 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeding for Success: Skill and Stochasticity in Tabletop Games
Mar 04, 2025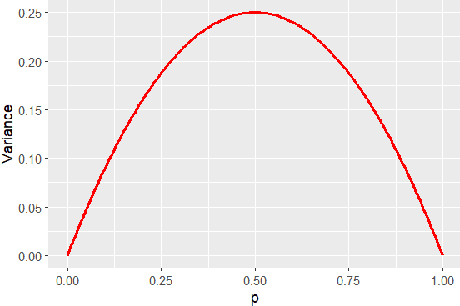



Games often incorporate random elements in the form of dice or shuffled card decks. This randomness is a key contributor to the player experience and the variety of game situations encountered. There is a tension between a level of randomness that makes the game interesting and contributes to the player enjoyment of a game, and a level at which the outcome itself is effectively random and the game becomes dull. The optimal level for a game will depend on the design goals and target audience. We introduce a new technique to quantify the level of randomness in game outcome and use it to compare 15 tabletop games and disentangle the different contributions to the overall randomness from specific parts of some games. We further explore the interaction between game randomness and player skill, and how this innate randomness can affect error analysis in common game experiments.
* Published in IEEE Transactions on Games, 2025
From Code to Play: Benchmarking Program Search for Games Using Large Language Models
Dec 05, 2024



Large language models (LLMs) have shown impressive capabilities in generating program code, opening exciting opportunities for applying program synthesis to games. In this work, we explore the potential of LLMs to directly synthesize usable code for a wide range of gaming applications, focusing on two programming languages, Python and Java. We use an evolutionary hill-climbing algorithm, where the mutations and seeds of the initial programs are controlled by LLMs. For Python, the framework covers various game-related tasks, including five miniature versions of Atari games, ten levels of Baba is You, an environment inspired by Asteroids, and a maze generation task. For Java, the framework contains 12 games from the TAG tabletop games framework. Across 29 tasks, we evaluated 12 language models for Python and 8 for Java. Our findings suggest that the performance of LLMs depends more on the task than on model size. While larger models generate more executable programs, these do not always result in higher-quality solutions but are much more expensive. No model has a clear advantage, although on any specific task, one model may be better. Trying many models on a problem and using the best results across them is more reliable than using just one.
PyTAG: Tabletop Games for Multi-Agent Reinforcement Learning
May 28, 2024



Modern Tabletop Games present various interesting challenges for Multi-agent Reinforcement Learning. In this paper, we introduce PyTAG, a new framework that supports interacting with a large collection of games implemented in the Tabletop Games framework. In this work we highlight the challenges tabletop games provide, from a game-playing agent perspective, along with the opportunities they provide for future research. Additionally, we highlight the technical challenges that involve training Reinforcement Learning agents on these games. To explore the Multi-agent setting provided by PyTAG we train the popular Proximal Policy Optimisation Reinforcement Learning algorithm using self-play on a subset of games and evaluate the trained policies against some simple agents and Monte-Carlo Tree Search implemented in the Tabletop Games framework.
PyTAG: Challenges and Opportunities for Reinforcement Learning in Tabletop Games
Jul 19, 2023



In recent years, Game AI research has made important breakthroughs using Reinforcement Learning (RL). Despite this, RL for modern tabletop games has gained little to no attention, even when they offer a range of unique challenges compared to video games. To bridge this gap, we introduce PyTAG, a Python API for interacting with the Tabletop Games framework (TAG). TAG contains a growing set of more than 20 modern tabletop games, with a common API for AI agents. We present techniques for training RL agents in these games and introduce baseline results after training Proximal Policy Optimisation algorithms on a subset of games. Finally, we discuss the unique challenges complex modern tabletop games provide, now open to RL research through PyTAG.
