 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRinascimento: searching the behaviour space of Splendor
Jun 15, 2021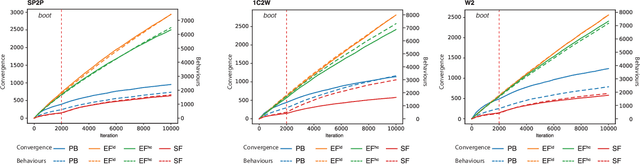
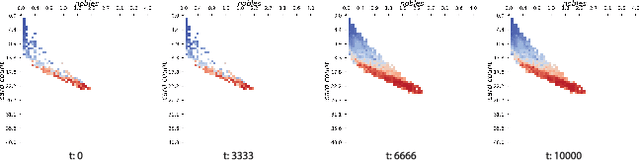

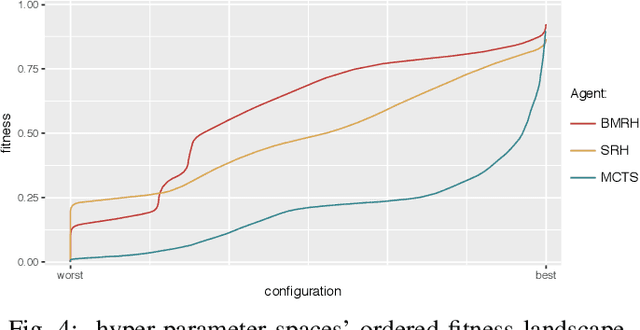
The use of Artificial Intelligence (AI) for play-testing is still on the sidelines of main applications of AI in games compared to performance-oriented game-playing. One of the main purposes of play-testing a game is gathering data on the gameplay, highlighting good and bad features of the design of the game, providing useful insight to the game designers for improving the design. Using AI agents has the potential of speeding the process dramatically. The purpose of this research is to map the behavioural space (BSpace) of a game by using a general method. Using the MAP-Elites algorithm we search the hyperparameter space Rinascimento AI agents and map it to the BSpace defined by several behavioural metrics. This methodology was able to highlight both exemplary and degenerated behaviours in the original game design of Splendor and two variations. In particular, the use of event-value functions has generally shown a remarkable improvement in the coverage of the BSpace compared to agents based on classic score-based reward signals.
Rinascimento: using event-value functions for playing Splendor
Jun 10, 2020



In the realm of games research, Artificial General Intelligence algorithms often use score as main reward signal for learning or playing actions. However this has shown its severe limitations when the point rewards are very rare or absent until the end of the game. This paper proposes a new approach based on event logging: the game state triggers an event every time one of its features changes. These events are processed by an Event-value Function (EF) that assigns a value to a single action or a sequence. The experiments have shown that such approach can mitigate the problem of scarce point rewards and improve the AI performance. Furthermore this represents a step forward in controlling the strategy adopted by the artificial agent, by describing a much richer and controllable behavioural space through the EF. Tuned EF are able to neatly synthesise the relevance of the events in the game. Agents using an EF show more robust when playing games with several opponents.
Learning Local Forward Models on Unforgiving Games
Sep 01, 2019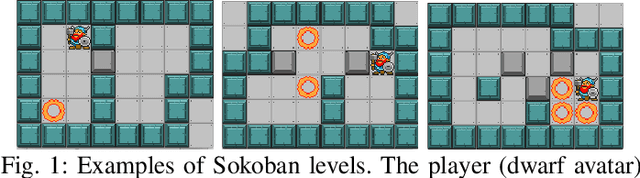
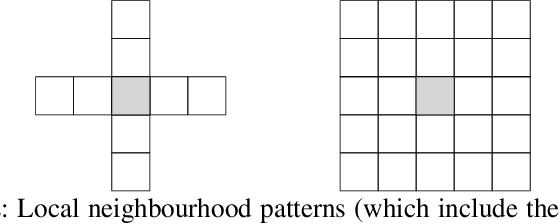


