 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAction Advising with Advice Imitation in Deep Reinforcement Learning
Paper and Code

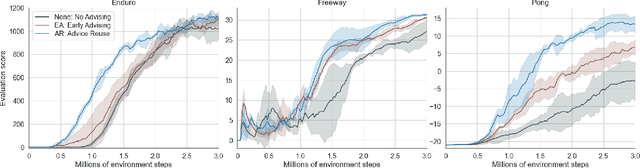
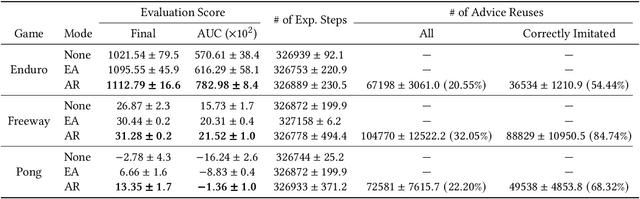
Action advising is a peer-to-peer knowledge exchange technique built on the teacher-student paradigm to alleviate the sample inefficiency problem in deep reinforcement learning. Recently proposed student-initiated approaches have obtained promising results. However, due to being in the early stages of development, these also have some substantial shortcomings. One of the abilities that are absent in the current methods is further utilising advice by reusing, which is especially crucial in the practical settings considering the budget and cost constraints in peer-to-peer. In this study, we present an approach to enable the student agent to imitate previously acquired advice to reuse them directly in its exploration policy, without any interventions in the learning mechanism itself. In particular, we employ a behavioural cloning module to imitate the teacher policy and use dropout regularisation to have a notion of epistemic uncertainty to keep track of which state-advice pairs are actually collected. As the results of experiments we conducted in three Atari games show, advice reusing via generalisation is indeed a feasible option in deep RL and our approach can successfully achieve this while significantly improving the learning performance, even when paired with a simple early advising heuristic.