 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJSON-Bag: A generic game trajectory representation
Aug 01, 2025



We introduce JSON Bag-of-Tokens model (JSON-Bag) as a method to generically represent game trajectories by tokenizing their JSON descriptions and apply Jensen-Shannon distance (JSD) as distance metric for them. Using a prototype-based nearest-neighbor search (P-NNS), we evaluate the validity of JSON-Bag with JSD on six tabletop games -- \textit{7 Wonders}, \textit{Dominion}, \textit{Sea Salt and Paper}, \textit{Can't Stop}, \textit{Connect4}, \textit{Dots and boxes} -- each over three game trajectory classification tasks: classifying the playing agents, game parameters, or game seeds that were used to generate the trajectories. Our approach outperforms a baseline using hand-crafted features in the majority of tasks. Evaluating on N-shot classification suggests using JSON-Bag prototype to represent game trajectory classes is also sample efficient. Additionally, we demonstrate JSON-Bag ability for automatic feature extraction by treating tokens as individual features to be used in Random Forest to solve the tasks above, which significantly improves accuracy on underperforming tasks. Finally, we show that, across all six games, the JSD between JSON-Bag prototypes of agent classes highly correlates with the distances between agents' policies.
Seeding for Success: Skill and Stochasticity in Tabletop Games
Mar 04, 2025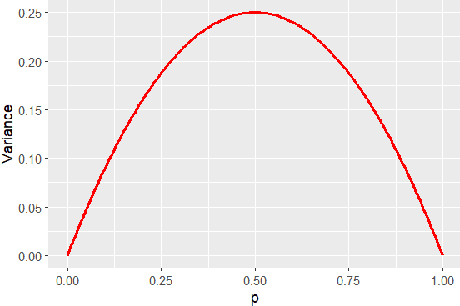



Games often incorporate random elements in the form of dice or shuffled card decks. This randomness is a key contributor to the player experience and the variety of game situations encountered. There is a tension between a level of randomness that makes the game interesting and contributes to the player enjoyment of a game, and a level at which the outcome itself is effectively random and the game becomes dull. The optimal level for a game will depend on the design goals and target audience. We introduce a new technique to quantify the level of randomness in game outcome and use it to compare 15 tabletop games and disentangle the different contributions to the overall randomness from specific parts of some games. We further explore the interaction between game randomness and player skill, and how this innate randomness can affect error analysis in common game experiments.
* Published in IEEE Transactions on Games, 2025
From Code to Play: Benchmarking Program Search for Games Using Large Language Models
Dec 05, 2024



Large language models (LLMs) have shown impressive capabilities in generating program code, opening exciting opportunities for applying program synthesis to games. In this work, we explore the potential of LLMs to directly synthesize usable code for a wide range of gaming applications, focusing on two programming languages, Python and Java. We use an evolutionary hill-climbing algorithm, where the mutations and seeds of the initial programs are controlled by LLMs. For Python, the framework covers various game-related tasks, including five miniature versions of Atari games, ten levels of Baba is You, an environment inspired by Asteroids, and a maze generation task. For Java, the framework contains 12 games from the TAG tabletop games framework. Across 29 tasks, we evaluated 12 language models for Python and 8 for Java. Our findings suggest that the performance of LLMs depends more on the task than on model size. While larger models generate more executable programs, these do not always result in higher-quality solutions but are much more expensive. No model has a clear advantage, although on any specific task, one model may be better. Trying many models on a problem and using the best results across them is more reliable than using just one.
Strategy Game-Playing with Size-Constrained State Abstraction
Aug 12, 2024Playing strategy games is a challenging problem for artificial intelligence (AI). One of the major challenges is the large search space due to a diverse set of game components. In recent works, state abstraction has been applied to search-based game AI and has brought significant performance improvements. State abstraction techniques rely on reducing the search space, e.g., by aggregating similar states. However, the application of these abstractions is hindered because the quality of an abstraction is difficult to evaluate. Previous works hence abandon the abstraction in the middle of the search to not bias the search to a local optimum. This mechanism introduces a hyper-parameter to decide the time to abandon the current state abstraction. In this work, we propose a size-constrained state abstraction (SCSA), an approach that limits the maximum number of nodes being grouped together. We found that with SCSA, the abstraction is not required to be abandoned. Our empirical results on $3$ strategy games show that the SCSA agent outperforms the previous methods and yields robust performance over different games. Codes are open-sourced at \url{https://github.com/GAIGResearch/Stratega}.
PyTAG: Tabletop Games for Multi-Agent Reinforcement Learning
May 28, 2024