Visualising Multiplayer Game Spaces
Feb 11, 2022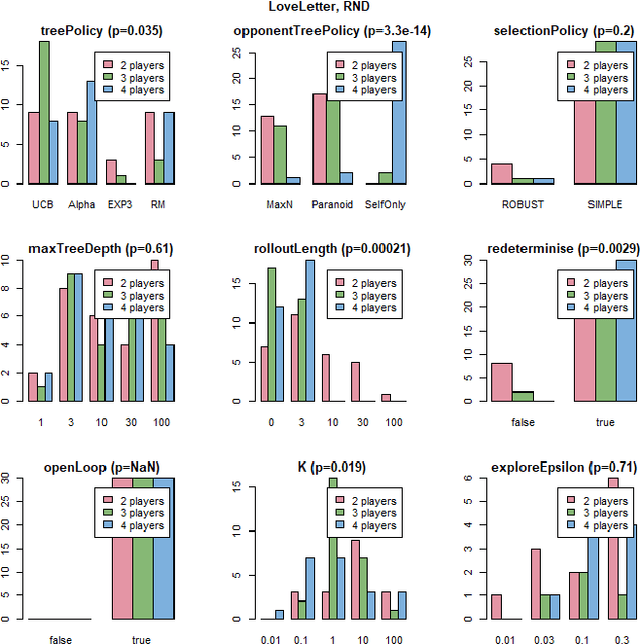
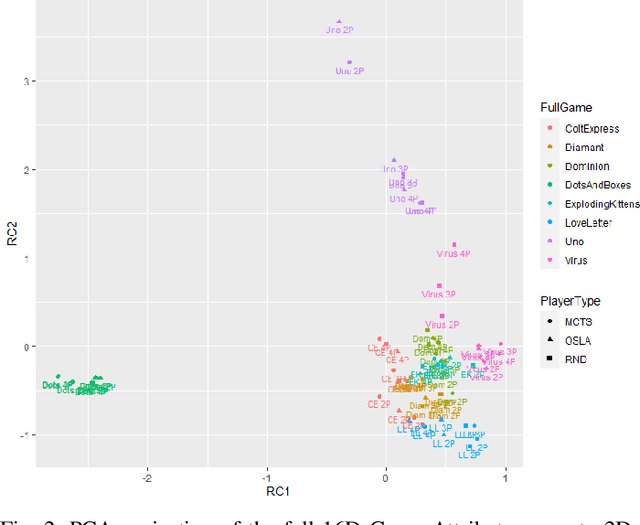
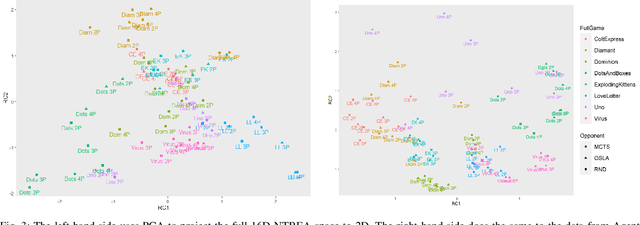
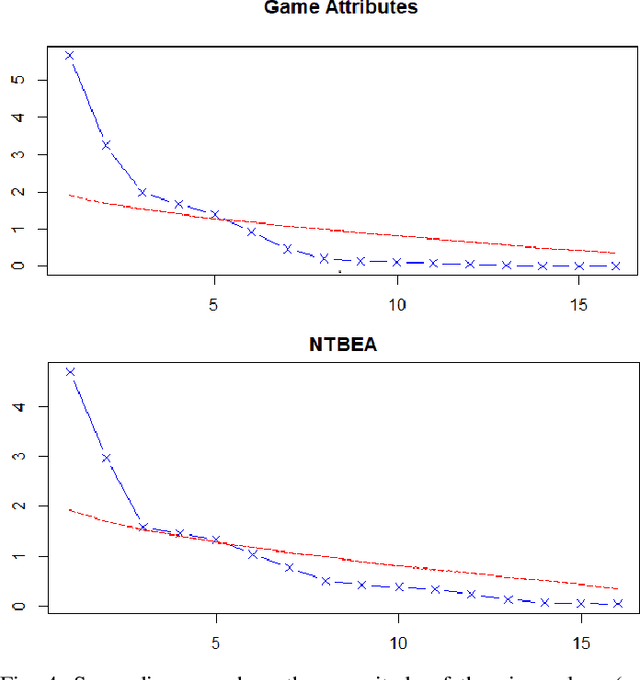
We compare four different `game-spaces' in terms of their usefulness in characterising multi-player tabletop games, with a particular interest in any underlying change to a game's characteristics as the number of players changes. In each case we take a 16-dimensional feature space, and reduce it to a 2-dimensional visualizable landscape. We find that a space obtained from optimization of parameters in Monte Carlo Tree Search (MCTS) is the most directly interpretable to characterise our set of games in terms of the relative importance of imperfect information, adversarial opponents and reward sparsity. These results do not correlate with a space defined using attributes of the game-tree. This dimensionality reduction does not show any general effect as the number of players. We therefore consider the question using the original features to classify the games into two sets; those for which the characteristics of the game changes significantly as the number of players changes, and those for which there is no such effect.
