 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Code to Play: Benchmarking Program Search for Games Using Large Language Models
Dec 05, 2024



Large language models (LLMs) have shown impressive capabilities in generating program code, opening exciting opportunities for applying program synthesis to games. In this work, we explore the potential of LLMs to directly synthesize usable code for a wide range of gaming applications, focusing on two programming languages, Python and Java. We use an evolutionary hill-climbing algorithm, where the mutations and seeds of the initial programs are controlled by LLMs. For Python, the framework covers various game-related tasks, including five miniature versions of Atari games, ten levels of Baba is You, an environment inspired by Asteroids, and a maze generation task. For Java, the framework contains 12 games from the TAG tabletop games framework. Across 29 tasks, we evaluated 12 language models for Python and 8 for Java. Our findings suggest that the performance of LLMs depends more on the task than on model size. While larger models generate more executable programs, these do not always result in higher-quality solutions but are much more expensive. No model has a clear advantage, although on any specific task, one model may be better. Trying many models on a problem and using the best results across them is more reliable than using just one.
PyTAG: Tabletop Games for Multi-Agent Reinforcement Learning
May 28, 2024



Modern Tabletop Games present various interesting challenges for Multi-agent Reinforcement Learning. In this paper, we introduce PyTAG, a new framework that supports interacting with a large collection of games implemented in the Tabletop Games framework. In this work we highlight the challenges tabletop games provide, from a game-playing agent perspective, along with the opportunities they provide for future research. Additionally, we highlight the technical challenges that involve training Reinforcement Learning agents on these games. To explore the Multi-agent setting provided by PyTAG we train the popular Proximal Policy Optimisation Reinforcement Learning algorithm using self-play on a subset of games and evaluate the trained policies against some simple agents and Monte-Carlo Tree Search implemented in the Tabletop Games framework.
PyTAG: Challenges and Opportunities for Reinforcement Learning in Tabletop Games
Jul 19, 2023In recent years, Game AI research has made important breakthroughs using Reinforcement Learning (RL). Despite this, RL for modern tabletop games has gained little to no attention, even when they offer a range of unique challenges compared to video games. To bridge this gap, we introduce PyTAG, a Python API for interacting with the Tabletop Games framework (TAG). TAG contains a growing set of more than 20 modern tabletop games, with a common API for AI agents. We present techniques for training RL agents in these games and introduce baseline results after training Proximal Policy Optimisation algorithms on a subset of games. Finally, we discuss the unique challenges complex modern tabletop games provide, now open to RL research through PyTAG.
Design and Implementation of TAG: A Tabletop Games Framework
Sep 25, 2020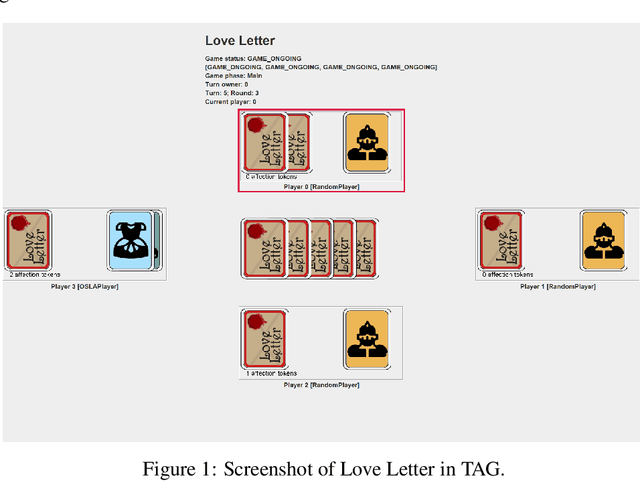
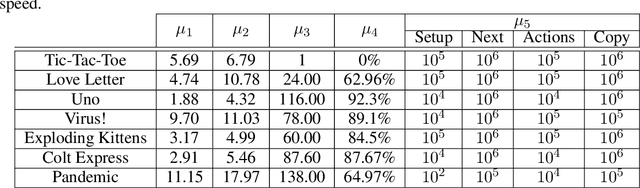
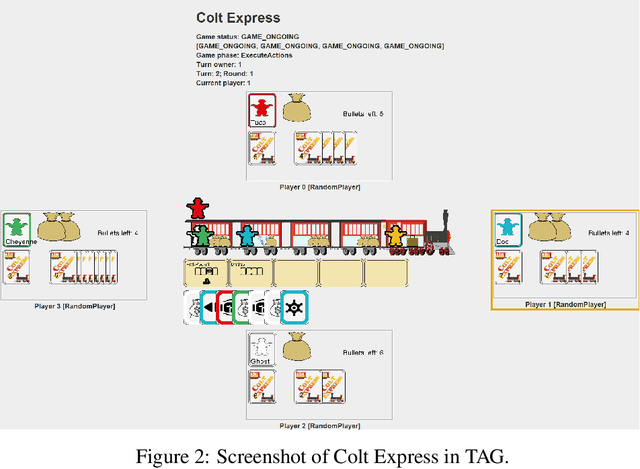
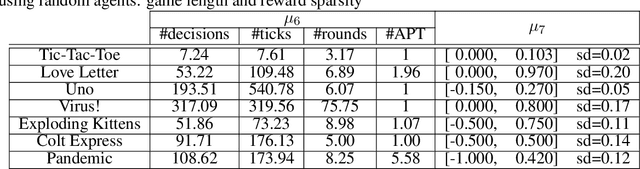