Modern Tabletop Games present various interesting challenges for Multi-agent Reinforcement Learning. In this paper, we introduce PyTAG, a new framework that supports interacting with a large collection of games implemented in the Tabletop Games framework. In this work we highlight the challenges tabletop games provide, from a game-playing agent perspective, along with the opportunities they provide for future research. Additionally, we highlight the technical challenges that involve training Reinforcement Learning agents on these games. To explore the Multi-agent setting provided by PyTAG we train the popular Proximal Policy Optimisation Reinforcement Learning algorithm using self-play on a subset of games and evaluate the trained policies against some simple agents and Monte-Carlo Tree Search implemented in the Tabletop Games framework.
Higher Replay Ratio Empowers Sample-Efficient Multi-Agent Reinforcement Learning
Apr 15, 2024



One of the notorious issues for Reinforcement Learning (RL) is poor sample efficiency. Compared to single agent RL, the sample efficiency for Multi-Agent Reinforcement Learning (MARL) is more challenging because of its inherent partial observability, non-stationary training, and enormous strategy space. Although much effort has been devoted to developing new methods and enhancing sample efficiency, we look at the widely used episodic training mechanism. In each training step, tens of frames are collected, but only one gradient step is made. We argue that this episodic training could be a source of poor sample efficiency. To better exploit the data already collected, we propose to increase the frequency of the gradient updates per environment interaction (a.k.a. Replay Ratio or Update-To-Data ratio). To show its generality, we evaluate $3$ MARL methods on $6$ SMAC tasks. The empirical results validate that a higher replay ratio significantly improves the sample efficiency for MARL algorithms. The codes to reimplement the results presented in this paper are open-sourced at https://anonymous.4open.science/r/rr_for_MARL-0D83/.
Playing NetHack with LLMs: Potential & Limitations as Zero-Shot Agents
Mar 01, 2024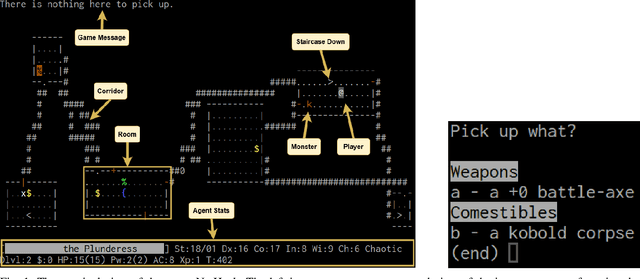
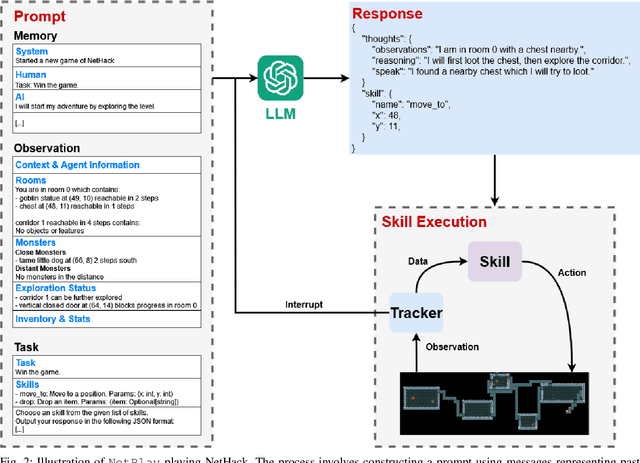


