 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel Framework for Automated Warehouse Layout Generation
Jul 11, 2024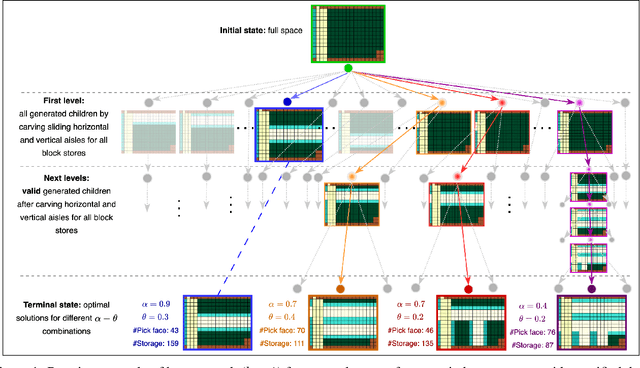
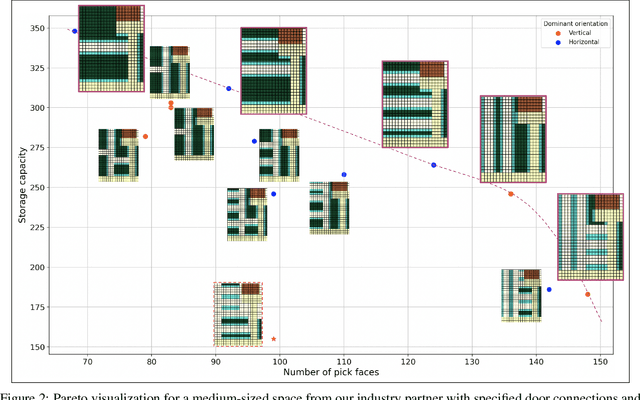
Optimizing warehouse layouts is crucial due to its significant impact on efficiency and productivity. We present an AI-driven framework for automated warehouse layout generation. This framework employs constrained beam search to derive optimal layouts within given spatial parameters, adhering to all functional requirements. The feasibility of the generated layouts is verified based on criteria such as item accessibility, required minimum clearances, and aisle connectivity. A scoring function is then used to evaluate the feasible layouts considering the number of storage locations, access points, and accessibility costs. We demonstrate our method's ability to produce feasible, optimal layouts for a variety of warehouse dimensions and shapes, diverse door placements, and interconnections. This approach, currently being prepared for deployment, will enable human designers to rapidly explore and confirm options, facilitating the selection of the most appropriate layout for their use-case.
Methodical Advice Collection and Reuse in Deep Reinforcement Learning
Apr 14, 2022
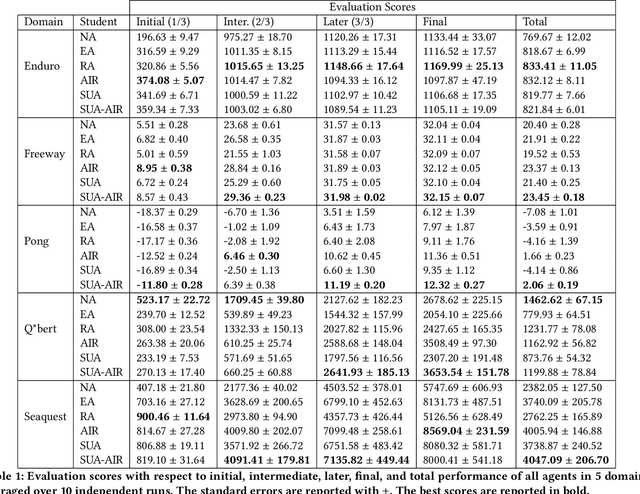
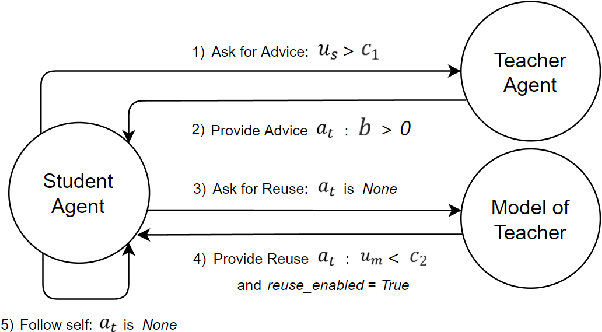
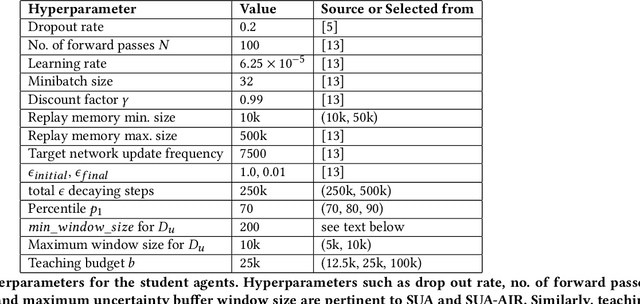
Reinforcement learning (RL) has shown great success in solving many challenging tasks via use of deep neural networks. Although using deep learning for RL brings immense representational power, it also causes a well-known sample-inefficiency problem. This means that the algorithms are data-hungry and require millions of training samples to converge to an adequate policy. One