This document describes the design and implementation of the Tabletop Games framework (TAG), a Java-based benchmark for developing modern board games for AI research. TAG provides a common skeleton for implementing tabletop games based on a common API for AI agents, a set of components and classes to easily add new games and an import module for defining data in JSON format. At present, this platform includes the implementation of seven different tabletop games that can also be used as an example for further developments. Additionally, TAG also incorporates logging functionality that allows the user to perform a detailed analysis of the game, in terms of action space, branching factor, hidden information, and other measures of interest for Game AI research. The objective of this document is to serve as a central point where the framework can be described at length. TAG can be downloaded at: https://github.com/GAIGResearch/TabletopGames
Rolling Horizon NEAT for General Video Game Playing
May 14, 2020



This paper presents a new Statistical Forward Planning (SFP) method, Rolling Horizon NeuroEvolution of Augmenting Topologies (rhNEAT). Unlike traditional Rolling Horizon Evolution, where an evolutionary algorithm is in charge of evolving a sequence of actions, rhNEAT evolves weights and connections of a neural network in real-time, planning several steps ahead before returning an action to execute in the game. Different versions of the algorithm are explored in a collection of 20 GVGAI games, and compared with other SFP methods and state of the art results. Although results are overall not better than other SFP methods, the nature of rhNEAT to adapt to changing game features has allowed to establish new state of the art records in games that other methods have traditionally struggled with. The algorithm proposed here is general and introduces a new way of representing information within rolling horizon evolution techniques.
Rolling Horizon Evolutionary Algorithms for General Video Game Playing
Mar 27, 2020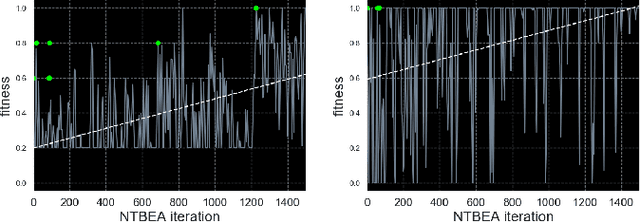
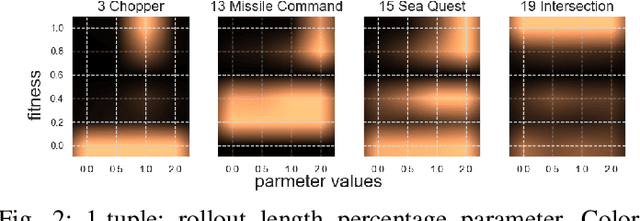
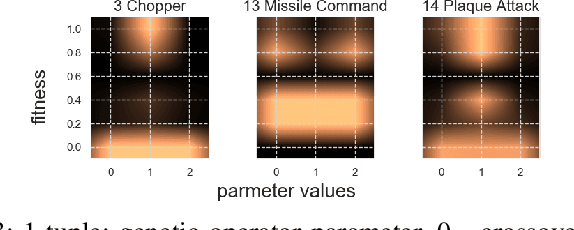
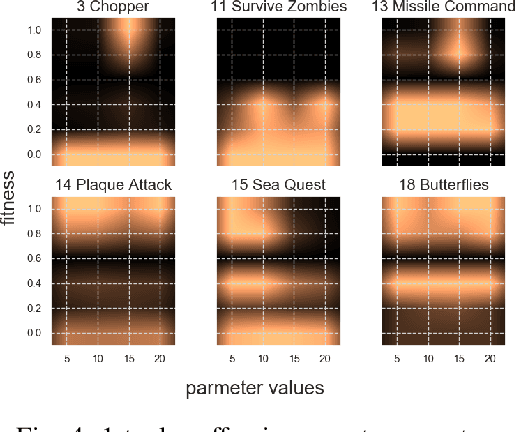
Game-playing Evolutionary Algorithms, specifically Rolling Horizon Evolutionary Algorithms, have recently managed to beat the state of the art in performance across many games. However, the best results per game are highly dependent on the specific configuration of modifications and hybrids introduced over several works, each described as parameters in the algorithm. However, the search for the best parameters has been reduced to several human-picked combinations, as the possibility space has grown beyond exhaustive search. This paper presents the state of the art in Rolling Horizon Evolutionary algorithms, combining all modifications described in literature and some additional ones for a large resultant hybrid. It then uses a parameter optimiser, the N-Tuple Bandit Evolutionary Algorithm, to find the best combination of parameters in 20 games with various properties from the General Video Game AI Framework. We highlight the noisy optimisation problem resultant, as both the games and the algorithm being optimised are stochastic. We then analyse the algorithm's parameters and interesting combinations revealed through the parameter optimisation process. Lastly, we show that it is possible to automatically explore a large parameter space and find configurations which outperform the state of the art on several games.
