 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Gameplay Traces to Game Mechanics: Causal Induction with Large Language Models
Jan 30, 2026Deep learning agents can achieve high performance in complex game domains without often understanding the underlying causal game mechanics. To address this, we investigate Causal Induction: the ability to infer governing laws from observational data, by tasking Large Language Models (LLMs) with reverse-engineering Video Game Description Language (VGDL) rules from gameplay traces. To reduce redundancy, we select nine representative games from the General Video Game AI (GVGAI) framework using semantic embeddings and clustering. We compare two approaches to VGDL generation: direct code generation from observations, and a two-stage method that first infers a structural causal model (SCM) and then translates it into VGDL. Both approaches are evaluated across multiple prompting strategies and controlled context regimes, varying the amount and form of information provided to the model, from just raw gameplay observations to partial VGDL specifications. Results show that the SCM-based approach more often produces VGDL descriptions closer to the ground truth than direct generation, achieving preference win rates of up to 81\% in blind evaluations and yielding fewer logically inconsistent rules. These learned SCMs can be used for downstream use cases such as causal reinforcement learning, interpretable agents, and procedurally generating novel but logically consistent games.
Discovering State Equivalences in UCT Search Trees By Action Pruning
Oct 30, 2025One approach to enhance Monte Carlo Tree Search (MCTS) is to improve its sample efficiency by grouping/abstracting states or state-action pairs and sharing statistics within a group. Though state-action pair abstractions are mostly easy to find in algorithms such as On the Go Abstractions in Upper Confidence bounds applied to Trees (OGA-UCT), nearly no state abstractions are found in either noisy or large action space settings due to constraining conditions. We provide theoretical and empirical evidence for this claim, and we slightly alleviate this state abstraction problem by proposing a weaker state abstraction condition that trades a minor loss in accuracy for finding many more abstractions. We name this technique Ideal Pruning Abstractions in UCT (IPA-UCT), which outperforms OGA-UCT (and any of its derivatives) across a large range of test domains and iteration budgets as experimentally validated. IPA-UCT uses a different abstraction framework from Abstraction of State-Action Pairs (ASAP) which is the one used by OGA-UCT, which we name IPA. Furthermore, we show that both IPA and ASAP are special cases of a more general framework that we call p-ASAP which itself is a special case of the ASASAP framework.
Time-critical and confidence-based abstraction dropping methods
Jul 03, 2025One paradigm of Monte Carlo Tree Search (MCTS) improvements is to build and use state and/or action abstractions during the tree search. Non-exact abstractions, however, introduce an approximation error making convergence to the optimal action in the abstract space impossible. Hence, as proposed as a component of Elastic Monte Carlo Tree Search by Xu et al., abstraction algorithms should eventually drop the abstraction. In this paper, we propose two novel abstraction dropping schemes, namely OGA-IAAD and OGA-CAD which can yield clear performance improvements whilst being safe in the sense that the dropping never causes any notable performance degradations contrary to Xu's dropping method. OGA-IAAD is designed for time critical settings while OGA-CAD is designed to improve the MCTS performance with the same number of iterations.
From Code to Play: Benchmarking Program Search for Games Using Large Language Models
Dec 05, 2024



Large language models (LLMs) have shown impressive capabilities in generating program code, opening exciting opportunities for applying program synthesis to games. In this work, we explore the potential of LLMs to directly synthesize usable code for a wide range of gaming applications, focusing on two programming languages, Python and Java. We use an evolutionary hill-climbing algorithm, where the mutations and seeds of the initial programs are controlled by LLMs. For Python, the framework covers various game-related tasks, including five miniature versions of Atari games, ten levels of Baba is You, an environment inspired by Asteroids, and a maze generation task. For Java, the framework contains 12 games from the TAG tabletop games framework. Across 29 tasks, we evaluated 12 language models for Python and 8 for Java. Our findings suggest that the performance of LLMs depends more on the task than on model size. While larger models generate more executable programs, these do not always result in higher-quality solutions but are much more expensive. No model has a clear advantage, although on any specific task, one model may be better. Trying many models on a problem and using the best results across them is more reliable than using just one.