* 13 pages, 7 figures, Accepted for IEEE Transactions on Games
AI and Wargaming
Sep 25, 2020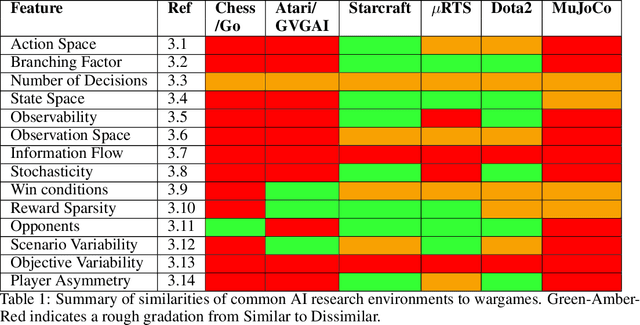


Recent progress in Game AI has demonstrated that given enough data from human gameplay, or experience gained via simulations, machines can rival or surpass the most skilled human players in classic games such as Go, or commercial computer games such as Starcraft. We review the current state-of-the-art through the lens of wargaming, and ask firstly what features of wargames distinguish them from the usual AI testbeds, and secondly which recent AI advances are best suited to address these wargame-specific features.
Does it matter how well I know what you're thinking? Opponent Modelling in an RTS game
Jun 15, 2020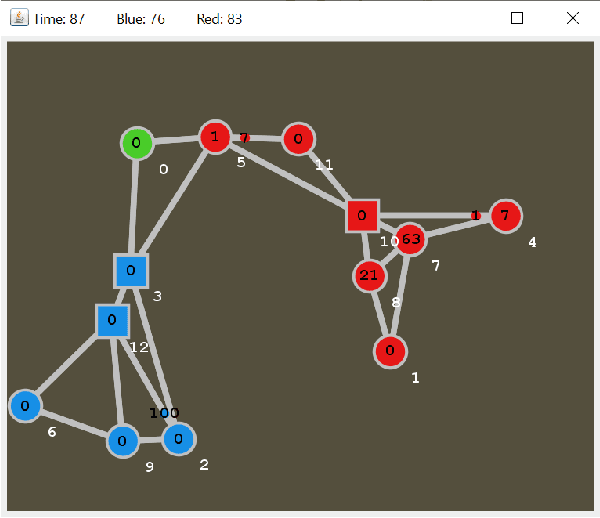
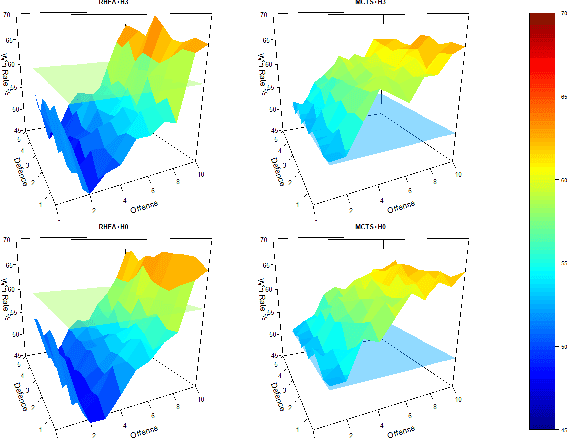
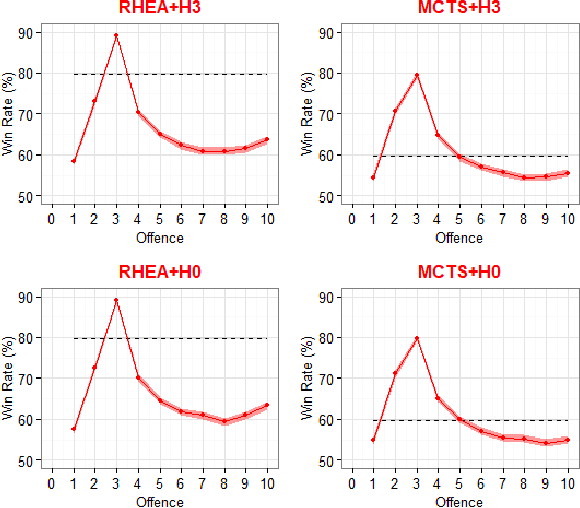
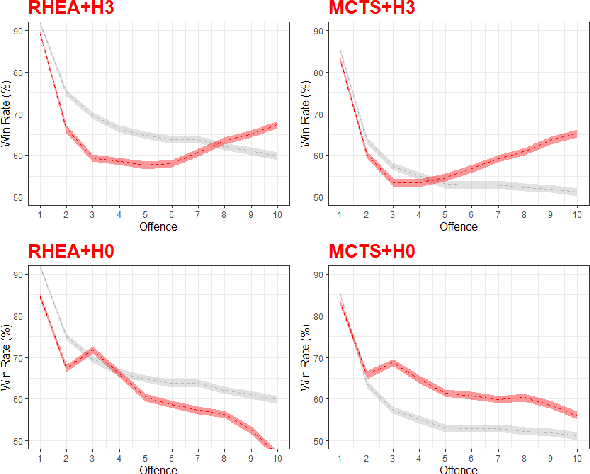
Opponent Modelling tries to predict the future actions of opponents, and is required to perform well in multi-player games. There is a deep literature on learning an opponent model, but much less on how accurate such models must be to be useful. We investigate the sensitivity of Monte Carlo Tree Search (MCTS) and a Rolling Horizon Evolutionary Algorithm (RHEA) to the accuracy of their modelling of the opponent in a simple Real-Time