 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCSP4SDG: Constraint and Information-Theory Based Role Identification in Social Deduction Games with LLM-Enhanced Inference
Nov 09, 2025In Social Deduction Games (SDGs) such as Avalon, Mafia, and Werewolf, players conceal their identities and deliberately mislead others, making hidden-role inference a central and demanding task. Accurate role identification, which forms the basis of an agent's belief state, is therefore the keystone for both human and AI performance. We introduce CSP4SDG, a probabilistic, constraint-satisfaction framework that analyses gameplay objectively. Game events and dialogue are mapped to four linguistically-agnostic constraint classes-evidence, phenomena, assertions, and hypotheses. Hard constraints prune impossible role assignments, while weighted soft constraints score the remainder; information-gain weighting links each hypothesis to its expected value under entropy reduction, and a simple closed-form scoring rule guarantees that truthful assertions converge to classical hard logic with minimum error. The resulting posterior over roles is fully interpretable and updates in real time. Experiments on three public datasets show that CSP4SDG (i) outperforms LLM-based baselines in every inference scenario, and (ii) boosts LLMs when supplied as an auxiliary "reasoning tool." Our study validates that principled probabilistic reasoning with information theory is a scalable alternative-or complement-to heavy-weight neural models for SDGs.
JSON-Bag: A generic game trajectory representation
Aug 01, 2025



We introduce JSON Bag-of-Tokens model (JSON-Bag) as a method to generically represent game trajectories by tokenizing their JSON descriptions and apply Jensen-Shannon distance (JSD) as distance metric for them. Using a prototype-based nearest-neighbor search (P-NNS), we evaluate the validity of JSON-Bag with JSD on six tabletop games -- \textit{7 Wonders}, \textit{Dominion}, \textit{Sea Salt and Paper}, \textit{Can't Stop}, \textit{Connect4}, \textit{Dots and boxes} -- each over three game trajectory classification tasks: classifying the playing agents, game parameters, or game seeds that were used to generate the trajectories. Our approach outperforms a baseline using hand-crafted features in the majority of tasks. Evaluating on N-shot classification suggests using JSON-Bag prototype to represent game trajectory classes is also sample efficient. Additionally, we demonstrate JSON-Bag ability for automatic feature extraction by treating tokens as individual features to be used in Random Forest to solve the tasks above, which significantly improves accuracy on underperforming tasks. Finally, we show that, across all six games, the JSD between JSON-Bag prototypes of agent classes highly correlates with the distances between agents' policies.
Seeding for Success: Skill and Stochasticity in Tabletop Games
Mar 04, 2025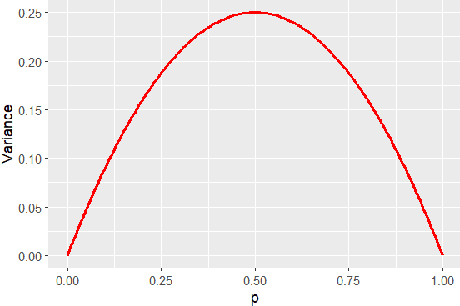



Games often incorporate random elements in the form of dice or shuffled card decks. This randomness is a key contributor to the player experience and the variety of game situations encountered. There is a tension between a level of randomness that makes the game interesting and contributes to the player enjoyment of a game, and a level at which the outcome itself is effectively random and the game becomes dull. The optimal level for a game will depend on the design goals and target audience. We introduce a new technique to quantify the level of randomness in game outcome and use it to compare 15 tabletop games and disentangle the different contributions to the overall randomness from specific parts of some games. We further explore the interaction between game randomness and player skill, and how this innate randomness can affect error analysis in common game experiments.
* Published in IEEE Transactions on Games, 2025
From Code to Play: Benchmarking Program Search for Games Using Large Language Models
Dec 05, 2024



Large language models (LLMs) have shown impressive capabilities in generating program code, opening exciting opportunities for applying program synthesis to games. In this work, we explore the potential of LLMs to directly synthesize usable code for a wide range of gaming applications, focusing on two programming languages, Python and Java. We use an evolutionary hill-climbing algorithm, where the mutations and seeds of the initial programs are controlled by LLMs. For Python, the framework covers various game-related tasks, including five miniature versions of Atari games, ten levels of Baba is You, an environment inspired by Asteroids, and a maze generation task. For Java, the framework contains 12 games from the TAG tabletop games framework. Across 29 tasks, we evaluated 12 language models for Python and 8 for Java. Our findings suggest that the performance of LLMs depends more on the task than on model size. While larger models generate more executable programs, these do not always result in higher-quality solutions but are much more expensive. No model has a clear advantage, although on any specific task, one model may be better. Trying many models on a problem and using the best results across them is more reliable than using just one.
Deduction Game Framework and Information Set Entropy Search
Jul 30, 2024



