 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredictive Control Using Learned State Space Models via Rolling Horizon Evolution
Jun 25, 2021


A large part of the interest in model-based reinforcement learning derives from the potential utility to acquire a forward model capable of strategic long term decision making. Assuming that an agent succeeds in learning a useful predictive model, it still requires a mechanism to harness it to generate and select among competing simulated plans. In this paper, we explore this theme combining evolutionary algorithmic planning techniques with models learned via deep learning and variational inference. We demonstrate the approach with an agent that reliably performs online planning in a set of visual navigation tasks.
Modulation of viability signals for self-regulatory control
Jul 18, 2020
We revisit the role of instrumental value as a driver of adaptive behavior. In active inference, instrumental or extrinsic value is quantified by the information-theoretic surprisal of a set of observations measuring the extent to which those observations conform to prior beliefs or preferences. That is, an agent is expected to seek the type of evidence that is consistent with its own model of the world. For reinforcement learning tasks, the distribution of preferences replaces the notion of reward. We explore a scenario in which the agent learns this distribution in a self-supervised manner. In particular, we highlight the distinction between observations induced by the environment and those pertaining more directly to the continuity of an agent in time. We evaluate our methodology in a dynamic environment with discrete time and actions. First with a surprisal minimizing model-free agent (in the RL sense) and then expanding to the model-based case to minimize the expected free energy.
Evaluating Generalisation in General Video Game Playing
May 22, 2020
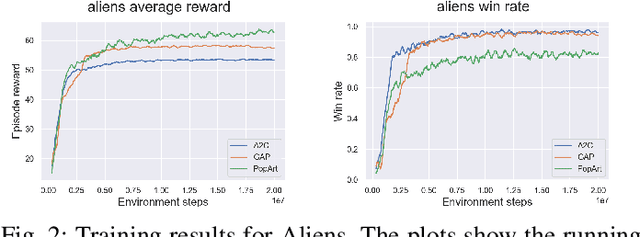


The General Video Game Artificial Intelligence (GVGAI) competition has been running for several years with various tracks. This paper focuses on the challenge of the GVGAI learning track in which 3 games are selected and 2 levels are given for training, while 3 hidden levels are left for evaluation. This setup poses a difficult challenge for current Reinforcement Learning (RL) algorithms, as they typically require much more data. This work investigates 3 versions of the Advantage Actor-Critic (A2C) algorithm trained on a maximum of 2 levels from the available 5 from the GVGAI framework and compares their performance on all levels. The selected sub-set of games have different characteristics, like stochasticity, reward distribution and objectives. We found that stochasticity improves the generalisation, but too much can cause the algorithms to fail to learn the training levels. The quality of the training levels also matters, different sets of training levels can boost generalisation over all levels. In the GVGAI competition agents are scored based on their win rates and then their scores achieved in the games. We found that solely using the rewards provided by the game might not encourage winning.
Bootstrapped model learning and error correction for planning with uncertainty in model-based RL
Apr 15, 2020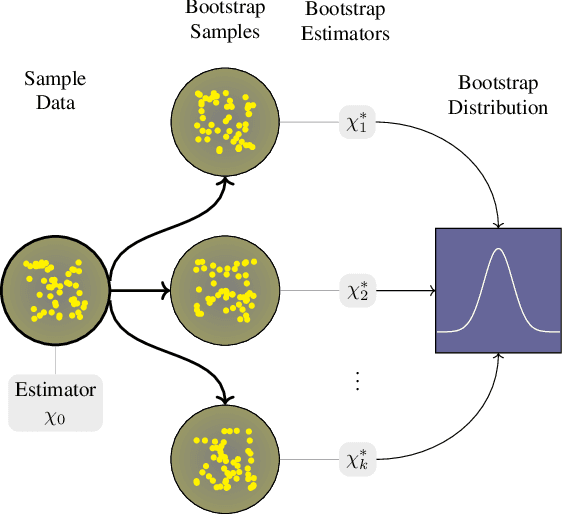

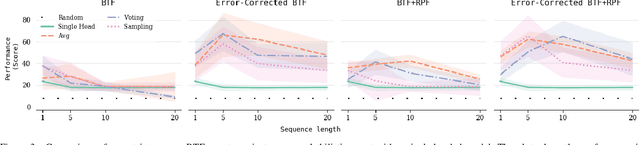
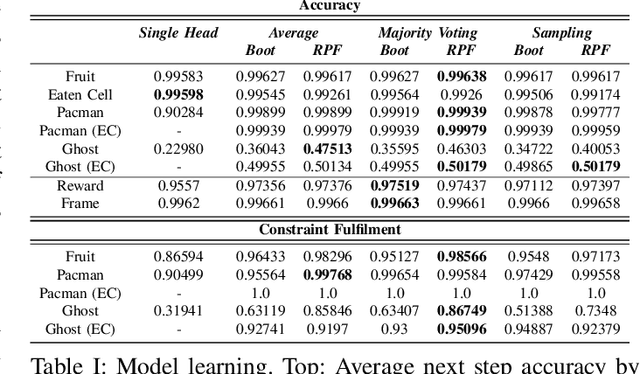
Having access to a forward model enables the use of planning algorithms such as Monte Carlo Tree Search and Rolling Horizon Evolution. Where a model is unavailable, a natural aim is to learn a model that reflects accurately the dynamics of the environment. In many situations it might not be possible and minimal glitches in the model may lead to poor performance and failure. This paper explores the problem of model misspecification through uncertainty-aware reinforcement learning agents. We propose a bootstrapped multi-headed neural network that learns the distribution of future states and rewards. We experiment with a number of schemes to extract the most likely predictions. Moreover, we also introduce a global error correction filter that applies high-level constraints guided by the context provided through the predictive distribution. We illustrate our approach on Minipacman. The evaluation demonstrates that when dealing with imperfect models, our methods exhibit increased performance and stability, both in terms of model accuracy and in its use within a planning algorithm.