Large Language Models (LLMs) have shown great success as high-level planners for zero-shot game-playing agents. However, these agents are primarily evaluated on Minecraft, where long-term planning is relatively straightforward. In contrast, agents tested in dynamic robot environments face limitations due to simplistic environments with only a few objects and interactions. To fill this gap in the literature, we present NetPlay, the first LLM-powered zero-shot agent for the challenging roguelike NetHack. NetHack is a particularly challenging environment due to its diverse set of items and monsters, complex interactions, and many ways to die. NetPlay uses an architecture designed for dynamic robot environments, modified for NetHack. Like previous approaches, it prompts the LLM to choose from predefined skills and tracks past interactions to enhance decision-making. Given NetHack's unpredictable nature, NetPlay detects important game events to interrupt running skills, enabling it to react to unforeseen circumstances. While NetPlay demonstrates considerable flexibility and proficiency in interacting with NetHack's mechanics, it struggles with ambiguous task descriptions and a lack of explicit feedback. Our findings demonstrate that NetPlay performs best with detailed context information, indicating the necessity for dynamic methods in supplying context information for complex games such as NetHack.
PyTAG: Challenges and Opportunities for Reinforcement Learning in Tabletop Games
Jul 19, 2023



In recent years, Game AI research has made important breakthroughs using Reinforcement Learning (RL). Despite this, RL for modern tabletop games has gained little to no attention, even when they offer a range of unique challenges compared to video games. To bridge this gap, we introduce PyTAG, a Python API for interacting with the Tabletop Games framework (TAG). TAG contains a growing set of more than 20 modern tabletop games, with a common API for AI agents. We present techniques for training RL agents in these games and introduce baseline results after training Proximal Policy Optimisation algorithms on a subset of games. Finally, we discuss the unique challenges complex modern tabletop games provide, now open to RL research through PyTAG.
Task Relabelling for Multi-task Transfer using Successor Features
May 20, 2022


