 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStudent-Initiated Action Advising via Advice Novelty
Paper and Code

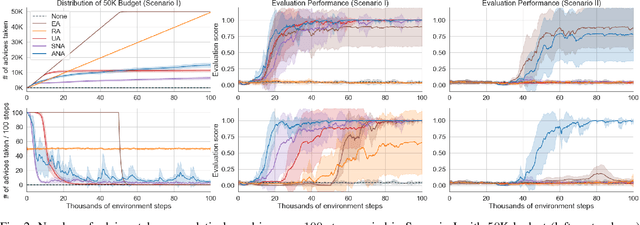
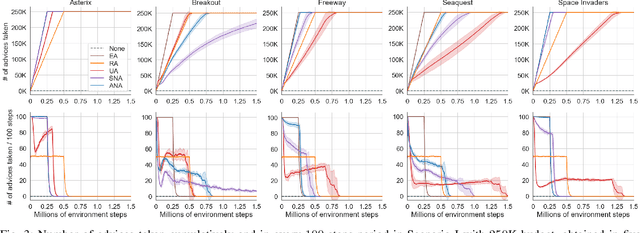
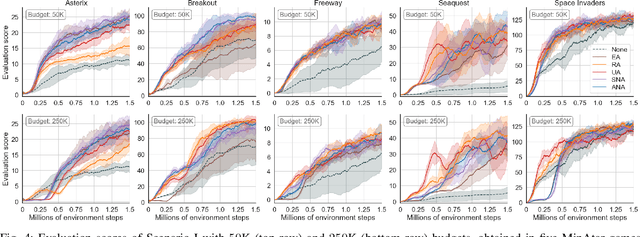
Action advising is a knowledge exchange mechanism between peers, namely student and teacher, that can help tackle exploration and sample inefficiency problems in deep reinforcement learning. Due to the practical limitations in peer-to-peer communication and the negative implications of over-advising, the peer responsible for initiating these interactions needs to do so only when it's most adequate to exchange advice. Most recently, student-initiated techniques that utilise state novelty and uncertainty estimations have obtained promising results. However, these estimations have several weaknesses, such as having no information regarding the characteristics of convergence and being subject to delays that occur in the presence of experience replay dynamics. We propose a student-initiated action advising algorithm that alleviates these shortcomings. Specifically, we employ Random Network Distillation (RND) to measure the novelty of an advice, for the student to determine whether to proceed with the request; furthermore, we perform RND updates only for the advised states to ensure that the student's convergence will not prevent it from utilising the teacher's knowledge at any stage of learning. Experiments in GridWorld and simplified versions of five Atari games show that our approach can perform on par with the state-of-the-art and demonstrate significant advantages in the scenarios where the existing methods are prone to fail.