Strategy game. We find that in this domain RHEA is much more sensitive to the accuracy of an opponent model than MCTS. MCTS generally does better even with an inaccurate model, while this will degrade RHEA's performance. We show that faced with an unknown opponent and a low computational budget it is better not to use any explicit model with RHEA, and to model the opponent's actions within the tree as part of the MCTS algorithm.
Metagame Autobalancing for Competitive Multiplayer Games
Jun 08, 2020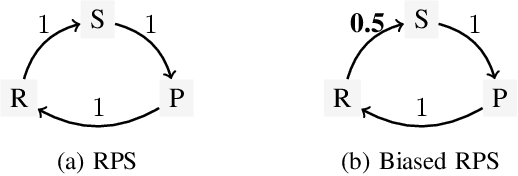
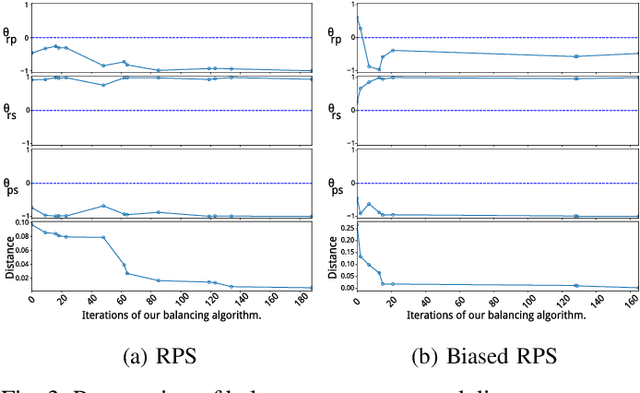

Automated game balancing has often focused on single-agent scenarios. In this paper we present a tool for balancing multi-player games during game design. Our approach requires a designer to construct an intuitive graphical representation of their meta-game target, representing the relative scores that high-level strategies (or decks, or character types) should experience. This permits more sophisticated balance targets to be defined beyond a simple requirement of equal win chances. We then find a parameterization of the game that meets this target using simulation-based optimization to minimize the distance to the target graph. We show the capabilities of this tool on examples inheriting from Rock-Paper-Scissors, and on a more complex asymmetric fighting game.