This paper examines learning approaches for forward models based on local cell transition functions. We provide a formal definition of local forward models for which we propose two basic learning approaches. Our analysis is based on the game Sokoban, where a wrong action can lead to an unsolvable game state. Therefore, an accurate prediction of an action's resulting state is necessary to avoid this scenario. In contrast to learning the complete state transition function, local forward models allow extracting multiple training examples from a single state transition. In this way, the Hash Set model, as well as the Decision Tree model, quickly learn to predict upcoming state transitions of both the training and the test set. Applying the model using a statistical forward planner showed that the best models can be used to satisfying degree even in cases in which the test levels have not yet been seen. Our evaluation includes an analysis of various local neighbourhood patterns and sizes to test the learners' capabilities in case too few or too many attributes are extracted, of which the latter has shown do degrade the performance of the model learner.
Rinascimento: Optimising Statistical Forward Planning Agents for Playing Splendor
Apr 03, 2019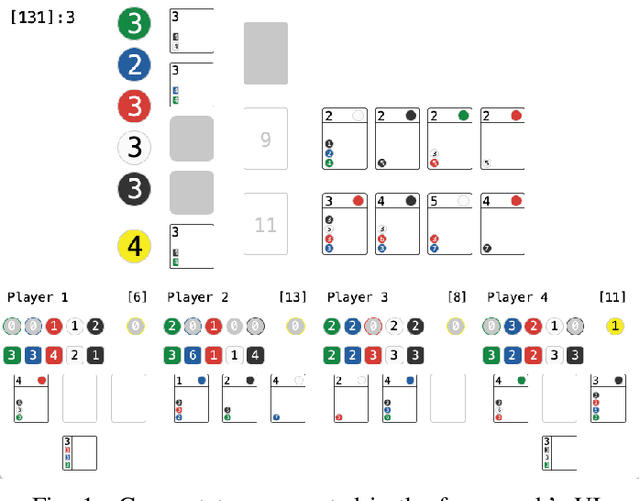

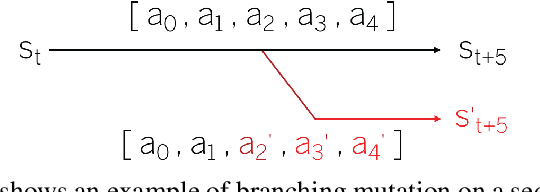
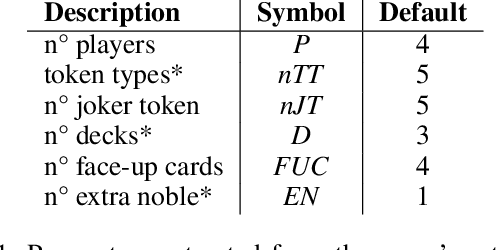
Game-based benchmarks have been playing an essential role in the development of Artificial Intelligence (AI) techniques. Providing diverse challenges is crucial to push research toward innovation and understanding in modern techniques. Rinascimento provides a parameterised partially-observable multiplayer card-based board game, these parameters can easily modify the rules, objectives and items in the game. We describe the framework in all its features and the game-playing challenge providing baseline game-playing AIs and analysis of their skills. We reserve to agents' hyper-parameter tuning a central role in the experiments highlighting how it can heavily influence the performance. The base-line agents contain several additional contribution to Statistical Forward Planning algorithms.
A Local Approach to Forward Model Learning: Results on the Game of Life Game
Mar 29, 2019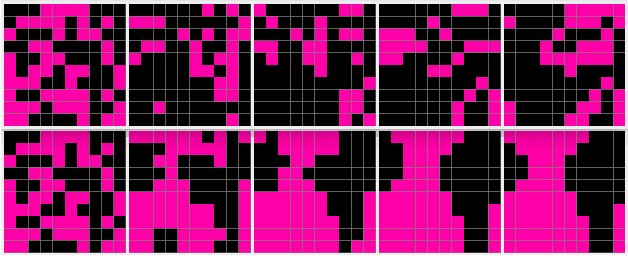
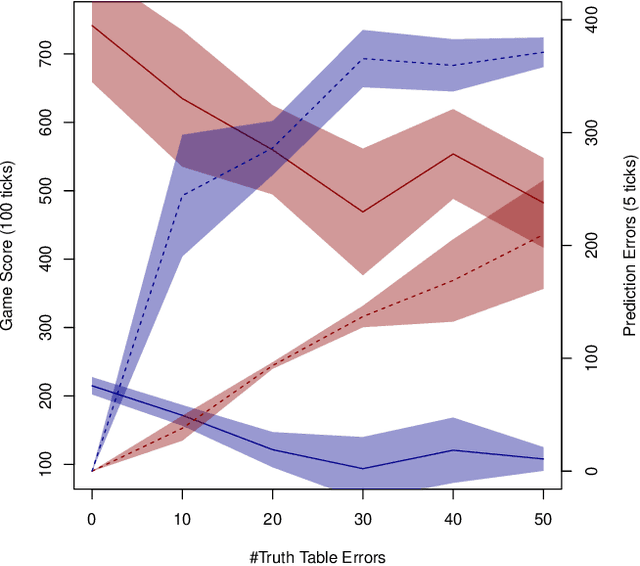
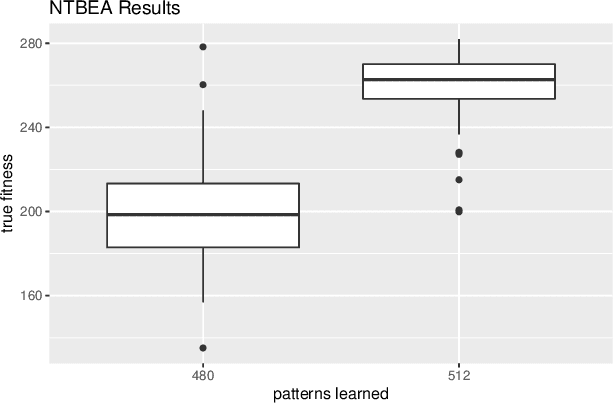
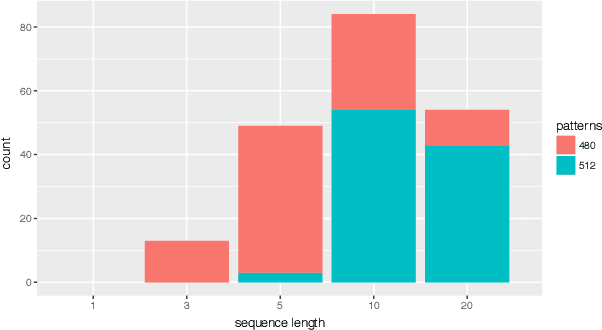
This paper investigates the effect of learning a forward model on the performance of a statistical forward planning agent. We transform Conway's Game of Life simulation into a single-player game where the objective can be either to preserve as much life as possible or to extinguish all life as quickly as possible. In order to learn the forward model of the game, we formulate the problem in a novel way that learns the local cell transition function by creating a set of supervised training data and predicting the next state of each cell in the grid based on its current state and immediate neighbours. Using this method we are able to harvest sufficient data to learn perfect forward models by observing only a few complete state transitions, using either a look-up table, a decision tree or a neural network. In contrast, learning the complete state transition function is a much harder task and our initial efforts to do this using deep convolutional auto-encoders were less successful. We also investigate the effects of imperfect learned models on prediction errors and game-playing performance, and show that even models with significant errors can provide good performance.
Efficient Evolutionary Methods for Game Agent Optimisation: Model-Based is Best
Jan 03, 2019



