 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredictive Control Using Learned State Space Models via Rolling Horizon Evolution
Jun 25, 2021


A large part of the interest in model-based reinforcement learning derives from the potential utility to acquire a forward model capable of strategic long term decision making. Assuming that an agent succeeds in learning a useful predictive model, it still requires a mechanism to harness it to generate and select among competing simulated plans. In this paper, we explore this theme combining evolutionary algorithmic planning techniques with models learned via deep learning and variational inference. We demonstrate the approach with an agent that reliably performs online planning in a set of visual navigation tasks.
Generalising Discrete Action Spaces with Conditional Action Trees
Apr 15, 2021
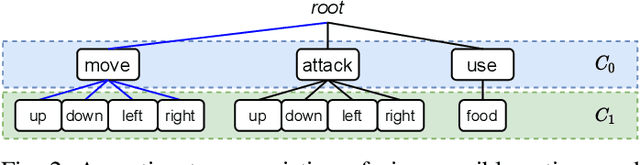
There are relatively few conventions followed in reinforcement learning (RL) environments to structure the action spaces. As a consequence the application of RL algorithms to tasks with large action spaces with multiple components require additional effort to adjust to different formats. In this paper we introduce {\em Conditional Action Trees} with two main objectives: (1) as a method of structuring action spaces in RL to generalise across several action space specifications, and (2) to formalise a process to significantly reduce the action space by decomposing it into multiple sub-spaces, favoring a multi-staged decision making approach. We show several proof-of-concept experiments validating our scheme, ranging from environments with basic discrete action spaces to those with large combinatorial action spaces commonly found in RTS-style games.
Modulation of viability signals for self-regulatory control
Jul 18, 2020
We revisit the role of instrumental value as a driver of adaptive behavior. In active inference, instrumental or extrinsic value is quantified by the information-theoretic surprisal of a set of observations measuring the extent to which those observations conform to prior beliefs or preferences. That is, an agent is expected to seek the type of evidence that is consistent with its own model of the world. For reinforcement learning tasks, the distribution of preferences replaces the notion of reward. We explore a scenario in which the agent learns this distribution in a self-supervised manner. In particular, we highlight the distinction between observations induced by the environment and those pertaining more directly to the continuity of an agent in time. We evaluate our methodology in a dynamic environment with discrete time and actions. First with a surprisal minimizing model-free agent (in the RL sense) and then expanding to the model-based case to minimize the expected free energy.
Bootstrapped model learning and error correction for planning with uncertainty in model-based RL
Apr 15, 2020

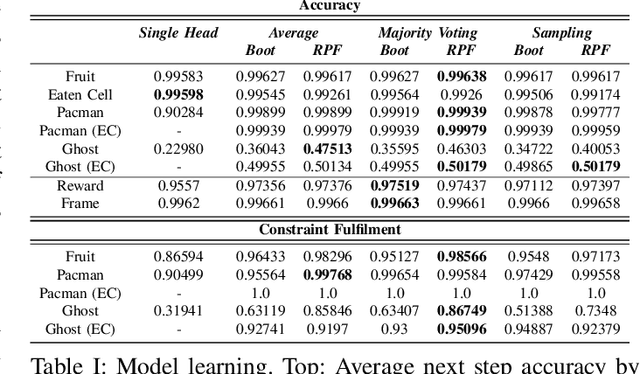
Having access to a forward model enables the use of planning algorithms such as Monte Carlo Tree Search and Rolling Horizon Evolution. Where a model is unavailable, a natural aim is to learn a model that reflects accurately the dynamics of the environment. In many situations it might not be possible and minimal glitches in the model may lead to poor performance and failure. This paper explores the problem of model misspecification through uncertainty-aware reinforcement learning agents. We propose a bootstrapped multi-headed neural network that learns the distribution of future states and rewards. We experiment with a number of schemes to extract the most likely predictions. Moreover, we also introduce a global error correction filter that applies high-level constraints guided by the context provided through the predictive distribution. We illustrate our approach on Minipacman. The evaluation demonstrates that when dealing with imperfect models, our methods exhibit increased performance and stability, both in terms of model accuracy and in its use within a planning algorithm.