 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptEx: A Self-Service Contextual Bandit Platform
Aug 08, 2023This paper presents AdaptEx, a self-service contextual bandit platform widely used at Expedia Group, that leverages multi-armed bandit algorithms to personalize user experiences at scale. AdaptEx considers the unique context of each visitor to select the optimal variants and learns quickly from every interaction they make. It offers a powerful solution to improve user experiences while minimizing the costs and time associated with traditional testing methods. The platform unlocks the ability to iterate towards optimal product solutions quickly, even in ever-changing content and continuous "cold start" situations gracefully.
Action Advising with Advice Imitation in Deep Reinforcement Learning
Apr 17, 2021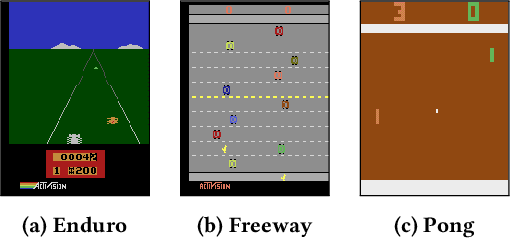

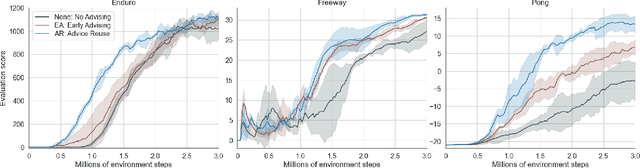
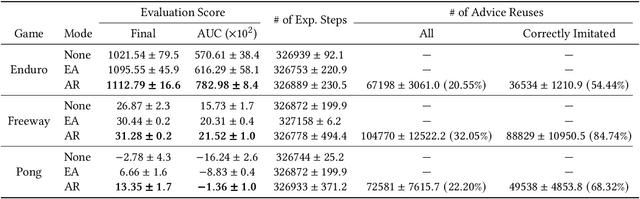
Action advising is a peer-to-peer knowledge exchange technique built on the teacher-student paradigm to alleviate the sample inefficiency problem in deep reinforcement learning. Recently proposed student-initiated approaches have obtained promising results. However, due to being in the early stages of development, these also have some substantial shortcomings. One of the abilities that are absent in the current methods is further utilising advice by reusing, which is especially crucial in the practical settings considering the budget and cost constraints in peer-to-peer. In this study, we present an approach to enable the student agent to imitate previously acquired advice to reuse them directly in its exploration policy, without any interventions in the learning mechanism itself. In particular, we employ a behavioural cloning module to imitate the teacher policy and use dropout regularisation to have a notion of epistemic uncertainty to keep track of which state-advice pairs are actually collected. As the results of experiments we conducted in three Atari games show, advice reusing via generalisation is indeed a feasible option in deep RL and our approach can successfully achieve this while significantly improving the learning performance, even when paired with a simple early advising heuristic.
Learning on a Budget via Teacher Imitation
Apr 17, 2021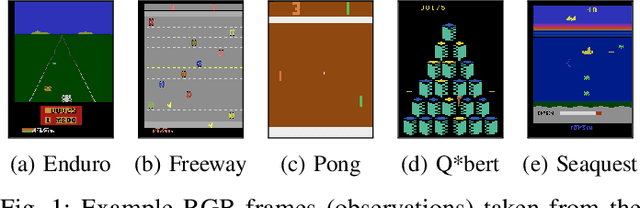


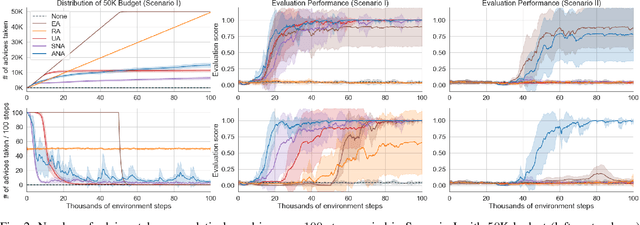
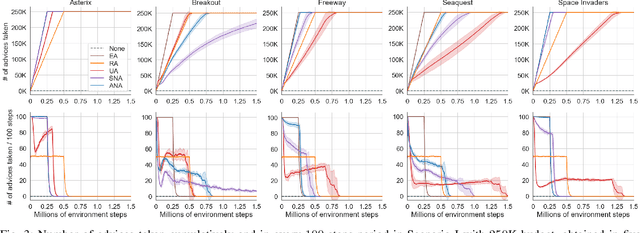
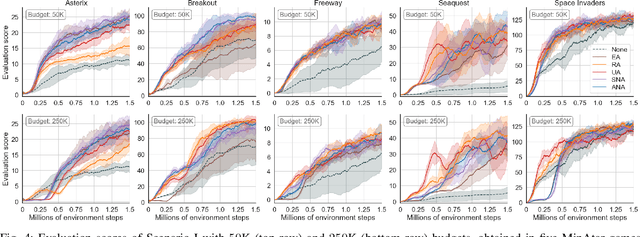
Deep Reinforcement Learning (RL) techniques can benefit greatly from leveraging prior experience, which can be either self-generated or acquired from other entities. Action advising is a framework that provides a flexible way to transfer such knowledge in the form of actions between teacher-student peers. However, due to the realistic concerns, the number of these interactions is limited with a budget; therefore, it is crucial to perform these in the most appropriate moments. There have been several promising studies recently that address this problem setting especially from the student's perspective. Despite their success, they have some shortcomings when it comes to the practical applicability and integrity as an overall solution to the learning from advice challenge. In this paper, we extend the idea of advice reusing via teacher imitation to construct a unified approach that addresses both advice collection and advice utilisation problems. Furthermore, we also propose a method to automatically determine the relevant hyperparameters of these components on-the-fly to make it able to adapt to any task with minimal human intervention. The experiments we performed in 5 different Atari games verify that our algorithm can outperform its competitors by achieving state-of-the-art performance, and its components themselves also provides significant advantages individually.
Student-Initiated Action Advising via Advice Novelty
Oct 01, 2020
Action advising is a knowledge exchange mechanism between peers, namely student and teacher, that can help tackle exploration and sample inefficiency problems in deep reinforcement learning. Due to the practical limitations in peer-to-peer communication and the negative implications of over-advising, the peer responsible for initiating these interactions needs to do so only when it's most adequate to exchange advice. Most recently, student-initiated techniques that utilise state novelty and uncertainty estimations have obtained promising results. However, these estimations have several weaknesses, such as having no information regarding the characteristics of convergence and being subject to delays that occur in the presence of experience replay dynamics. We propose a student-initiated action advising algorithm that alleviates these shortcomings. Specifically, we employ Random Network Distillation (RND) to measure the novelty of an advice, for the student to determine whether to proceed with the request; furthermore, we perform RND updates only for the advised states to ensure that the student's convergence will not prevent it from utilising the teacher's knowledge at any stage of learning. Experiments in GridWorld and simplified versions of five Atari games show that our approach can perform on par with the state-of-the-art and demonstrate significant advantages in the scenarios where the existing methods are prone to fail.