Enhanced Rolling Horizon Evolution Algorithm with Opponent Model Learning: Results for the Fighting Game AI Competition
Mar 31, 2020
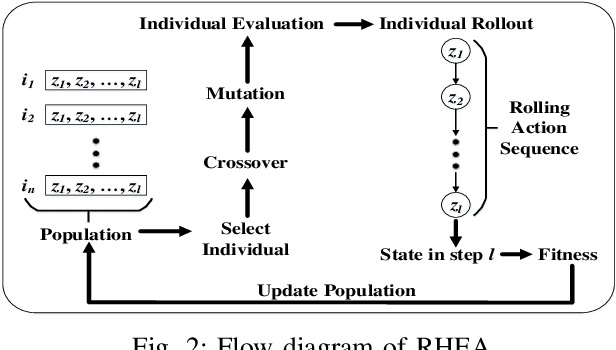
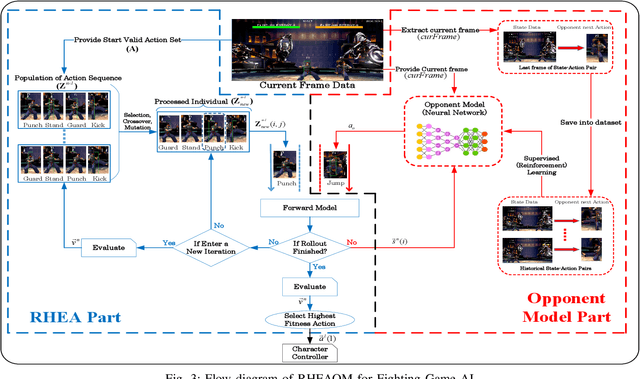
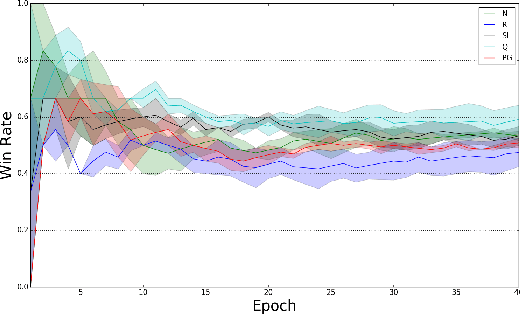
The Fighting Game AI Competition (FTGAIC) provides a challenging benchmark for 2-player video game AI. The challenge arises from the large action space, diverse styles of characters and abilities, and the real-time nature of the game. In this paper, we propose a novel algorithm that combines Rolling Horizon Evolution Algorithm (RHEA) with opponent model learning. The approach is readily applicable to any 2-player video game. In contrast to conventional RHEA, an opponent model is proposed and is optimized by supervised learning with cross-entropy and reinforcement learning with policy gradient and Q-learning respectively, based on history observations from opponent. The model is learned during the live gameplay. With the learned opponent model, the extended RHEA is able to make more realistic plans based on what the opponent is likely to do. This tends to lead to better results. We compared our approach directly with the bots from the FTGAIC 2018 competition, and found our method to significantly outperform all of them, for all three character. Furthermore, our proposed bot with the policy-gradient-based opponent model is the only one without using Monte-Carlo Tree Search (MCTS) among top five bots in the 2019 competition in which it achieved second place, while using much less domain knowledge than the winner.
