 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Systematic Approach to Design Real-World Human-in-the-Loop Deep Reinforcement Learning: Salient Features, Challenges and Trade-offs
Apr 23, 2025

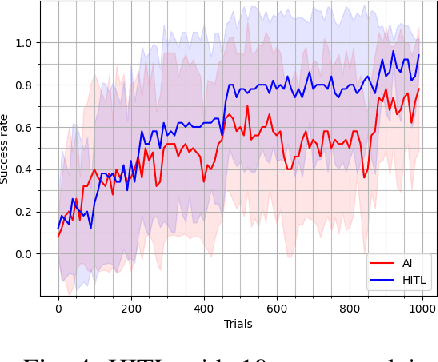
With the growing popularity of deep reinforcement learning (DRL), human-in-the-loop (HITL) approach has the potential to revolutionize the way we approach decision-making problems and create new opportunities for human-AI collaboration. In this article, we introduce a novel multi-layered hierarchical HITL DRL algorithm that comprises three types of learning: self learning, imitation learning and transfer learning. In addition, we consider three forms of human inputs: reward, action and demonstration. Furthermore, we discuss main challenges, trade-offs and advantages of HITL in solving complex problems and how human information can be integrated in the AI solution systematically. To verify our technical results, we present a real-world unmanned aerial vehicles (UAV) problem wherein a number of enemy drones attack a restricted area. The objective is to design a scalable HITL DRL algorithm for ally drones to neutralize the enemy drones before they reach the area. To this end, we first implement our solution using an award-winning open-source HITL software called Cogment. We then demonstrate several interesting results such as (a) HITL leads to faster training and higher performance, (b) advice acts as a guiding direction for gradient methods and lowers variance, and (c) the amount of advice should neither be too large nor too small to avoid over-training and under-training. Finally, we illustrate the role of human-AI cooperation in solving two real-world complex scenarios, i.e., overloaded and decoy attacks.
GLIDE-RL: Grounded Language Instruction through DEmonstration in RL
Jan 03, 2024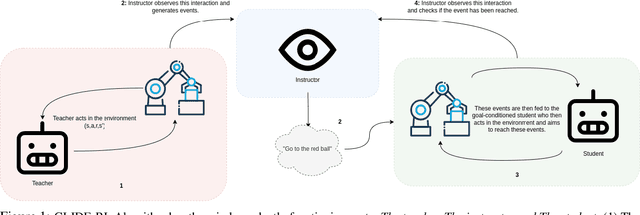

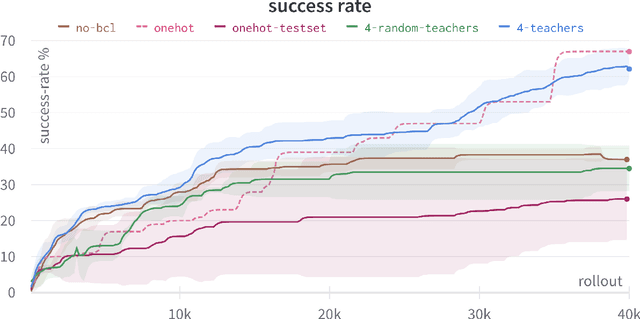
One of the final frontiers in the development of complex human - AI collaborative systems is the ability of AI agents to comprehend the natural language and perform tasks accordingly. However, training efficient Reinforcement Learning (RL) agents grounded in natural language has been a long-standing challenge due to the complexity and ambiguity of the language and sparsity of the rewards, among other factors. Several advances in reinforcement learning, curriculum learning, continual learning, language models have independently contributed to effective training of grounded agents in various environments. Leveraging these developments, we present a novel algorithm, Grounded Language Instruction through DEmonstration in RL (GLIDE-RL) that introduces a teacher-instructor-student curriculum learning framework for training an RL agent capable of following natural language instructions that can generalize to previously unseen language instructions. In this multi-agent framework, the teacher and the student agents learn simultaneously based on the student's current skill level. We further demonstrate the necessity for training the student agent with not just one, but multiple teacher agents. Experiments on a complex sparse reward environment validates the effectiveness of our proposed approach.