We present a game framework tailored for deduction games, enabling structured analysis from the perspective of Shannon entropy variations. Additionally, we introduce a new forward search algorithm, Information Set Entropy Search (ISES), which effectively solves many single-player deduction games. The ISES algorithm, augmented with sampling techniques, allows agents to make decisions within controlled computational resources and time constraints. Experimental results on eight games within our framework demonstrate the significant superiority of our method over the Single Observer Information Set Monte Carlo Tree Search(SO-ISMCTS) algorithm under limited decision time constraints. The entropy variation of game states in our framework enables explainable decision-making, which can also be used to analyze the appeal of deduction games and provide insights for game designers.
ADAPTER-RL: Adaptation of Any Agent using Reinforcement Learning
Nov 20, 2023



Deep Reinforcement Learning (DRL) agents frequently face challenges in adapting to tasks outside their training distribution, including issues with over-fitting, catastrophic forgetting and sample inefficiency. Although the application of adapters has proven effective in supervised learning contexts such as natural language processing and computer vision, their potential within the DRL domain remains largely unexplored. This paper delves into the integration of adapters in reinforcement learning, presenting an innovative adaptation strategy that demonstrates enhanced training efficiency and improvement of the base-agent, experimentally in the nanoRTS environment, a real-time strategy (RTS) game simulation. Our proposed universal approach is not only compatible with pre-trained neural networks but also with rule-based agents, offering a means to integrate human expertise.
Partial advantage estimator for proximal policy optimization
Jan 26, 2023Estimation of value in policy gradient methods is a fundamental problem. Generalized Advantage Estimation (GAE) is an exponentially-weighted estimator of an advantage function similar to $\lambda$-return. It substantially reduces the variance of policy gradient estimates at the expense of bias. In practical applications, a truncated GAE is used due to the incompleteness of the trajectory, which results in a large bias during estimation. To address this challenge, instead of using the entire truncated GAE, we propose to take a part of it when calculating updates, which significantly reduces the bias resulting from the incomplete trajectory. We perform experiments in MuJoCo and $\mu$RTS to investigate the effect of different partial coefficient and sampling lengths. We show that our partial GAE approach yields better empirical results in both environments.
Joint action loss for proximal policy optimization
Jan 26, 2023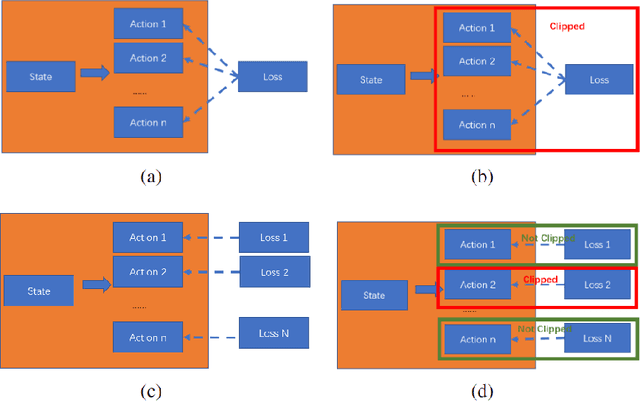