Learning Local Forward Models on Unforgiving Games
Sep 01, 2019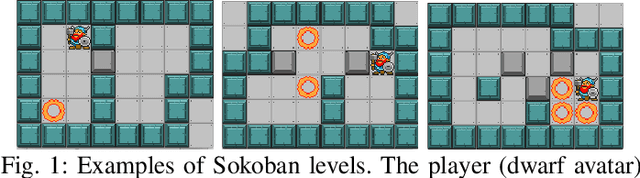
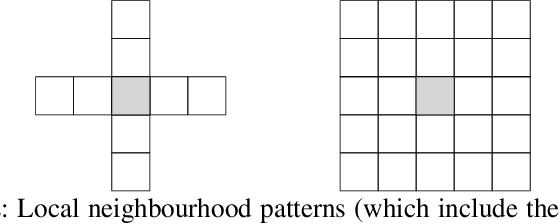


This paper examines learning approaches for forward models based on local cell transition functions. We provide a formal definition of local forward models for which we propose two basic learning approaches. Our analysis is based on the game Sokoban, where a wrong action can lead to an unsolvable game state. Therefore, an accurate prediction of an action's resulting state is necessary to avoid this scenario. In contrast to learning the complete state transition function, local forward models allow extracting multiple training examples from a single state transition. In this way, the Hash Set model, as well as the Decision Tree model, quickly learn to predict upcoming state transitions of both the training and the test set. Applying the model using a statistical forward planner showed that the best models can be used to satisfying degree even in cases in which the test levels have not yet been seen. Our evaluation includes an analysis of various local neighbourhood patterns and sizes to test the learners' capabilities in case too few or too many attributes are extracted, of which the latter has shown do degrade the performance of the model learner.
"Did You Hear That?" Learning to Play Video Games from Audio Cues
Jun 11, 2019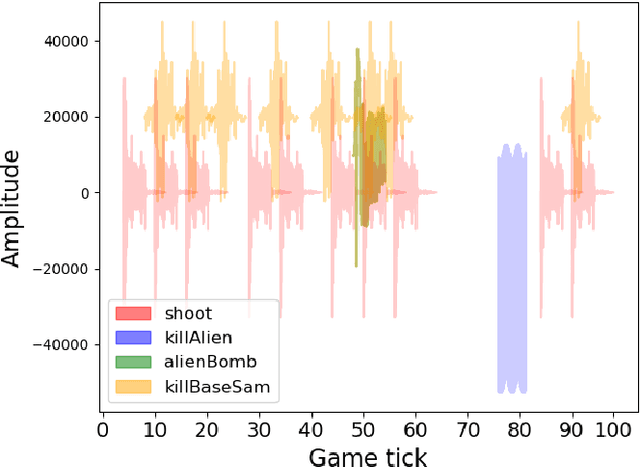
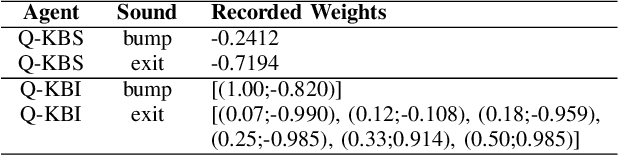
Game-playing AI research has focused for a long time on learning to play video games from visual input or symbolic information. However, humans benefit from a wider array of sensors which we utilise in order to navigate the world around us. In particular, sounds and music are key to how many of us perceive the world and influence the decisions we make. In this paper, we present initial experiments on game-playing agents learning to play video games solely from audio cues. We expand the Video Game Description Language to allow for audio specification, and the General Video Game AI framework to provide new audio games and an API for learning agents to make use of audio observations. We analyse the games and the audio game design process, include initial results with simple Q~Learning agents, and encourage further research in this area.