Rolling Horizon Evolutionary Algorithms for General Video Game Playing
Mar 27, 2020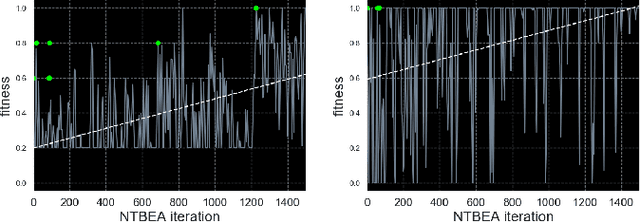
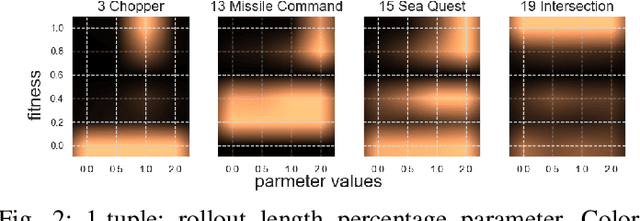
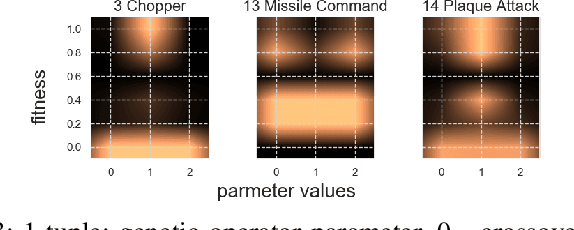
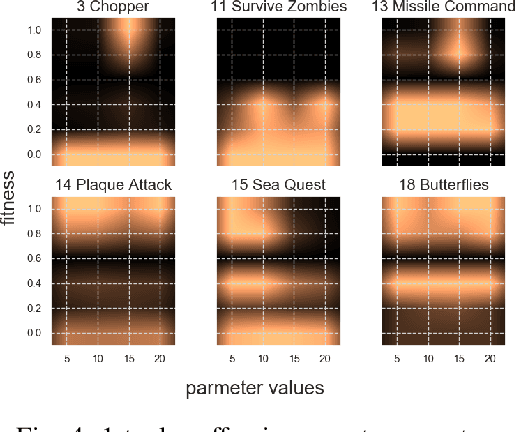
Game-playing Evolutionary Algorithms, specifically Rolling Horizon Evolutionary Algorithms, have recently managed to beat the state of the art in performance across many games. However, the best results per game are highly dependent on the specific configuration of modifications and hybrids introduced over several works, each described as parameters in the algorithm. However, the search for the best parameters has been reduced to several human-picked combinations, as the possibility space has grown beyond exhaustive search. This paper presents the state of the art in Rolling Horizon Evolutionary algorithms, combining all modifications described in literature and some additional ones for a large resultant hybrid. It then uses a parameter optimiser, the N-Tuple Bandit Evolutionary Algorithm, to find the best combination of parameters in 20 games with various properties from the General Video Game AI Framework. We highlight the noisy optimisation problem resultant, as both the games and the algorithm being optimised are stochastic. We then analyse the algorithm's parameters and interesting combinations revealed through the parameter optimisation process. Lastly, we show that it is possible to automatically explore a large parameter space and find configurations which outperform the state of the art on several games.
Learning Local Forward Models on Unforgiving Games
Sep 01, 2019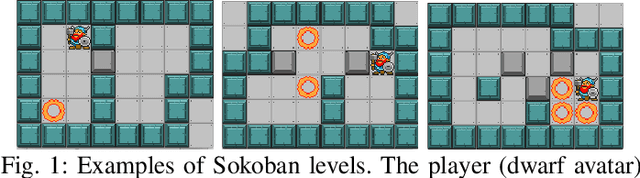
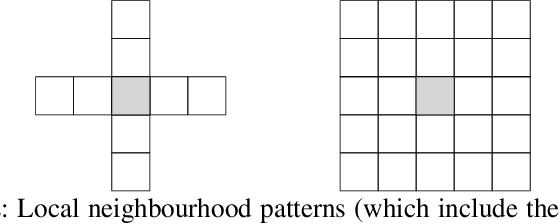


This paper examines learning approaches for forward models based on local cell transition functions. We provide a formal definition of local forward models for which we propose two basic learning approaches. Our analysis is based on the game Sokoban, where a wrong action can lead to an unsolvable game state. Therefore, an accurate prediction of an action's resulting state is necessary to avoid this scenario. In contrast to learning the complete state transition function, local forward models allow extracting multiple training examples from a single state transition. In this way, the Hash Set model, as well as the Decision Tree model, quickly learn to predict upcoming state transitions of both the training and the test set. Applying the model using a statistical forward planner showed that the best models can be used to satisfying degree even in cases in which the test levels have not yet been seen. Our evaluation includes an analysis of various local neighbourhood patterns and sizes to test the learners' capabilities in case too few or too many attributes are extracted, of which the latter has shown do degrade the performance of the model learner.