This paper introduces a simple and fast variant of Planet Wars as a test-bed for statistical planning based Game AI agents, and for noisy hyper-parameter optimisation. Planet Wars is a real-time strategy game with simple rules but complex game-play. The variant introduced in this paper is designed for speed to enable efficient experimentation, and also for a fixed action space to enable practical inter-operability with General Video Game AI agents. If we treat the game as a win-loss game (which is standard), then this leads to challenging noisy optimisation problems both in tuning agents to play the game, and in tuning game parameters. Here we focus on the problem of tuning an agent, and report results using the recently developed N-Tuple Bandit Evolutionary Algorithm and a number of other optimisers, including Sequential Model-based Algorithm Configuration (SMAC). Results indicate that the N-Tuple Bandit Evolutionary offers competitive performance as well as insight into the effects of combinations of parameter choices.
Shallow decision-making analysis in General Video Game Playing
Jun 04, 2018



The General Video Game AI competitions have been the testing ground for several techniques for game playing, such as evolutionary computation techniques, tree search algorithms, hyper heuristic based or knowledge based algorithms. So far the metrics used to evaluate the performance of agents have been win ratio, game score and length of games. In this paper we provide a wider set of metrics and a comparison method for evaluating and comparing agents. The metrics and the comparison method give shallow introspection into the agent's decision making process and they can be applied to any agent regardless of its algorithmic nature. In this work, the metrics and the comparison method are used to measure the impact of the terms that compose a tree policy of an MCTS based agent, comparing with several baseline agents. The results clearly show how promising such general approach is and how it can be useful to understand the behaviour of an AI agent, in particular, how the comparison with baseline agents can help understanding the shape of the agent decision landscape. The presented metrics and comparison method represent a step toward to more descriptive ways of logging and analysing agent's behaviours.