 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMethodical Advice Collection and Reuse in Deep Reinforcement Learning
Apr 14, 2022
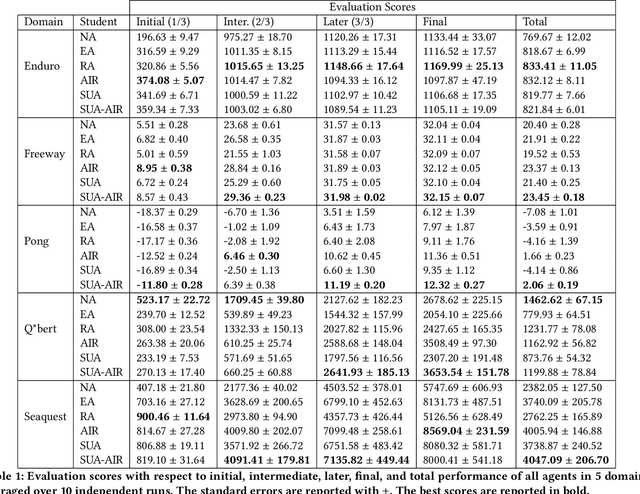
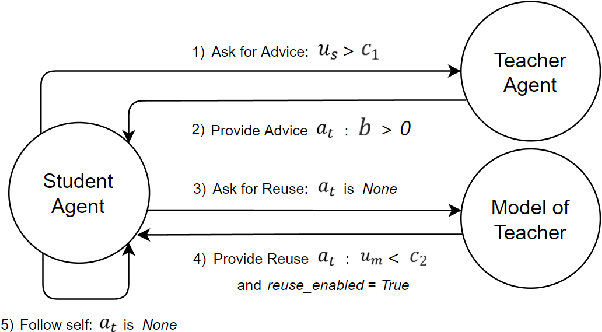
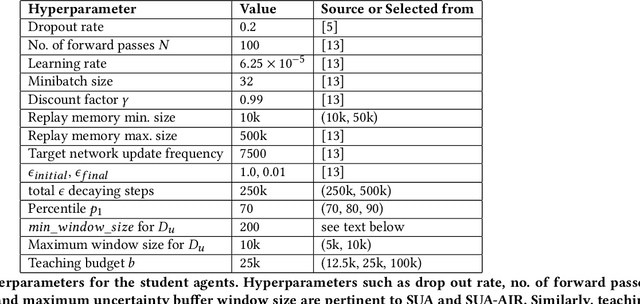
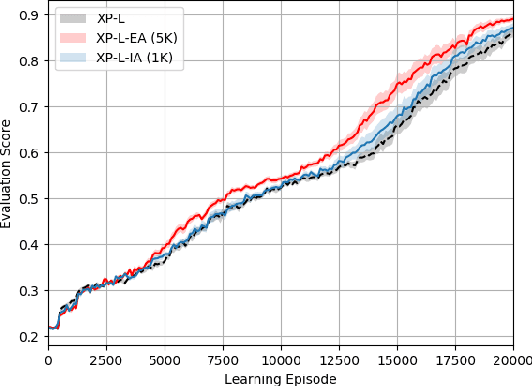
Reinforcement learning (RL) has shown great success in solving many challenging tasks via use of deep neural networks. Although using deep learning for RL brings immense representational power, it also causes a well-known sample-inefficiency problem. This means that the algorithms are data-hungry and require millions of training samples to converge to an adequate policy. One way to combat this issue is to use action advising in a teacher-student framework, where a knowledgeable teacher provides action advice to help the student. This work considers how to better leverage uncertainties about when a student should ask for advice and if the student can model the teacher to ask for less advice. The student could decide to ask for advice when it is uncertain or when both it and its model of the teacher are uncertain. In addition to this investigation, this paper introduces a new method to compute uncertainty for a deep RL agent using a secondary neural network. Our empirical results show that using dual uncertainties to drive advice collection and reuse may improve learning performance across several Atari games.
Teaching on a Budget in Multi-Agent Deep Reinforcement Learning
May 28, 2019


Deep Reinforcement Learning (RL) algorithms can solve complex sequential decision tasks successfully. However, they have a major drawback of having poor sample efficiency which can often be tackled by knowledge reuse. In Multi-Agent Reinforcement Learning (MARL) this drawback becomes worse, but at the same time, a new set of opportunities to leverage knowledge are also presented through agent interactions. One promising approach among these is peer-to-peer action advising through a teacher-student framework. Despite being introduced for single-agent RL originally, recent studies show that it can also be applied to multi-agent scenarios with promising empirical results. However, studies in this line of research are currently very limited. In this paper, we propose heuristics-based action advising techniques in cooperative decentralised MARL, using a nonlinear function approximation based task-level policy. By adopting Random Network Distillation technique, we devise a measurement for agents to assess their knowledge in any given state and be able to initiate the teacher-student dynamics with no prior role assumptions. Experimental results in a gridworld environment show that such an approach may indeed be useful and needs to be further investigated.