Personalized Dynamic Difficulty Adjustment -- Imitation Learning Meets Reinforcement Learning
Aug 13, 2024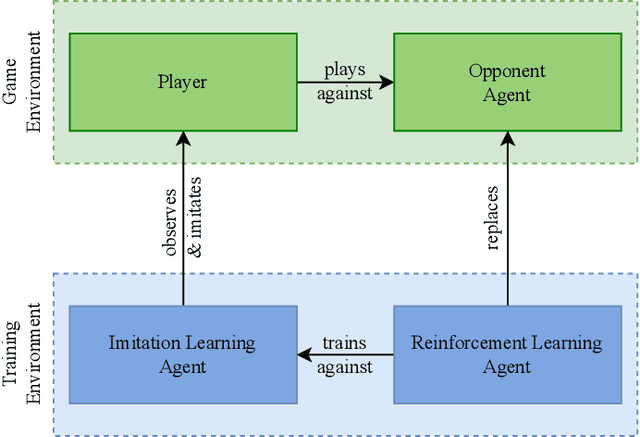
Balancing game difficulty in video games is a key task to create interesting gaming experiences for players. Mismatching the game difficulty and a player's skill or commitment results in frustration or boredom on the player's side, and hence reduces time spent playing the game. In this work, we explore balancing game difficulty using machine learning-based agents to challenge players based on their current behavior. This is achieved by a combination of two agents, in which one learns to imitate the player, while the second is trained to beat the first. In our demo, we investigate the proposed framework for personalized dynamic difficulty adjustment of AI agents in the context of the fighting game AI competition.
Online Optimization of Curriculum Learning Schedules using Evolutionary Optimization
Aug 12, 2024



We propose RHEA CL, which combines Curriculum Learning (CL) with Rolling Horizon Evolutionary Algorithms (RHEA) to automatically produce effective curricula during the training of a reinforcement learning agent. RHEA CL optimizes a population of curricula, using an evolutionary algorithm, and selects the best-performing curriculum as the starting point for the next training epoch. Performance evaluations are conducted after every curriculum step in all environments. We evaluate the algorithm on the \textit{DoorKey} and \textit{DynamicObstacles} environments within the Minigrid framework. It demonstrates adaptability and consistent improvement, particularly in the early stages, while reaching a stable performance later that is capable of outperforming other curriculum learners. In comparison to other curriculum schedules, RHEA CL has been shown to yield performance improvements for the final Reinforcement learning (RL) agent at the cost of additional evaluation during training.
Markov Senior -- Learning Markov Junior Grammars to Generate User-specified Content
Aug 12, 2024



Markov Junior is a probabilistic programming language used for procedural content generation across various domains. However, its reliance on manually crafted and tuned probabilistic rule sets, also called grammars, presents a significant bottleneck, diverging from approaches that allow rule learning from examples. In this paper, we propose a novel solution to this challenge by introducing a genetic programming-based optimization framework for learning hierarchical rule sets automatically. Our proposed method ``Markov Senior'' focuses on extracting positional and distance relations from single input samples to construct probabilistic rules to be used by Markov Junior. Using a Kullback-Leibler divergence-based fitness measure, we search for grammars to generate content that is coherent with the given sample. To enhance scalability, we introduce a divide-and-conquer strategy that enables the efficient generation of large-scale content. We validate our approach through experiments in generating image-based content and Super Mario levels, demonstrating its flexibility and effectiveness. In this way, ``Markov Senior'' allows for the wider application of Markov Junior for tasks in which an example may be available, but the design of a generative rule set is infeasible.