Human-AI Collaboration in Real-World Complex Environment with Reinforcement Learning
Dec 23, 2023Recent advances in reinforcement learning (RL) and Human-in-the-Loop (HitL) learning have made human-AI collaboration easier for humans to team with AI agents. Leveraging human expertise and experience with AI in intelligent systems can be efficient and beneficial. Still, it is unclear to what extent human-AI collaboration will be successful, and how such teaming performs compared to humans or AI agents only. In this work, we show that learning from humans is effective and that human-AI collaboration outperforms human-controlled and fully autonomous AI agents in a complex simulation environment. In addition, we have developed a new simulator for critical infrastructure protection, focusing on a scenario where AI-powered drones and human teams collaborate to defend an airport against enemy drone attacks. We develop a user interface to allow humans to assist AI agents effectively. We demonstrated that agents learn faster while learning from policy correction compared to learning from humans or agents. Furthermore, human-AI collaboration requires lower mental and temporal demands, reduces human effort, and yields higher performance than if humans directly controlled all agents. In conclusion, we show that humans can provide helpful advice to the RL agents, allowing them to improve learning in a multi-agent setting.
Curriculum Learning for Cooperation in Multi-Agent Reinforcement Learning
Dec 19, 2023



While there has been significant progress in curriculum learning and continuous learning for training agents to generalize across a wide variety of environments in the context of single-agent reinforcement learning, it is unclear if these algorithms would still be valid in a multi-agent setting. In a competitive setting, a learning agent can be trained by making it compete with a curriculum of increasingly skilled opponents. However, a general intelligent agent should also be able to learn to act around other agents and cooperate with them to achieve common goals. When cooperating with other agents, the learning agent must (a) learn how to perform the task (or subtask), and (b) increase the overall team reward. In this paper, we aim to answer the question of what kind of cooperative teammate, and a curriculum of teammates should a learning agent be trained with to achieve these two objectives. Our results on the game Overcooked show that a pre-trained teammate who is less skilled is the best teammate for overall team reward but the worst for the learning of the agent. Moreover, somewhat surprisingly, a curriculum of teammates with decreasing skill levels performs better than other types of curricula.
Human-Machine Teaming for UAVs: An Experimentation Platform
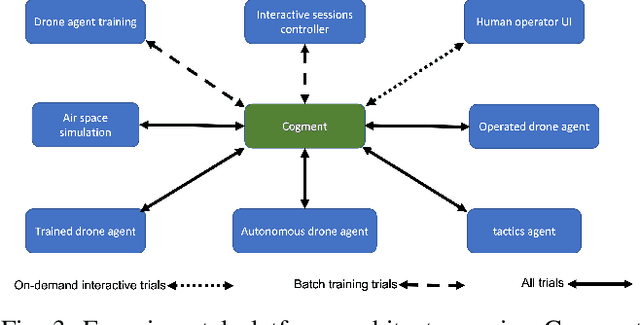
Dec 18, 2023Full automation is often not achievable or desirable in critical systems with high-stakes decisions. Instead, human-AI teams can achieve better results. To research, develop, evaluate, and validate algorithms suited for such teaming, lightweight experimentation platforms that enable interactions between humans and multiple AI agents are necessary. However, there are limited examples of such platforms for defense environments. To address this gap, we present the Cogment human-machine teaming experimentation platform, which implements human-machine teaming (HMT) use cases that features heterogeneous multi-agent systems and can involve learning AI agents, static AI agents, and humans. It is built on the Cogment platform and has been used for academic research, including work presented at the ALA workshop at AAMAS this year [1]. With this platform, we hope to facilitate further research on human-machine teaming in critical systems and defense environments.
