 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoundation Models as World Models: A Foundational Study in Text-Based GridWorlds
Sep 19, 2025



While reinforcement learning from scratch has shown impressive results in solving sequential decision-making tasks with efficient simulators, real-world applications with expensive interactions require more sample-efficient agents. Foundation models (FMs) are natural candidates to improve sample efficiency as they possess broad knowledge and reasoning capabilities, but it is yet unclear how to effectively integrate them into the reinforcement learning framework. In this paper, we anticipate and, most importantly, evaluate two promising strategies. First, we consider the use of foundation world models (FWMs) that exploit the prior knowledge of FMs to enable training and evaluating agents with simulated interactions. Second, we consider the use of foundation agents (FAs) that exploit the reasoning capabilities of FMs for decision-making. We evaluate both approaches empirically in a family of grid-world environments that are suitable for the current generation of large language models (LLMs). Our results suggest that improvements in LLMs already translate into better FWMs and FAs; that FAs based on current LLMs can already provide excellent policies for sufficiently simple environments; and that the coupling of FWMs and reinforcement learning agents is highly promising for more complex settings with partial observability and stochastic elements.
Playing NetHack with LLMs: Potential & Limitations as Zero-Shot Agents
Mar 01, 2024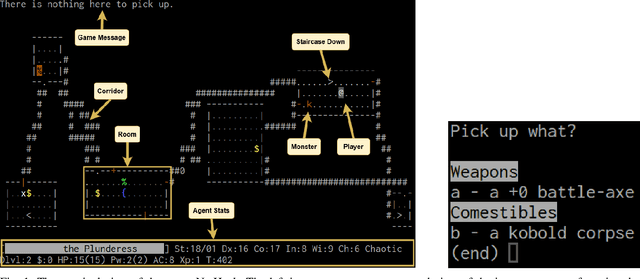
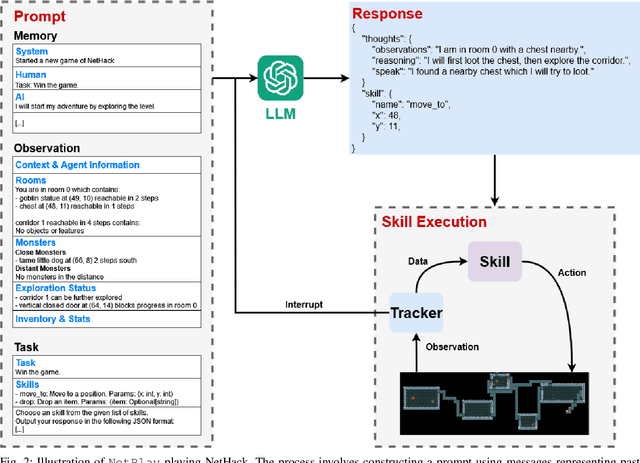


Large Language Models (LLMs) have shown great success as high-level planners for zero-shot game-playing agents. However, these agents are primarily evaluated on Minecraft, where long-term planning is relatively straightforward. In contrast, agents tested in dynamic robot environments face limitations due to simplistic environments with only a few objects and interactions. To fill this gap in the literature, we present NetPlay, the first LLM-powered zero-shot agent for the challenging roguelike NetHack. NetHack is a particularly challenging environment due to its diverse set of items and monsters, complex interactions, and many ways to die. NetPlay uses an architecture designed for dynamic robot environments, modified for NetHack. Like previous approaches, it prompts the LLM to choose from predefined skills and tracks past interactions to enhance decision-making. Given NetHack's unpredictable nature, NetPlay detects important game events to interrupt running skills, enabling it to react to unforeseen circumstances. While NetPlay demonstrates considerable flexibility and proficiency in interacting with NetHack's mechanics, it struggles with ambiguous task descriptions and a lack of explicit feedback. Our findings demonstrate that NetPlay performs best with detailed context information, indicating the necessity for dynamic methods in supplying context information for complex games such as NetHack.
PyTAG: Challenges and Opportunities for Reinforcement Learning in Tabletop Games
Jul 19, 2023In recent years, Game AI research has made important breakthroughs using Reinforcement Learning (RL). Despite this, RL for modern tabletop games has gained little to no attention, even when they offer a range of unique challenges compared to video games. To bridge this gap, we introduce PyTAG, a Python API for interacting with the Tabletop Games framework (TAG). TAG contains a growing set of more than 20 modern tabletop games, with a common API for AI agents. We present techniques for training RL agents in these games and introduce baseline results after training Proximal Policy Optimisation algorithms on a subset of games. Finally, we discuss the unique challenges complex modern tabletop games provide, now open to RL research through PyTAG.