Project Thyia: A Forever Gameplayer
Jun 10, 2019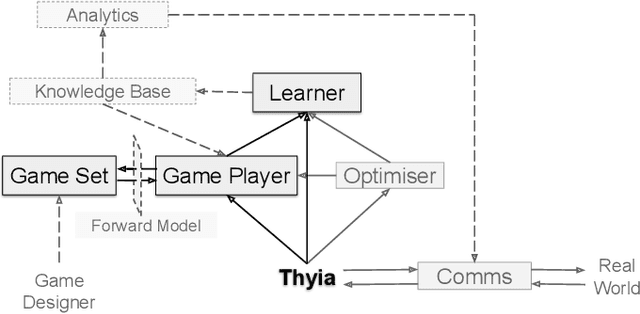
The space of Artificial Intelligence entities is dominated by conversational bots. Some of them fit in our pockets and we take them everywhere we go, or allow them to be a part of human homes. Siri, Alexa, they are recognised as present in our world. But a lot of games research is restricted to existing in the separate realm of software. We enter different worlds when playing games, but those worlds cease to exist once we quit. Similarly, AI game-players are run once on a game (or maybe for longer periods of time, in the case of learning algorithms which need some, still limited, period for training), and they cease to exist once the game ends. But what if they didn't? What if there existed artificial game-players that continuously played games, learned from their experiences and kept getting better? What if they interacted with the real world and us, humans: live-streaming games, chatting with viewers, accepting suggestions for strategies or games to play, forming opinions on popular game titles? In this paper, we introduce the vision behind a new project called Thyia, which focuses around creating a present, continuous, `always-on', interactive game-player.
A Local Approach to Forward Model Learning: Results on the Game of Life Game
Mar 29, 2019
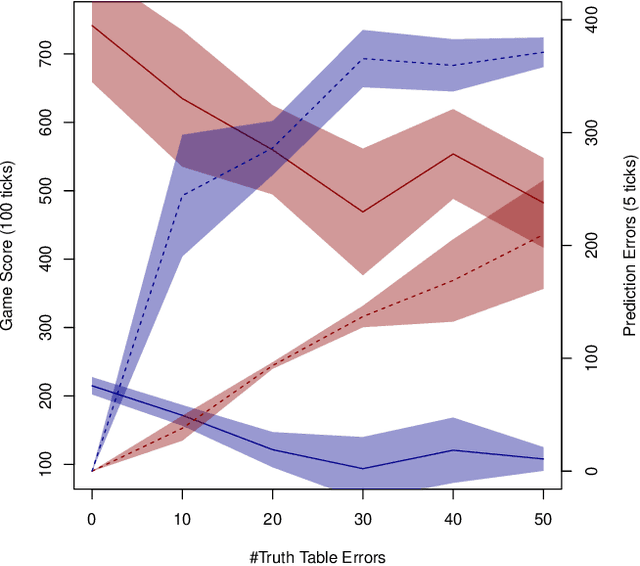
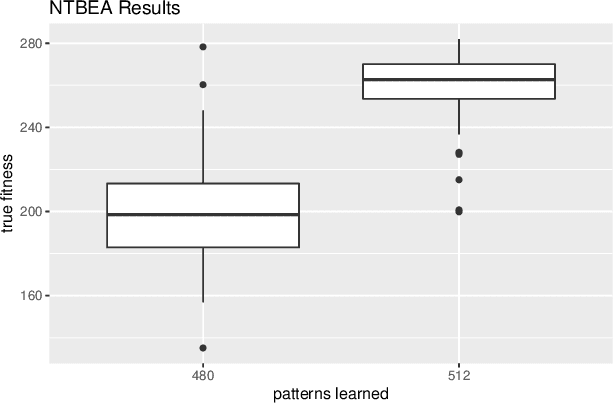
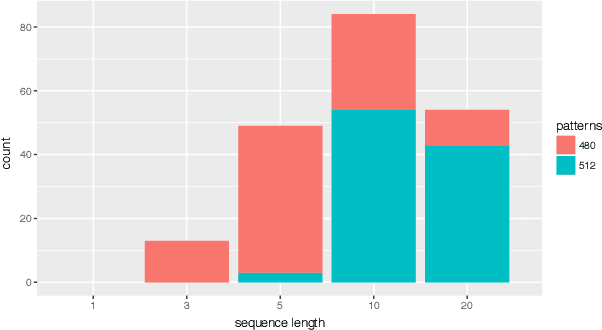
This paper investigates the effect of learning a forward model on the performance of a statistical forward planning agent. We transform Conway's Game of Life simulation into a single-player game where the objective can be either to preserve as much life as possible or to extinguish all life as quickly as possible. In order to learn the forward model of the game, we formulate the problem in a novel way that learns the local cell transition function by creating a set of supervised training data and predicting the next state of each cell in the grid based on its current state and immediate neighbours. Using this method we are able to harvest sufficient data to learn perfect forward models by observing only a few complete state transitions, using either a look-up table, a decision tree or a neural network. In contrast, learning the complete state transition function is a much harder task and our initial efforts to do this using deep convolutional auto-encoders were less successful. We also investigate the effects of imperfect learned models on prediction errors and game-playing performance, and show that even models with significant errors can provide good performance.