 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning on a Budget via Teacher Imitation
Paper and Code


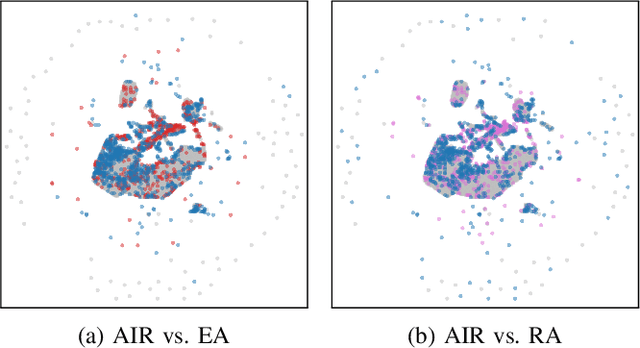
Deep Reinforcement Learning (RL) techniques can benefit greatly from leveraging prior experience, which can be either self-generated or acquired from other entities. Action advising is a framework that provides a flexible way to transfer such knowledge in the form of actions between teacher-student peers. However, due to the realistic concerns, the number of these interactions is limited with a budget; therefore, it is crucial to perform these in the most appropriate moments. There have been several promising studies recently that address this problem setting especially from the student's perspective. Despite their success, they have some shortcomings when it comes to the practical applicability and integrity as an overall solution to the learning from advice challenge. In this paper, we extend the idea of advice reusing via teacher imitation to construct a unified approach that addresses both advice collection and advice utilisation problems. Furthermore, we also propose a method to automatically determine the relevant hyperparameters of these components on-the-fly to make it able to adapt to any task with minimal human intervention. The experiments we performed in 5 different Atari games verify that our algorithm can outperform its competitors by achieving state-of-the-art performance, and its components themselves also provides significant advantages individually.