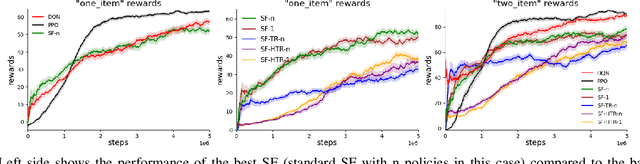
Deep Reinforcement Learning has been very successful recently with various works on complex domains. Most works are concerned with learning a single policy that solves the target task, but is fixed in the sense that if the environment changes the agent is unable to adapt to it. Successor Features (SFs) proposes a mechanism that allows learning policies that are not tied to any particular reward function. In this work we investigate how SFs may be pre-trained without observing any reward in a custom environment that features resource collection, traps and crafting. After pre-training we expose the SF agents to various target tasks and see how well they can transfer to new tasks. Transferring is done without any further training on the SF agents, instead just by providing a task vector. For training the SFs we propose a task relabelling method which greatly improves the agent's performance.
Visualising Multiplayer Game Spaces
Feb 11, 2022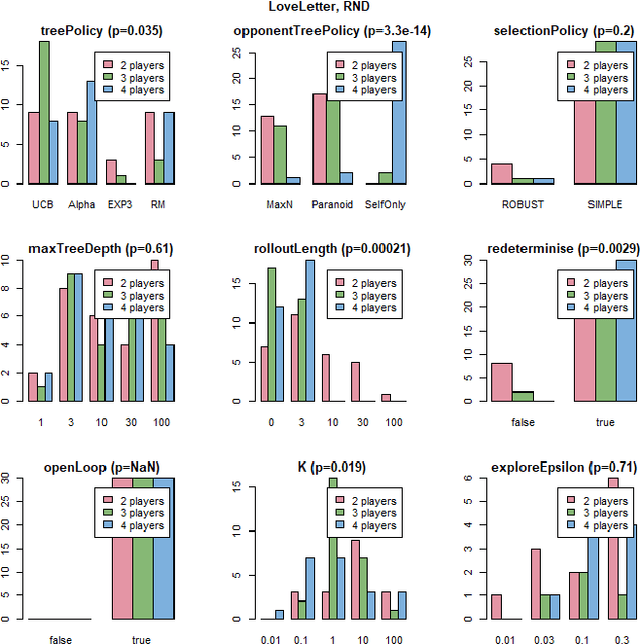
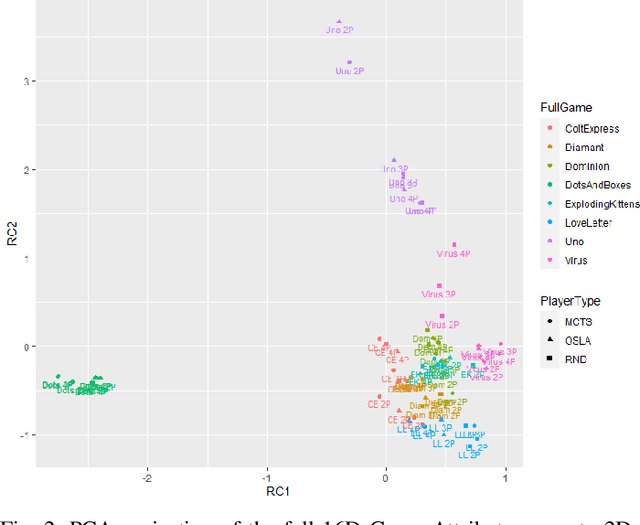
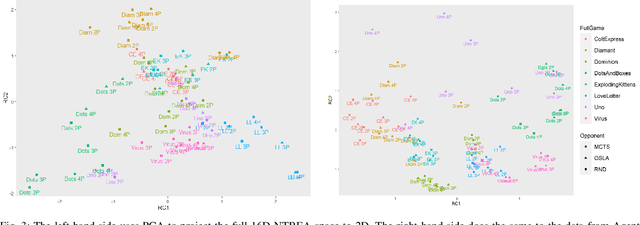
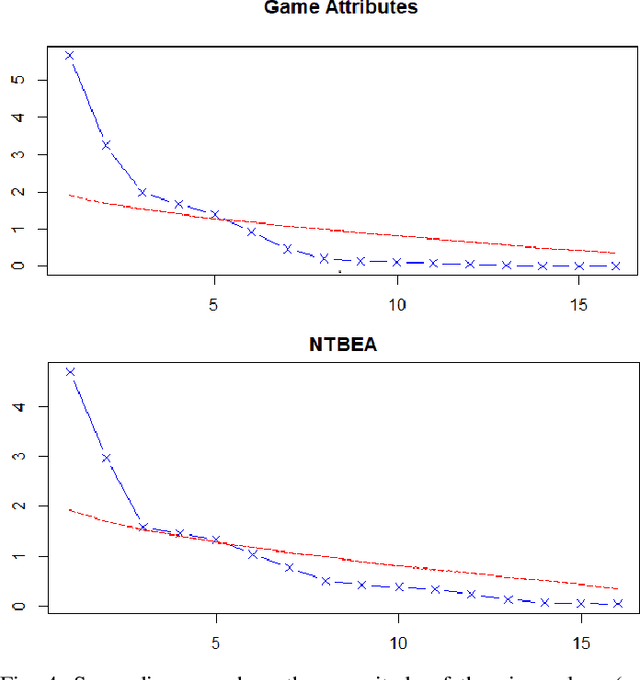
We compare four different `game-spaces' in terms of their usefulness in characterising multi-player tabletop games, with a particular interest in any underlying change to a game's characteristics as the number of players changes. In each case we take a 16-dimensional feature space, and reduce it to a 2-dimensional visualizable landscape. We find that a space obtained from optimization of parameters in Monte Carlo Tree Search (MCTS) is the most directly interpretable to characterise our set of games in terms of the relative importance of imperfect information, adversarial opponents and reward sparsity. These results do not correlate with a space defined using attributes of the game-tree. This dimensionality reduction does not show any general effect as the number of players. We therefore consider the question using the original features to classify the games into two sets; those for which the characteristics of the game changes significantly as the number of players changes, and those for which there is no such effect.
* 13 pages, 7 figures, Accepted for IEEE Transactions on Games