Cogment: Open Source Framework For Distributed Multi-actor Training, Deployment & Operations
Jun 21, 2021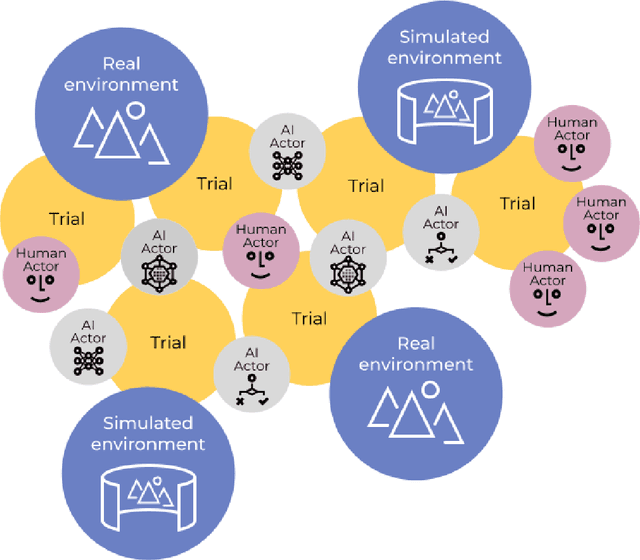
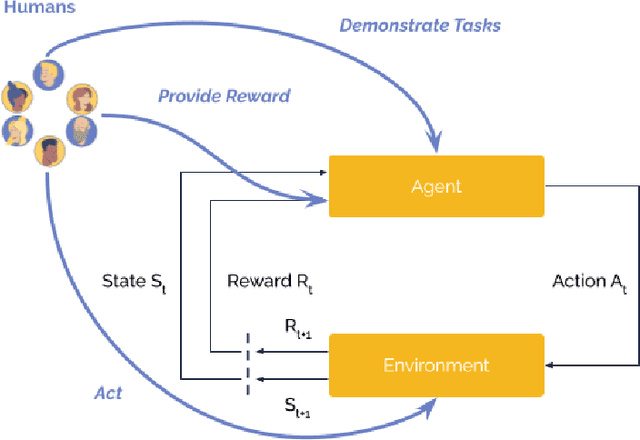
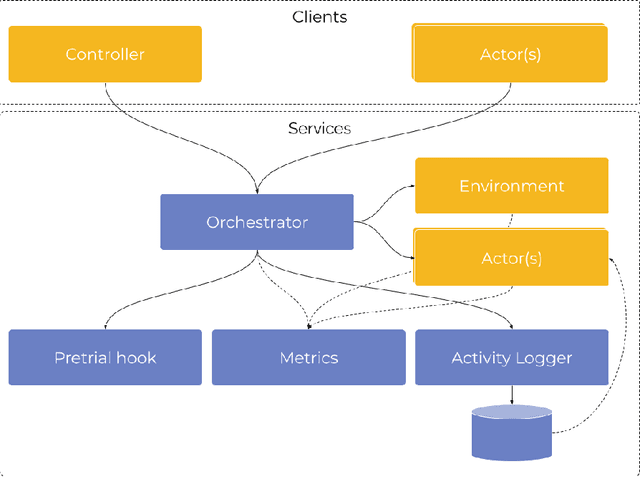
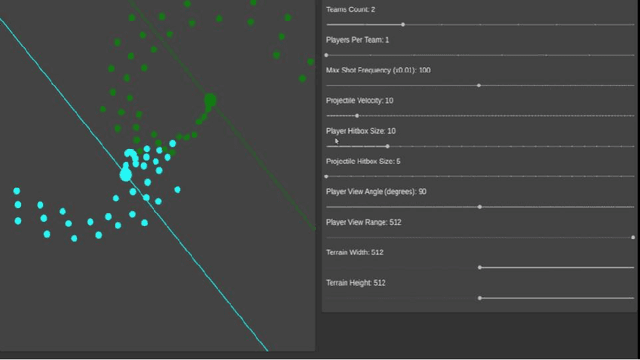
Involving humans directly for the benefit of AI agents' training is getting traction thanks to several advances in reinforcement learning and human-in-the-loop learning. Humans can provide rewards to the agent, demonstrate tasks, design a curriculum, or act in the environment, but these benefits also come with architectural, functional design and engineering complexities. We present Cogment, a unifying open-source framework that introduces an actor formalism to support a variety of humans-agents collaboration typologies and training approaches. It is also scalable out of the box thanks to a distributed micro service architecture, and offers solutions to the aforementioned complexities.
