep and shallow neural networks, different boosting algorithms, different models with different sets of features, linear support vector machine, combination of convoltional neural network (CNN) and Long short term memory (LSTM).
Artificial Intelligence for Prosthetics - challenge solutions
Feb 07, 2019
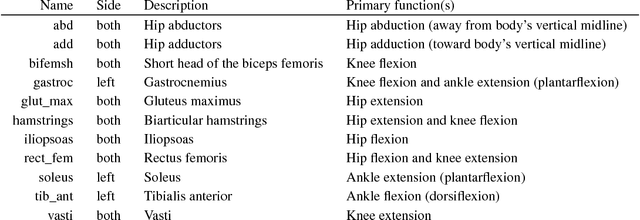
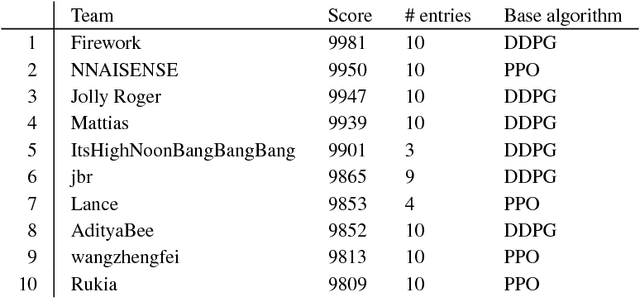

In the NeurIPS 2018 Artificial Intelligence for Prosthetics challenge, participants were tasked with building a controller for a musculoskeletal model with a goal of matching a given time-varying velocity vector. Top participants were invited to describe their algorithms. In this work, we describe the challenge and present thirteen solutions that used deep reinforcement learning approaches. Many solutions use similar relaxations and heuristics, such as reward shaping, frame skipping, discretization of the action space, symmetry, and policy blending. However, each team implemented different modifications of the known algorithms by, for example, dividing the task into subtasks, learning low-level control, or by incorporating expert knowledge and using imitation learning.
The Multi-Agent Reinforcement Learning in MalmÖ (MARLÖ) Competition
Jan 23, 2019Learning in multi-agent scenarios is a fruitful research direction, but current approaches still show scalability problems in multiple games with general reward settings and different opponent types. The Multi-Agent Reinforcement Learning in Malm\"O (MARL\"O) competition is a new challenge that proposes research in this domain using multiple 3D games. The goal of this contest is to foster research in general agents that can learn across different games and opponent types, proposing a challenge as a milestone in the direction of Artificial General Intelligence.
* 2 pages plus references
Learning to Run challenge solutions: Adapting reinforcement learning methods for neuromusculoskeletal environments
Apr 02, 2018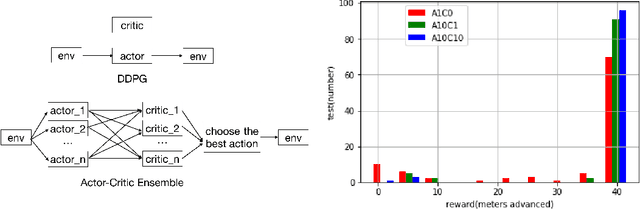

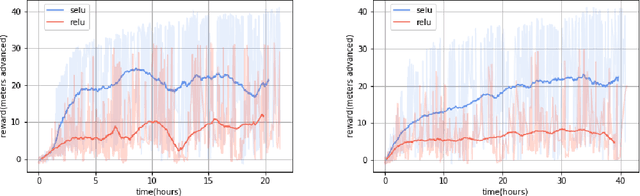
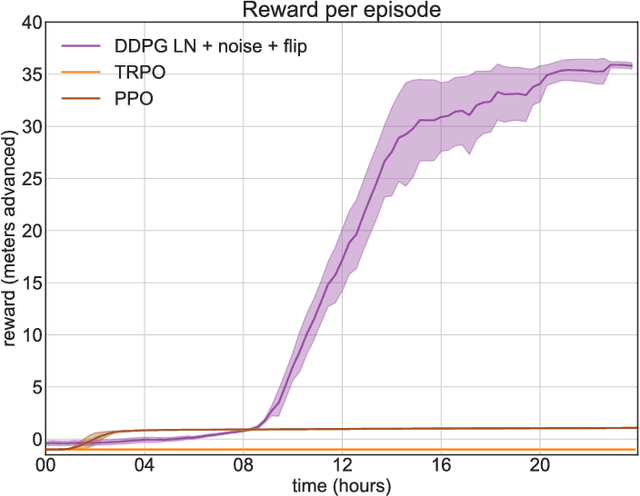
In the NIPS 2017 Learning to Run challenge, participants were tasked with building a controller for a musculoskeletal model to make it run as fast as possible through an obstacle course. Top participants were invited to describe their algorithms. In this work, we present eight solutions that used deep reinforcement learning approaches, based on algorithms such as Deep Deterministic Policy Gradient, Proximal Policy Optimization, and Trust Region Policy Optimization. Many solutions use similar relaxations and heuristics, such as reward shaping, frame skipping, discretization of the action space, symmetry, and policy blending. However, each of the eight teams implemented different modifications of the known algorithms.
Using Deep Learning for Image-Based Plant Disease Detection
Apr 15, 2016

Crop diseases are a major threat to food security, but their rapid identification remains difficult in many parts of the world due to the lack of the necessary infrastructure. The combination of increasing global smartphone penetration and recent advances in computer vision made possible by deep learning has paved the way for smartphone-assisted disease diagnosis. Using a public dataset of 54,306 images of diseased and healthy plant leaves collected under controlled conditions, we train a deep convolutional neural network to identify 14 crop species and 26 diseases (or absence thereof). The trained model achieves an accuracy of 99.35% on a held-out test set, demonstrating the feasibility of this approach. When testing the model on a set of images collected from trusted online sources - i.e. taken under conditions different from the images used for training - the model still achieves an accuracy of 31.4%. While this accuracy is much higher than the one based on random selection (2.6%), a more diverse set of training data is needed to improve the general accuracy. Overall, the approach of training deep learning models on increasingly large and publicly available image datasets presents a clear path towards smartphone-assisted crop disease diagnosis on a massive global scale.