Project Thyia: A Forever Gameplayer
Jun 10, 2019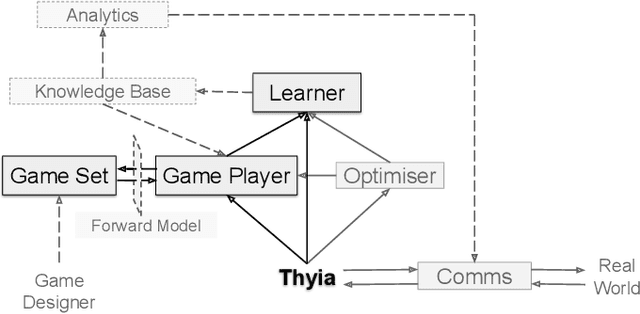
The space of Artificial Intelligence entities is dominated by conversational bots. Some of them fit in our pockets and we take them everywhere we go, or allow them to be a part of human homes. Siri, Alexa, they are recognised as present in our world. But a lot of games research is restricted to existing in the separate realm of software. We enter different worlds when playing games, but those worlds cease to exist once we quit. Similarly, AI game-players are run once on a game (or maybe for longer periods of time, in the case of learning algorithms which need some, still limited, period for training), and they cease to exist once the game ends. But what if they didn't? What if there existed artificial game-players that continuously played games, learned from their experiences and kept getting better? What if they interacted with the real world and us, humans: live-streaming games, chatting with viewers, accepting suggestions for strategies or games to play, forming opinions on popular game titles? In this paper, we introduce the vision behind a new project called Thyia, which focuses around creating a present, continuous, `always-on', interactive game-player.
Foundations of Digital Archæoludology
May 31, 2019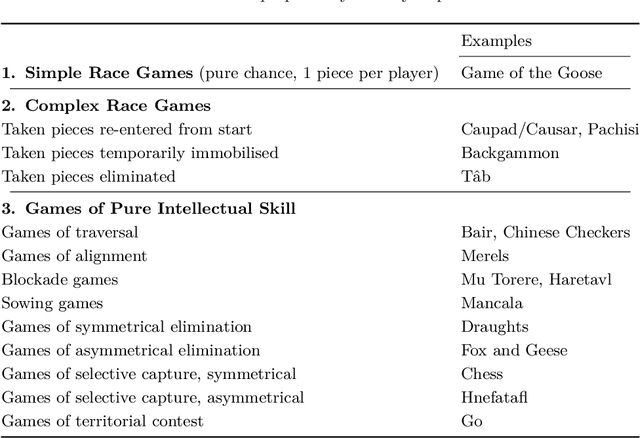


Digital Archaeoludology (DAL) is a new field of study involving the analysis and reconstruction of ancient games from incomplete descriptions and archaeological evidence using modern computational techniques. The aim is to provide digital tools and methods to help game historians and other researchers better understand traditional games, their development throughout recorded human history, and their relationship to the development of human culture and mathematical knowledge. This work is being explored in the ERC-funded Digital Ludeme Project. The aim of this inaugural international research meeting on DAL is to gather together leading experts in relevant disciplines - computer science, artificial intelligence, machine learning, computational phylogenetics, mathematics, history, archaeology, anthropology, etc. - to discuss the key themes and establish the foundations for this new field of research, so that it may continue beyond the lifetime of its initiating project.
Tile Pattern KL-Divergence for Analysing and Evolving Game Levels
Apr 24, 2019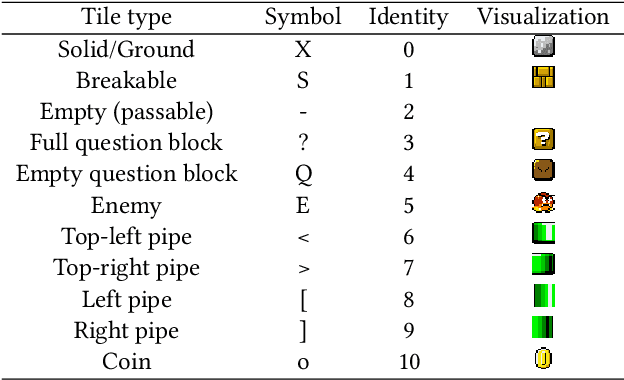



This paper provides a detailed investigation of using the Kullback-Leibler (KL) Divergence as a way to compare and analyse game-levels, and hence to use the measure as the objective function of an evolutionary algorithm to evolve new levels. We describe the benefits of its asymmetry for level analysis and demonstrate how (not surprisingly) the quality of the results depends on the features used. Here we use tile-patterns of various sizes as features. When using the measure for evolution-based level generation, we demonstrate that the choice of variation operator is critical in order to provide an efficient search process, and introduce a novel convolutional mutation operator to facilitate this. We compare the results with alternative generators, including evolving in the latent space of generative adversarial networks, and Wave Function Collapse. The results clearly show the proposed method to provide competitive performance, providing reasonable quality results with very fast training and reasonably fast generation.