Weighting NTBEA for Game AI Optimisation
Apr 01, 2020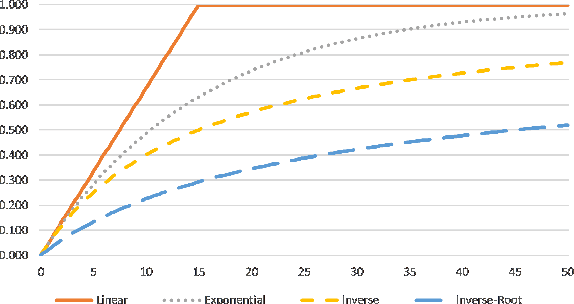

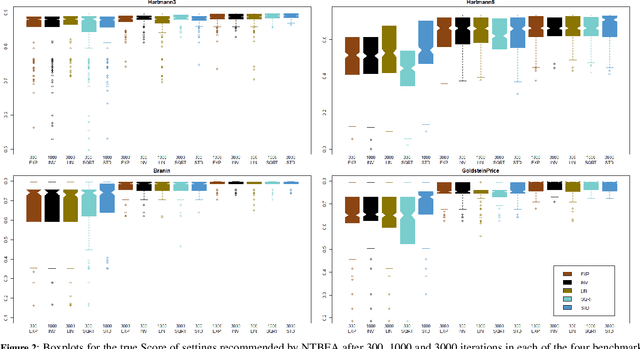
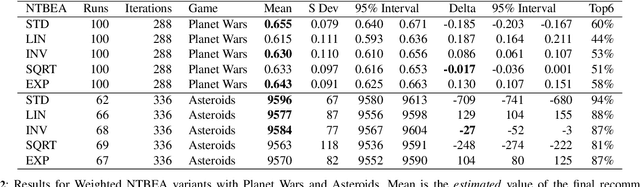
The N-Tuple Bandit Evolutionary Algorithm (NTBEA) has proven very effective in optimising algorithm parameters in Game AI. A potential weakness is the use of a simple average of all component Tuples in the model. This study investigates a refinement to the N-Tuple model used in NTBEA by weighting these component Tuples by their level of information and specificity of match. We introduce weighting functions to the model to obtain Weighted- NTBEA and test this on four benchmark functions and two game environments. These tests show that vanilla NTBEA is the most reliable and performant of the algorithms tested. Furthermore we show that given an iteration budget it is better to execute several independent NTBEA runs, and use part of the budget to find the best recommendation from these runs.
Re-determinizing Information Set Monte Carlo Tree Search in Hanabi
Feb 16, 2019

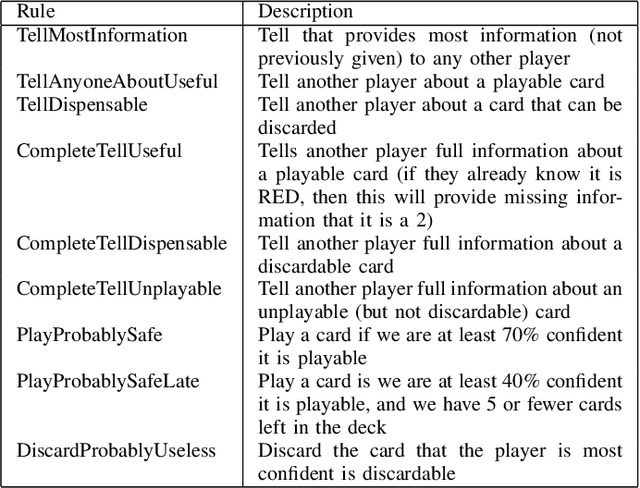
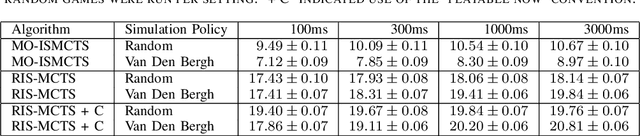
This technical report documents the winner of the Computational Intelligence in Games(CIG) 2018 Hanabi competition. We introduce Re-determinizing IS-MCTS, a novel extension of Information Set Monte Carlo Tree Search (IS-MCTS) \cite{IS-MCTS} that prevents a leakage of hidden information into opponent models that can occur in IS-MCTS, and is particularly severe in Hanabi. Re-determinizing IS-MCTS scores higher in Hanabi for 2-4 players than previously published work. Given the 40ms competition time limit per move we use a learned evaluation function to estimate leaf node values and avoid full simulations during MCTS. For the Mixed track competition, in which the identity of the other players is unknown, a simple Bayesian opponent model is used that is updated as each game proceeds.