way to combat this issue is to use action advising in a teacher-student framework, where a knowledgeable teacher provides action advice to help the student. This work considers how to better leverage uncertainties about when a student should ask for advice and if the student can model the teacher to ask for less advice. The student could decide to ask for advice when it is uncertain or when both it and its model of the teacher are uncertain. In addition to this investigation, this paper introduces a new method to compute uncertainty for a deep RL agent using a secondary neural network. Our empirical results show that using dual uncertainties to drive advice collection and reuse may improve learning performance across several Atari games.
Maximum Reward Formulation In Reinforcement Learning
Oct 08, 2020
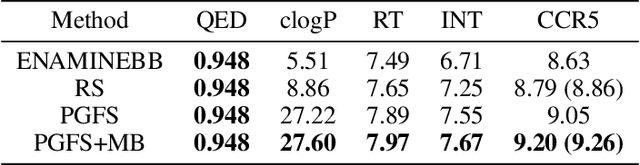
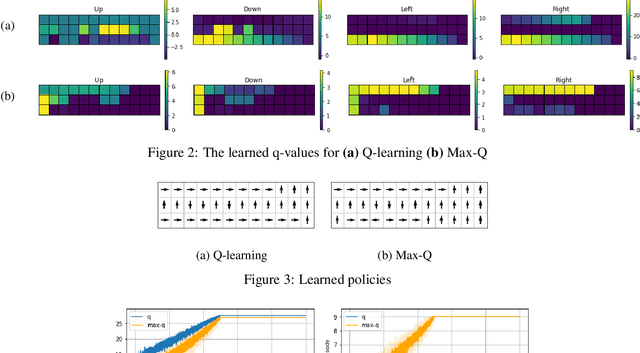
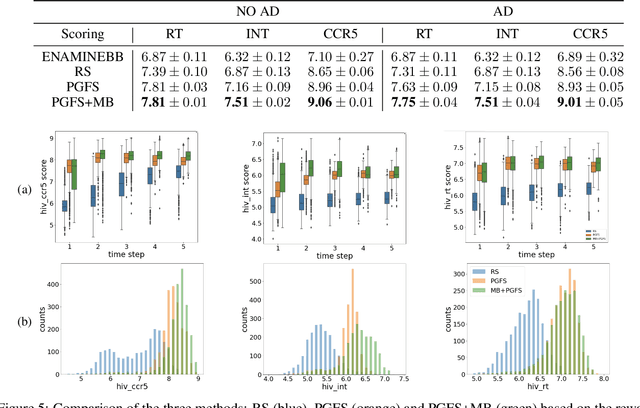
Reinforcement learning (RL) algorithms typically deal with maximizing the expected cumulative return (discounted or undiscounted, finite or infinite horizon). However, several crucial applications in the real world, such as drug discovery, do not fit within this framework because an RL agent only needs to identify states (molecules) that achieve the highest reward within a trajectory and does not need to optimize for the expected cumulative return. In this work, we formulate an objective function to maximize the expected maximum reward along a trajectory, derive a novel functional form of the Bellman equation, introduce the corresponding Bellman operators, and provide a proof of convergence. Using this formulation, we achieve state-of-the-art results on the task of molecule generation that mimics a real-world drug discovery pipeline.