 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Generalisation in General Video Game Playing
Paper and Code
May 22, 2020
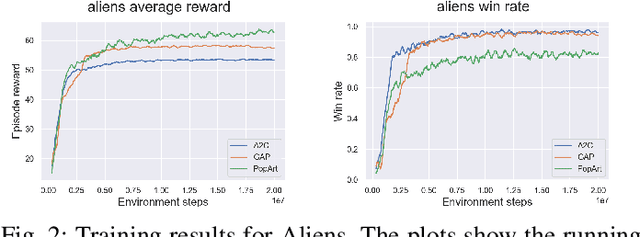


The General Video Game Artificial Intelligence (GVGAI) competition has been running for several years with various tracks. This paper focuses on the challenge of the GVGAI learning track in which 3 games are selected and 2 levels are given for training, while 3 hidden levels are left for evaluation. This setup poses a difficult challenge for current Reinforcement Learning (RL) algorithms, as they typically require much more data. This work investigates 3 versions of the Advantage Actor-Critic (A2C) algorithm trained on a maximum of 2 levels from the available 5 from the GVGAI framework and compares their performance on all levels. The selected sub-set of games have different characteristics, like stochasticity, reward distribution and objectives. We found that stochasticity improves the generalisation, but too much can cause the algorithms to fail to learn the training levels. The quality of the training levels also matters, different sets of training levels can boost generalisation over all levels. In the GVGAI competition agents are scored based on their win rates and then their scores achieved in the games. We found that solely using the rewards provided by the game might not encourage winning.