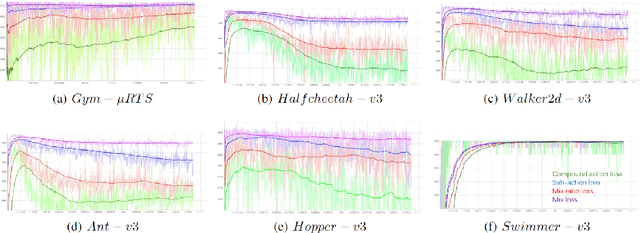
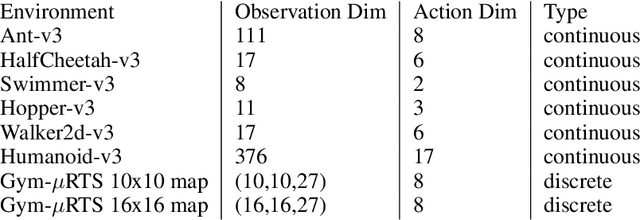
PPO (Proximal Policy Optimization) is a state-of-the-art policy gradient algorithm that has been successfully applied to complex computer games such as Dota 2 and Honor of Kings. In these environments, an agent makes compound actions consisting of multiple sub-actions. PPO uses clipping to restrict policy updates. Although clipping is simple and effective, it is not efficient in its sample use. For compound actions, most PPO implementations consider the joint probability (density) of sub-actions, which means that if the ratio of a sample (state compound-action pair) exceeds the range, the gradient the sample produces is zero. Instead, for each sub-action we calculate the loss separately, which is less prone to clipping during updates thereby making better use of samples. Further, we propose a multi-action mixed loss that combines joint and separate probabilities. We perform experiments in Gym-$\mu$RTS and MuJoCo. Our hybrid model improves performance by more than 50\% in different MuJoCo environments compared to OpenAI's PPO benchmark results. And in Gym-$\mu$RTS, we find the sub-action loss outperforms the standard PPO approach, especially when the clip range is large. Our findings suggest this method can better balance the use-efficiency and quality of samples.
Visualising Multiplayer Game Spaces
Feb 11, 2022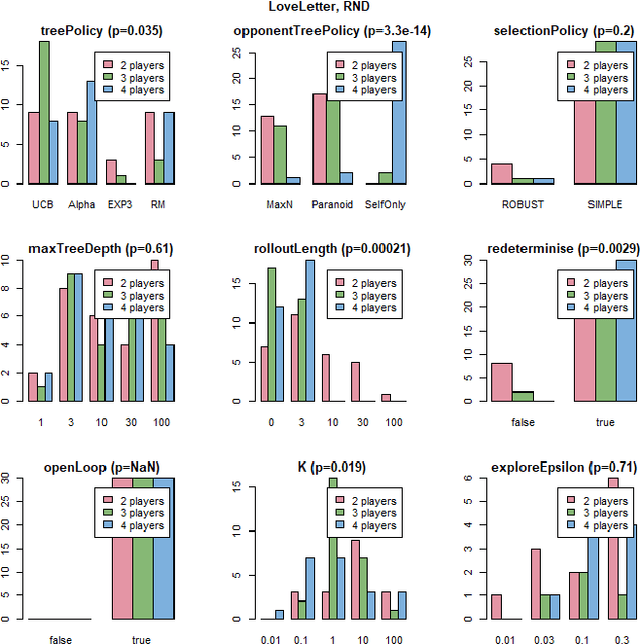
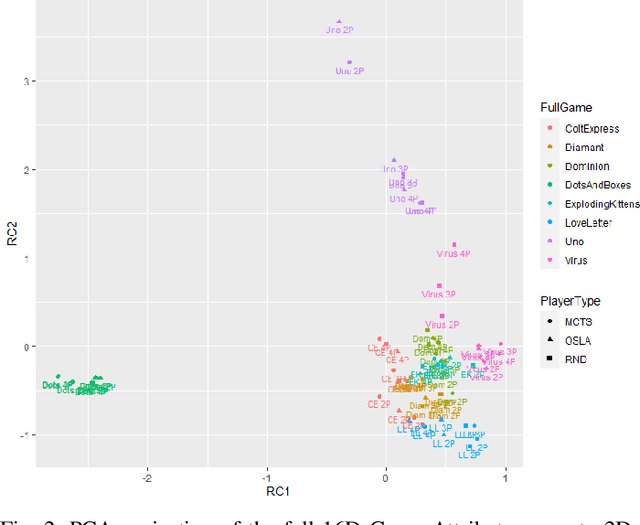
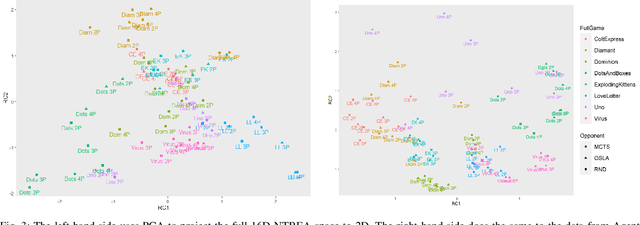
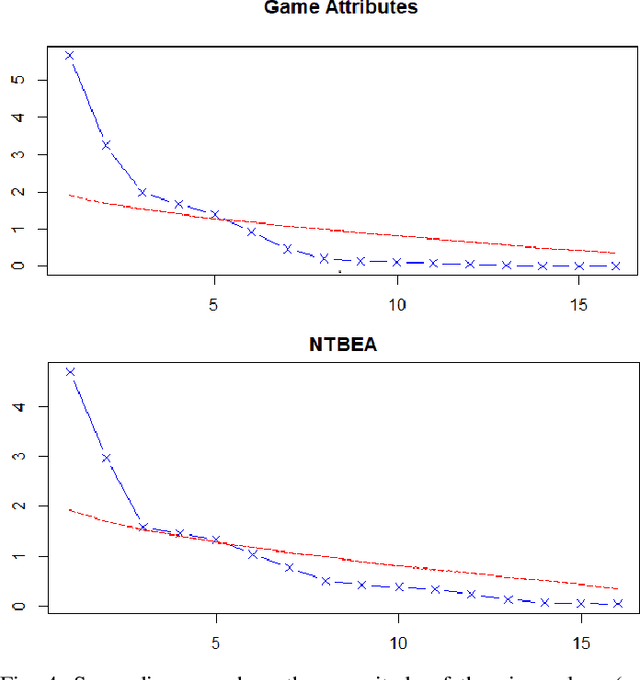
We compare four different `game-spaces' in terms of their usefulness in characterising multi-player tabletop games, with a particular interest in any underlying change to a game's characteristics as the number of players changes. In each case we take a 16-dimensional feature space, and reduce it to a 2-dimensional visualizable landscape. We find that a space obtained from