 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Environments Using Exploratory Agents
Sep 04, 2024



Exploration is a key part of many video games. We investigate the using an exploratory agent to provide feedback on the design of procedurally generated game levels, 5 engaging levels and 5 unengaging levels. We expand upon a framework introduced in previous research which models motivations for exploration and introduce a fitness function for evaluating an environment's potential for exploration. Our study showed that our exploratory agent can clearly distinguish between engaging and unengaging levels. The findings suggest that our agent has the potential to serve as an effective tool for assessing procedurally generated levels, in terms of exploration. This work contributes to the growing field of AI-driven game design by offering new insights into how game environments can be evaluated and optimised for player exploration.
Playing NetHack with LLMs: Potential & Limitations as Zero-Shot Agents
Mar 01, 2024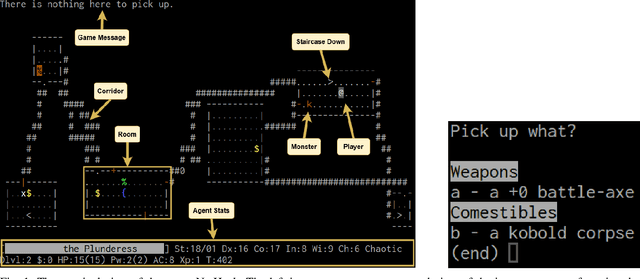
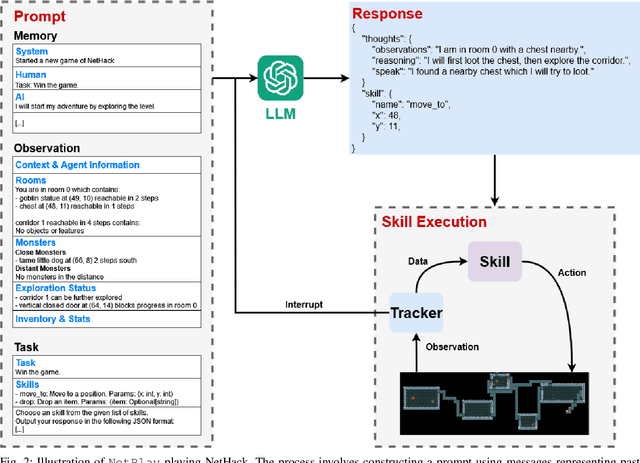


Large Language Models (LLMs) have shown great success as high-level planners for zero-shot game-playing agents. However, these agents are primarily evaluated on Minecraft, where long-term planning is relatively straightforward. In contrast, agents tested in dynamic robot environments face limitations due to simplistic environments with only a few objects and interactions. To fill this gap in the literature, we present NetPlay, the first LLM-powered zero-shot agent for the challenging roguelike NetHack. NetHack is a particularly challenging environment due to its diverse set of items and monsters, complex interactions, and many ways to die. NetPlay uses an architecture designed for dynamic robot environments, modified for NetHack. Like previous approaches, it prompts the LLM to choose from predefined skills and tracks past interactions to enhance decision-making. Given NetHack's unpredictable nature, NetPlay detects important game events to interrupt running skills, enabling it to react to unforeseen circumstances. While NetPlay demonstrates considerable flexibility and proficiency in interacting with NetHack's mechanics, it struggles with ambiguous task descriptions and a lack of explicit feedback. Our findings demonstrate that NetPlay performs best with detailed context information, indicating the necessity for dynamic methods in supplying context information for complex games such as NetHack.
Action Advising with Advice Imitation in Deep Reinforcement Learning
Apr 17, 2021