Portfolio Search and Optimization for General Strategy Game-Playing
Apr 21, 2021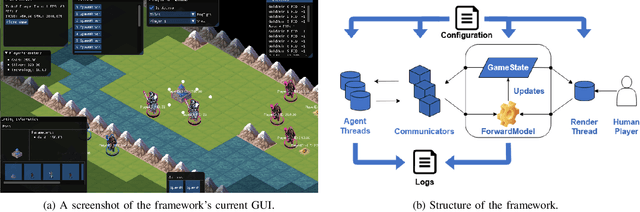

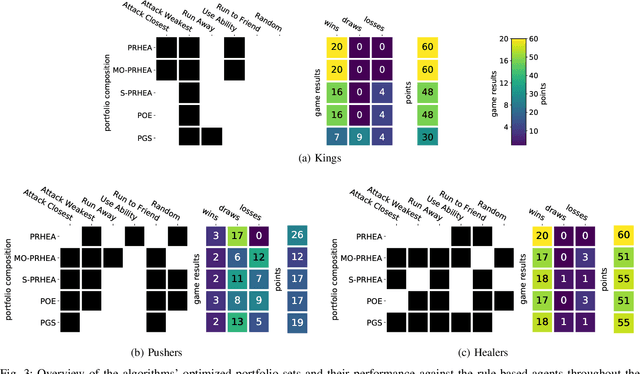
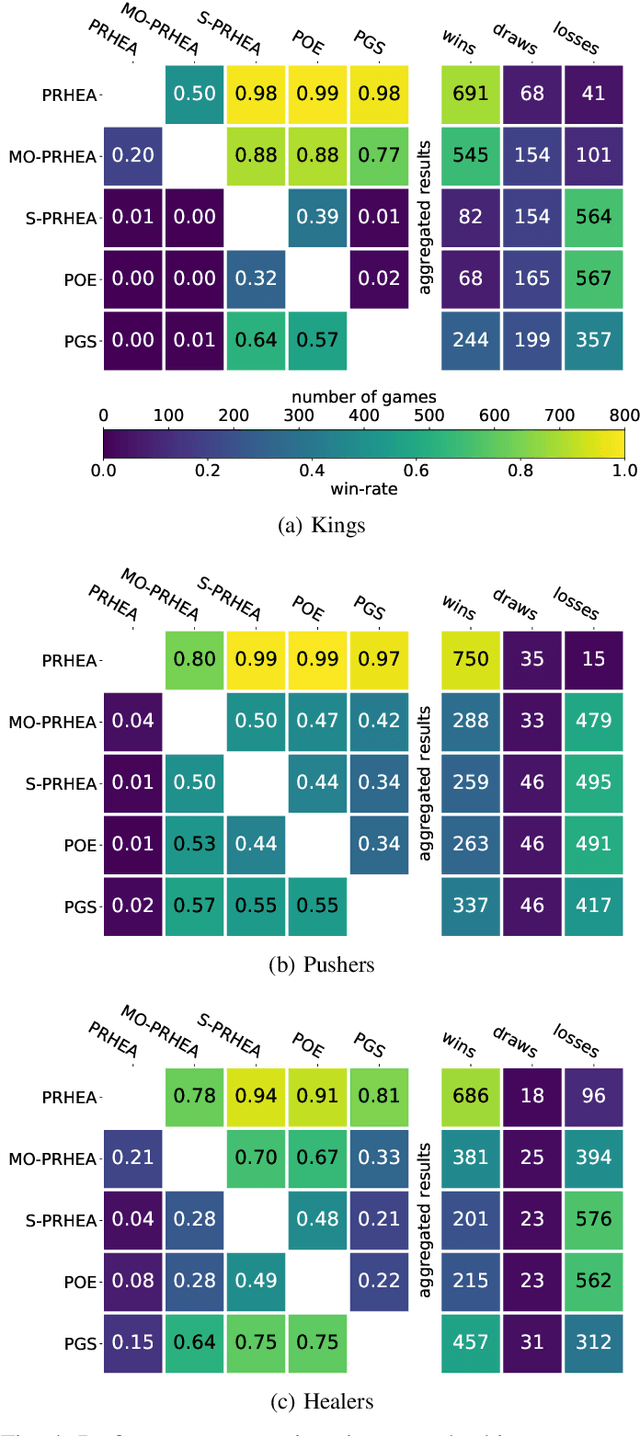
Portfolio methods represent a simple but efficient type of action abstraction which has shown to improve the performance of search-based agents in a range of strategy games. We first review existing portfolio techniques and propose a new algorithm for optimization and action-selection based on the Rolling Horizon Evolutionary Algorithm. Moreover, a series of variants are developed to solve problems in different aspects. We further analyze the performance of discussed agents in a general strategy game-playing task. For this purpose, we run experiments on three different game-modes of the Stratega framework. For the optimization of the agents' parameters and portfolio sets we study the use of the N-tuple Bandit Evolutionary Algorithm. The resulting portfolio sets suggest a high diversity in play-styles while being able to consistently beat the sample agents. An analysis of the agents' performance shows that the proposed algorithm generalizes well to all game-modes and is able to outperform other portfolio methods.