optimization of parameters in Monte Carlo Tree Search (MCTS) is the most directly interpretable to characterise our set of games in terms of the relative importance of imperfect information, adversarial opponents and reward sparsity. These results do not correlate with a space defined using attributes of the game-tree. This dimensionality reduction does not show any general effect as the number of players. We therefore consider the question using the original features to classify the games into two sets; those for which the characteristics of the game changes significantly as the number of players changes, and those for which there is no such effect.
* 13 pages, 7 figures, Accepted for IEEE Transactions on Games
Rinascimento: searching the behaviour space of Splendor
Jun 15, 2021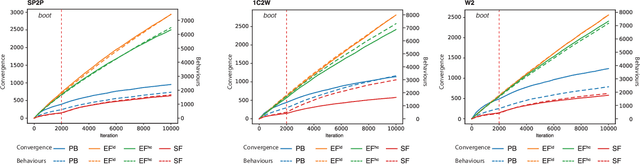
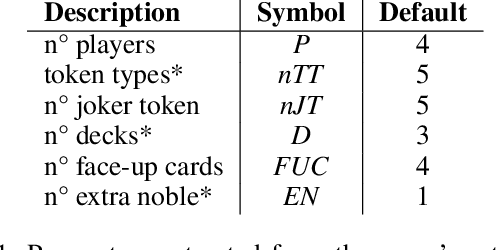
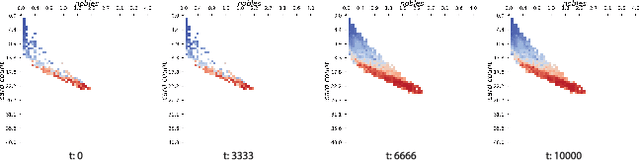

The use of Artificial Intelligence (AI) for play-testing is still on the sidelines of main applications of AI in games compared to performance-oriented game-playing. One of the main purposes of play-testing a game is gathering data on the gameplay, highlighting good and bad features of the design of the game, providing useful insight to the game designers for improving the design. Using AI agents has the potential of speeding the process dramatically. The purpose of this research is to map the behavioural space (BSpace) of a game by using a general method. Using the MAP-Elites algorithm we search the hyperparameter space Rinascimento AI agents and map it to the BSpace defined by several behavioural metrics. This methodology was able to highlight both exemplary and degenerated behaviours in the original game design of Splendor and two variations. In particular, the use of event-value functions has generally shown a remarkable improvement in the coverage of the BSpace compared to agents based on classic score-based reward signals.