 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGriddlyJS: A Web IDE for Reinforcement Learning
Jul 13, 2022
Progress in reinforcement learning (RL) research is often driven by the design of new, challenging environments -- a costly undertaking requiring skills orthogonal to that of a typical machine learning researcher. The complexity of environment development has only increased with the rise of procedural-content generation (PCG) as the prevailing paradigm for producing varied environments capable of testing the robustness and generalization of RL agents. Moreover, existing environments often require complex build processes, making reproducing results difficult. To address these issues, we introduce GriddlyJS, a web-based Integrated Development Environment (IDE) based on the Griddly engine. GriddlyJS allows researchers to visually design and debug arbitrary, complex PCG grid-world environments using a convenient graphical interface, as well as visualize, evaluate, and record the performance of trained agent models. By connecting the RL workflow to the advanced functionality enabled by modern web standards, GriddlyJS allows publishing interactive agent-environment demos that reproduce experimental results directly to the web. To demonstrate the versatility of GriddlyJS, we use it to quickly develop a complex compositional puzzle-solving environment alongside arbitrary human-designed environment configurations and their solutions for use in automatic curriculum learning and offline RL. The GriddlyJS IDE is open source and freely available at \url{https://griddly.ai}.
Generalising Discrete Action Spaces with Conditional Action Trees
Apr 15, 2021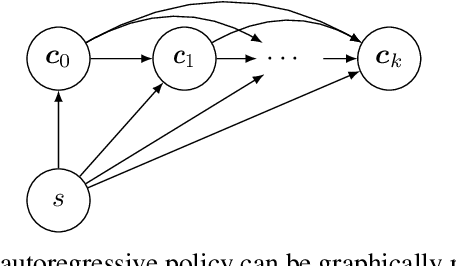
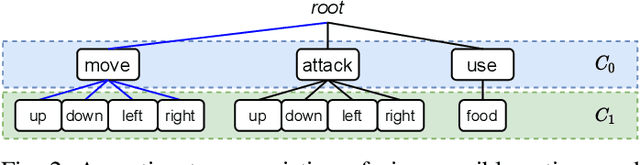
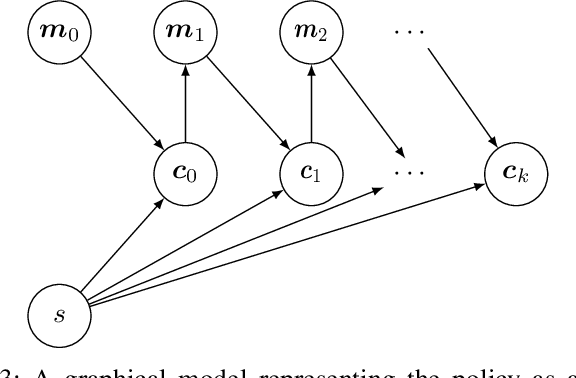
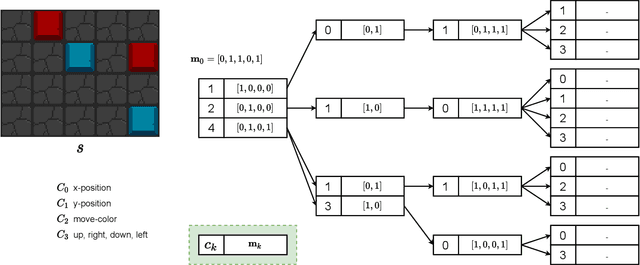
There are relatively few conventions followed in reinforcement learning (RL) environments to structure the action spaces. As a consequence the application of RL algorithms to tasks with large action spaces with multiple components require additional effort to adjust to different formats. In this paper we introduce {\em Conditional Action Trees} with two main objectives: (1) as a method of structuring action spaces in RL to generalise across several action space specifications, and (2) to formalise a process to significantly reduce the action space by decomposing it into multiple sub-spaces, favoring a multi-staged decision making approach. We show several proof-of-concept experiments validating our scheme, ranging from environments with basic discrete action spaces to those with large combinatorial action spaces commonly found in RTS-style games.