Match Point AI: A Novel AI Framework for Evaluating Data-Driven Tennis Strategies
Aug 12, 2024
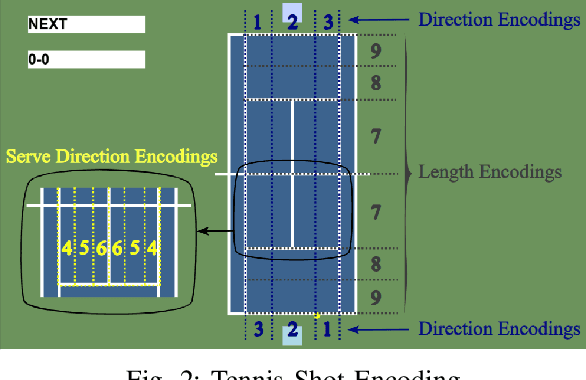
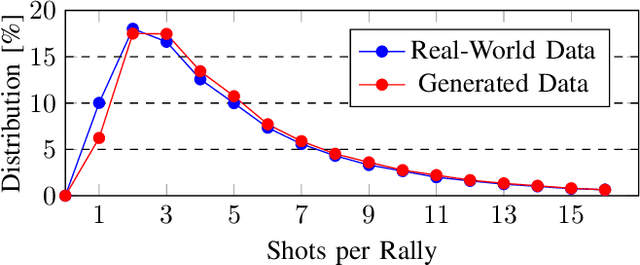
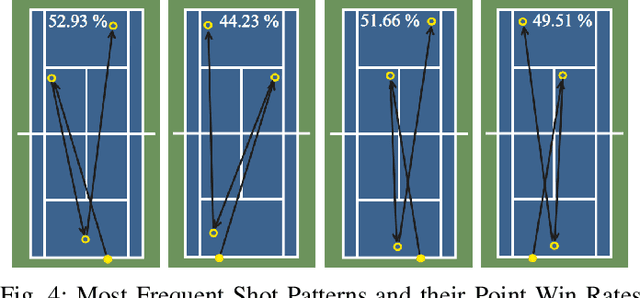
Many works in the domain of artificial intelligence in games focus on board or video games due to the ease of reimplementing their mechanics. Decision-making problems in real-world sports share many similarities to such domains. Nevertheless, not many frameworks on sports games exist. In this paper, we present the tennis match simulation environment \textit{Match Point AI}, in which different agents can compete against real-world data-driven bot strategies. Next to presenting the framework, we highlight its capabilities by illustrating, how MCTS can be used in Match Point AI to optimize the shot direction selection problem in tennis. While the framework will be extended in the future, first experiments already reveal that generated shot-by-shot data of simulated tennis matches show realistic characteristics when compared to real-world data. At the same time, reasonable shot placement strategies emerge, which share similarities to the ones found in real-world tennis matches.
Strategy Game-Playing with Size-Constrained State Abstraction
Aug 12, 2024Playing strategy games is a challenging problem for artificial intelligence (AI). One of the major challenges is the large search space due to a diverse set of game components. In recent works, state abstraction has been applied to search-based game AI and has brought significant performance improvements. State abstraction techniques rely on reducing the search space, e.g., by aggregating similar states. However, the application of these abstractions is hindered because the quality of an abstraction is difficult to evaluate. Previous works hence abandon the abstraction in the middle of the search to not bias the search to a local optimum. This mechanism introduces a hyper-parameter to decide the time to abandon the current state abstraction. In this work, we propose a size-constrained state abstraction (SCSA), an approach that limits the maximum number of nodes being grouped together. We found that with SCSA, the abstraction is not required to be abandoned. Our empirical results on $3$ strategy games show that the SCSA agent outperforms the previous methods and yields robust performance over different games. Codes are open-sourced at \url{https://github.com/GAIGResearch/Stratega}.
Higher Replay Ratio Empowers Sample-Efficient Multi-Agent Reinforcement Learning
Apr 15, 2024



One of the notorious issues for Reinforcement Learning (RL) is poor sample efficiency. Compared to single agent RL, the sample efficiency for Multi-Agent Reinforcement Learning (MARL) is more challenging because of its inherent partial observability, non-stationary training, and enormous strategy space. Although much effort has been devoted to developing new methods and enhancing sample efficiency, we look at the widely used episodic training mechanism. In each training step, tens of frames are collected, but only one gradient step is made. We argue that this episodic training could be a source of poor sample efficiency. To better exploit the data already collected, we propose to increase the frequency of the gradient updates per environment interaction (a.k.a. Replay Ratio or Update-To-Data ratio). To show its generality, we evaluate $3$ MARL methods on $6$ SMAC tasks. The empirical results validate that a higher replay ratio significantly improves the sample efficiency for MARL algorithms. The codes to reimplement the results presented in this paper are open-sourced at https://anonymous.4open.science/r/rr_for_MARL-0D83/.