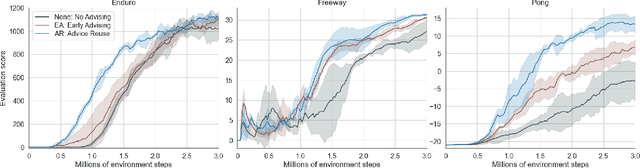
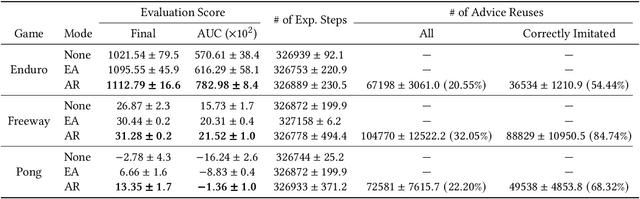
Action advising is a peer-to-peer knowledge exchange technique built on the teacher-student paradigm to alleviate the sample inefficiency problem in deep reinforcement learning. Recently proposed student-initiated approaches have obtained promising results. However, due to being in the early stages of development, these also have some substantial shortcomings. One of the abilities that are absent in the current methods is further utilising advice by reusing, which is especially crucial in the practical settings considering the budget and cost constraints in peer-to-peer. In this study, we present an approach to enable the student agent to imitate previously acquired advice to reuse them directly in its exploration policy, without any interventions in the learning mechanism itself. In particular, we employ a behavioural cloning module to imitate the teacher policy and use dropout regularisation to have a notion of epistemic uncertainty to keep track of which state-advice pairs are actually collected. As the results of experiments we conducted in three Atari games show, advice reusing via generalisation is indeed a feasible option in deep RL and our approach can successfully achieve this while significantly improving the learning performance, even when paired with a simple early advising heuristic.
Learning on a Budget via Teacher Imitation
Apr 17, 2021


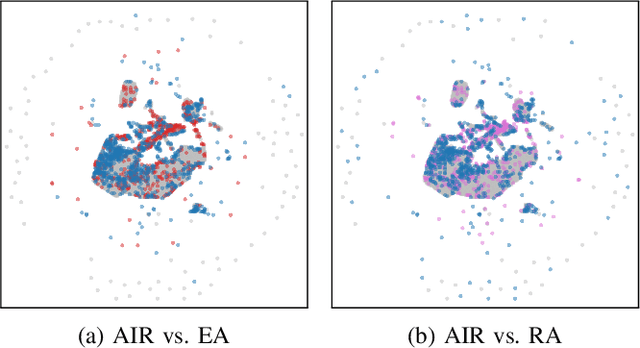
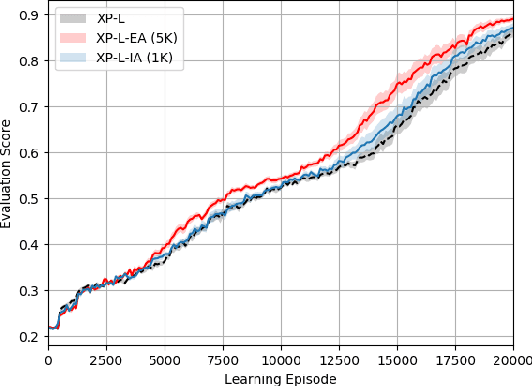
Deep Reinforcement Learning (RL) techniques can benefit greatly from leveraging prior experience, which can be either self-generated or acquired from other entities. Action advising is a framework that provides a flexible way to transfer such knowledge in the form of actions between teacher-student peers. However, due to the realistic concerns, the number of these interactions is limited with a budget; therefore, it is crucial to perform these in the most appropriate moments. There have been several promising studies recently that address this problem setting especially from the student's perspective. Despite their success, they have some shortcomings when it comes to the practical applicability and integrity as an overall solution to the learning from advice challenge. In this paper, we extend the idea of advice reusing via teacher imitation to construct a unified approach that addresses both advice collection and advice utilisation problems. Furthermore, we also propose a method to automatically determine the relevant hyperparameters of these components on-the-fly to make it able to adapt to any task with minimal human intervention. The experiments we performed in 5 different Atari games verify that our algorithm can outperform its competitors by achieving state-of-the-art performance, and its components themselves also provides significant advantages individually.
Teaching on a Budget in Multi-Agent Deep Reinforcement Learning
May 28, 2019


Deep Reinforcement Learning (RL) algorithms can solve complex sequential decision tasks successfully. However, they have a major drawback of having poor sample efficiency which can often be tackled by knowledge reuse. In Multi-Agent Reinforcement Learning (MARL) this drawback becomes worse, but at the same time, a new set of opportunities to leverage knowledge are also presented through agent interactions. One promising approach among these is peer-to-peer action advising through a teacher-student framework. Despite being introduced for single-agent RL originally, recent studies show that it can also be applied to multi-agent scenarios with promising empirical results. However, studies in this line of research are currently very limited. In this paper, we propose heuristics-based action advising techniques in cooperative decentralised MARL, using a nonlinear function approximation based task-level policy. By adopting Random Network Distillation technique, we devise a measurement for agents to assess their knowledge in any given state and be able to initiate the teacher-student dynamics with no prior role assumptions. Experimental results in a gridworld environment show that such an approach may indeed be useful and needs to be further investigated.