Generating Diverse and Competitive Play-Styles for Strategy Games
Apr 17, 2021



Designing agents that are able to achieve different play-styles while maintaining a competitive level of play is a difficult task, especially for games for which the research community has not found super-human performance yet, like strategy games. These require the AI to deal with large action spaces, long-term planning and partial observability, among other well-known factors that make decision-making a hard problem. On top of this, achieving distinct play-styles using a general algorithm without reducing playing strength is not trivial. In this paper, we propose Portfolio Monte Carlo Tree Search with Progressive Unpruning for playing a turn-based strategy game (Tribes) and show how it can be parameterized so a quality-diversity algorithm (MAP-Elites) is used to achieve different play-styles while keeping a competitive level of play. Our results show that this algorithm is capable of achieving these goals even for an extensive collection of game levels beyond those used for training.
The Design Of "Stratega": A General Strategy Games Framework
Sep 11, 2020
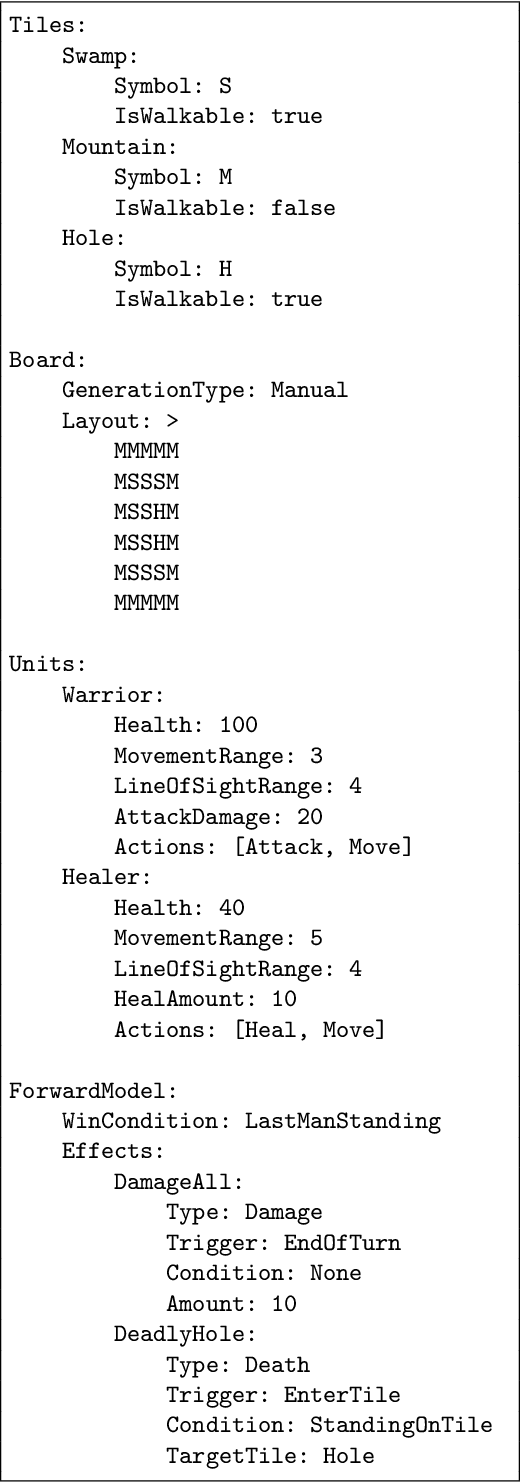
Stratega, a general strategy games framework, has been designed to foster research on computational intelligence for strategy games. In contrast to other strategy game frameworks, Stratega allows to create a wide variety of turn-based and real-time strategy games using a common API for agent development. While the current version supports the development of turn-based strategy games and agents, we will add support for real-time strategy games in future updates. Flexibility is achieved by utilising YAML-files to configure tiles, units, actions, and levels. Therefore, the user can design and run a variety of games to test developed agents without specifically adjusting it to the game being generated. The framework has been built with a focus of statistical forward planning (SFP) agents. For this purpose, agents can access and modify game-states and use the forward model to simulate the outcome of their actions. While SFP agents have shown great flexibility in general game-playing, their performance is limited in case of complex state and action-spaces. Finally, we hope that the development of this framework and its respective agents helps to better understand the complex decision-making process in strategy games. Stratega can be downloaded at: https://github.research.its.qmul.ac.uk/eecsgameai/Stratega