 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention Option-Critic
Jan 07, 2022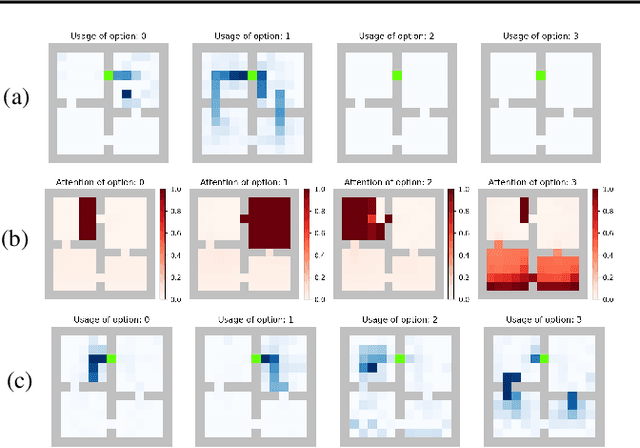
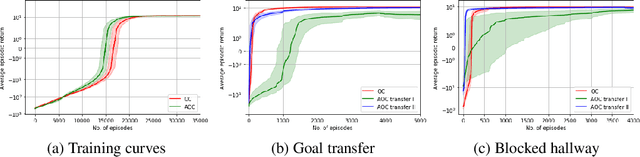
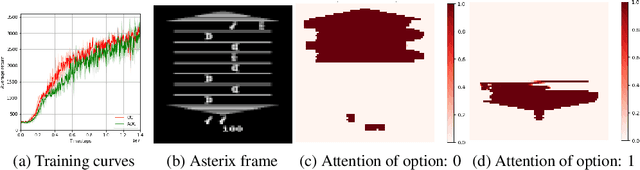
Temporal abstraction in reinforcement learning is the ability of an agent to learn and use high-level behaviors, called options. The option-critic architecture provides a gradient-based end-to-end learning method to construct options. We propose an attention-based extension to this framework, which enables the agent to learn to focus different options on different aspects of the observation space. We show that this leads to behaviorally diverse options which are also capable of state abstraction, and prevents the degeneracy problems of option domination and frequent option switching that occur in option-critic, while achieving a similar sample complexity. We also demonstrate the more efficient, interpretable, and reusable nature of the learned options in comparison with option-critic, through different transfer learning tasks. Experimental results in a relatively simple four-rooms environment and the more complex ALE (Arcade Learning Environment) showcase the efficacy of our approach.
Maximum Reward Formulation In Reinforcement Learning
Oct 08, 2020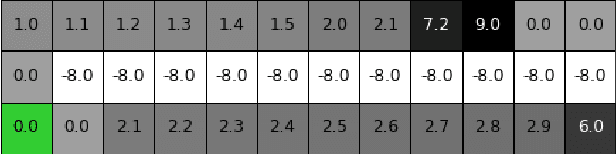
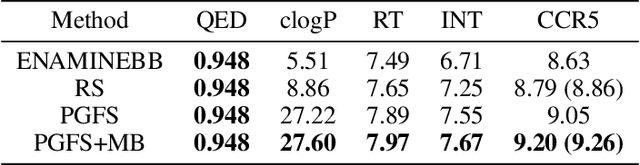
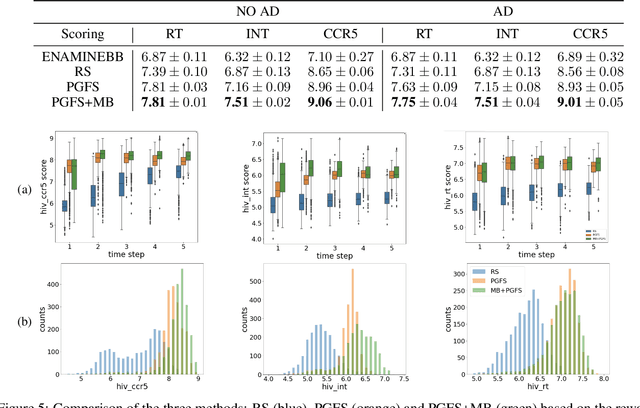
Reinforcement learning (RL) algorithms typically deal with maximizing the expected cumulative return (discounted or undiscounted, finite or infinite horizon). However, several crucial applications in the real world, such as drug discovery, do not fit within this framework because an RL agent only needs to identify states (molecules) that achieve the highest reward within a trajectory and does not need to optimize for the expected cumulative return. In this work, we formulate an objective function to maximize the expected maximum reward along a trajectory, derive a novel functional form of the Bellman equation, introduce the corresponding Bellman operators, and provide a proof of convergence. Using this formulation, we achieve state-of-the-art results on the task of molecule generation that mimics a real-world drug discovery pipeline.