 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePyTAG: Tabletop Games for Multi-Agent Reinforcement Learning
May 28, 2024



Modern Tabletop Games present various interesting challenges for Multi-agent Reinforcement Learning. In this paper, we introduce PyTAG, a new framework that supports interacting with a large collection of games implemented in the Tabletop Games framework. In this work we highlight the challenges tabletop games provide, from a game-playing agent perspective, along with the opportunities they provide for future research. Additionally, we highlight the technical challenges that involve training Reinforcement Learning agents on these games. To explore the Multi-agent setting provided by PyTAG we train the popular Proximal Policy Optimisation Reinforcement Learning algorithm using self-play on a subset of games and evaluate the trained policies against some simple agents and Monte-Carlo Tree Search implemented in the Tabletop Games framework.
PyTAG: Challenges and Opportunities for Reinforcement Learning in Tabletop Games
Jul 19, 2023



In recent years, Game AI research has made important breakthroughs using Reinforcement Learning (RL). Despite this, RL for modern tabletop games has gained little to no attention, even when they offer a range of unique challenges compared to video games. To bridge this gap, we introduce PyTAG, a Python API for interacting with the Tabletop Games framework (TAG). TAG contains a growing set of more than 20 modern tabletop games, with a common API for AI agents. We present techniques for training RL agents in these games and introduce baseline results after training Proximal Policy Optimisation algorithms on a subset of games. Finally, we discuss the unique challenges complex modern tabletop games provide, now open to RL research through PyTAG.
Task Relabelling for Multi-task Transfer using Successor Features
May 20, 2022


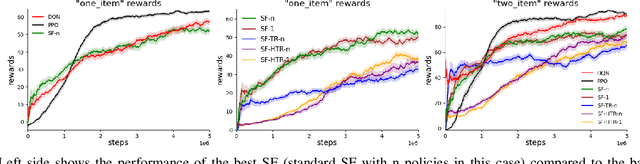
Deep Reinforcement Learning has been very successful recently with various works on complex domains. Most works are concerned with learning a single policy that solves the target task, but is fixed in the sense that if the environment changes the agent is unable to adapt to it. Successor Features (SFs) proposes a mechanism that allows learning policies that are not tied to any particular reward function. In this work we investigate how SFs may be pre-trained without observing any reward in a custom environment that features resource collection, traps and crafting. After pre-training we expose the SF agents to various target tasks and see how well they can transfer to new tasks. Transferring is done without any further training on the SF agents, instead just by providing a task vector. For training the SFs we propose a task relabelling method which greatly improves the agent's performance.
Design and Implementation of TAG: A Tabletop Games Framework
Sep 25, 2020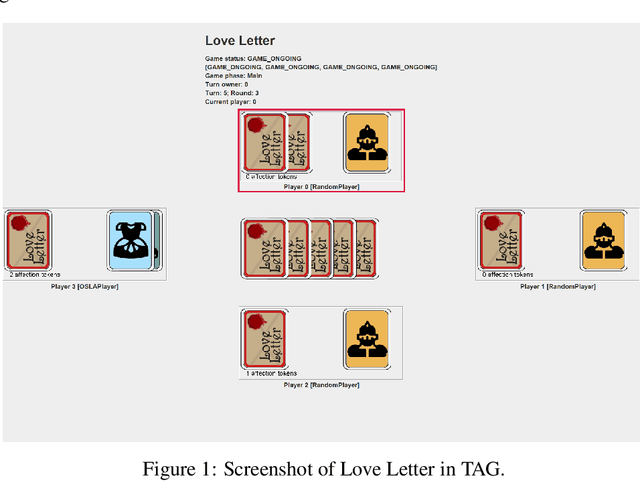
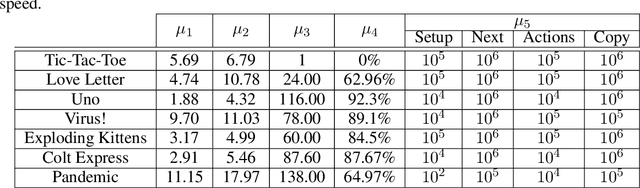
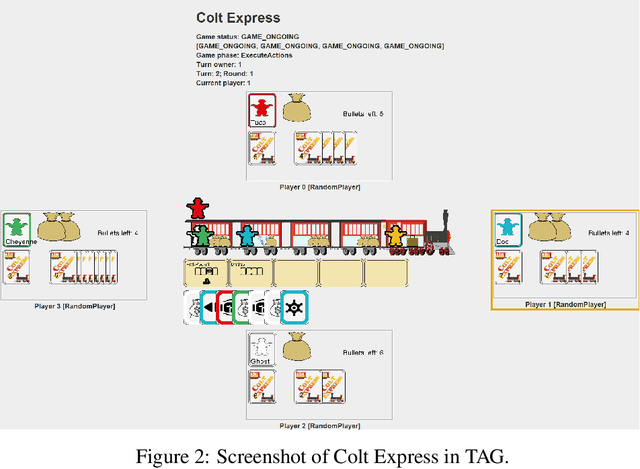
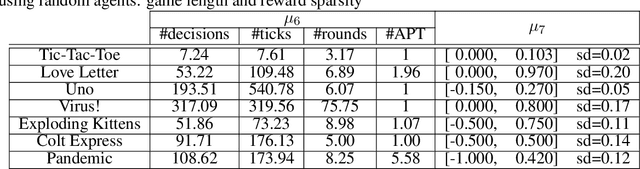
This document describes the design and implementation of the Tabletop Games framework (TAG), a Java-based benchmark for developing modern board games for AI research. TAG provides a common skeleton for implementing tabletop games based on a common API for AI agents, a set of components and classes to easily add new games and an import module for defining data in JSON format. At present, this platform includes the implementation of seven different tabletop games that can also be used as an example for further developments. Additionally, TAG also incorporates logging functionality that allows the user to perform a detailed analysis of the game, in terms of action space, branching factor, hidden information, and other measures of interest for Game AI research. The objective of this document is to serve as a central point where the framework can be described at length. TAG can be downloaded at: https://github.com/GAIGResearch/TabletopGames
Evaluating Generalisation in General Video Game Playing
May 22, 2020
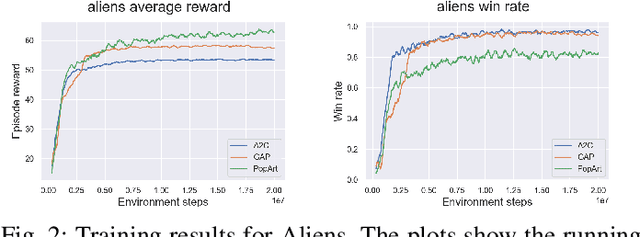


The General Video Game Artificial Intelligence (GVGAI) competition has been running for several years with various tracks. This paper focuses on the challenge of the GVGAI learning track in which 3 games are selected and 2 levels are given for training, while 3 hidden levels are left for evaluation. This setup poses a difficult challenge for current Reinforcement Learning (RL) algorithms, as they typically require much more data. This work investigates 3 versions of the Advantage Actor-Critic (A2C) algorithm trained on a maximum of 2 levels from the available 5 from the GVGAI framework and compares their performance on all levels. The selected sub-set of games have different characteristics, like stochasticity, reward distribution and objectives. We found that stochasticity improves the generalisation, but too much can cause the algorithms to fail to learn the training levels. The quality of the training levels also matters, different sets of training levels can boost generalisation over all levels. In the GVGAI competition agents are scored based on their win rates and then their scores achieved in the games. We found that solely using the rewards provided by the game might not encourage winning.