Maximum Reward Formulation In Reinforcement Learning
Oct 08, 2020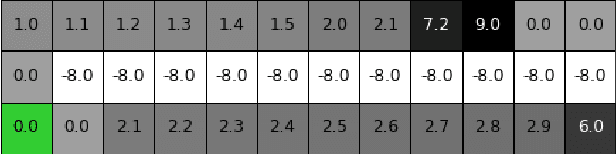
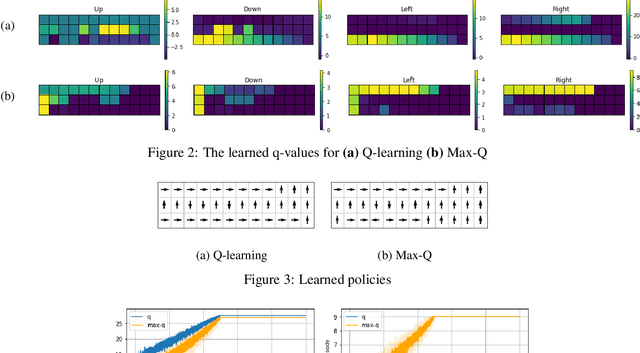
Reinforcement learning (RL) algorithms typically deal with maximizing the expected cumulative return (discounted or undiscounted, finite or infinite horizon). However, several crucial applications in the real world, such as drug discovery, do not fit within this framework because an RL agent only needs to identify states (molecules) that achieve the highest reward within a trajectory and does not need to optimize for the expected cumulative return. In this work, we formulate an objective function to maximize the expected maximum reward along a trajectory, derive a novel functional form of the Bellman equation, introduce the corresponding Bellman operators, and provide a proof of convergence. Using this formulation, we achieve state-of-the-art results on the task of molecule generation that mimics a real-world drug discovery pipeline.
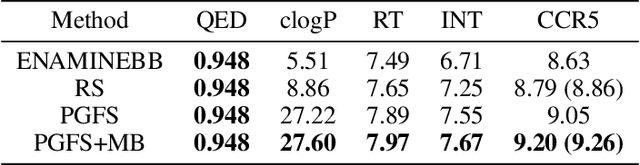
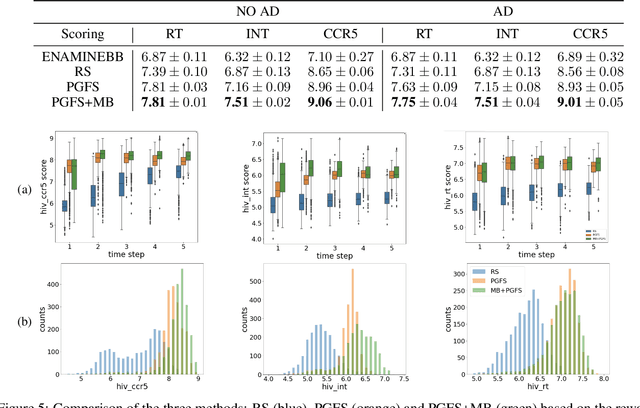
Learning To Navigate The Synthetically Accessible Chemical Space Using Reinforcement Learning
May 20, 2020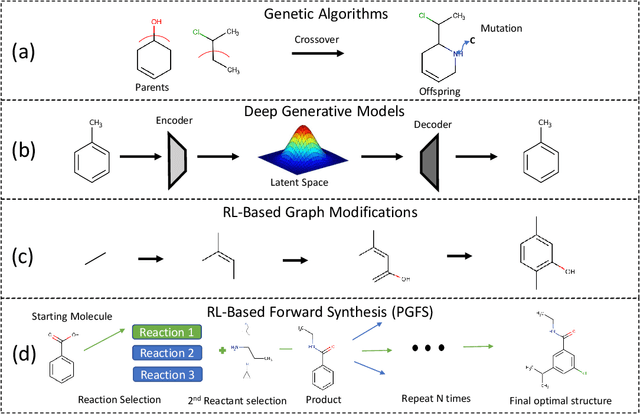


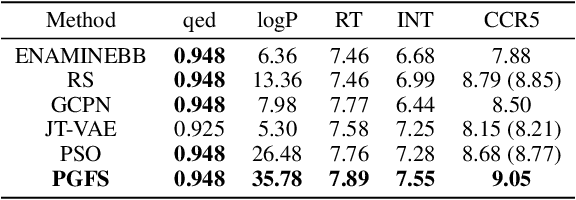
Over the last decade, there has been significant progress in the field of machine learning for de novo drug design, particularly in deep generative models. However, current generative approaches exhibit a significant challenge as they do not ensure that the proposed molecular structures can be feasibly synthesized nor do they provide the synthesis routes of the proposed small molecules, thereby seriously limiting their practical applicability. In this work, we propose a novel forward synthesis framework powered by reinforcement learning (RL) for de novo drug design, Policy Gradient for Forward Synthesis (PGFS), that addresses this challenge by embedding the concept of synthetic accessibility directly into the de novo drug design system. In this setup, the agent learns to navigate through the immense synthetically accessible chemical space by subjecting commercially available small molecule building blocks to valid chemical reactions at every time step of the iterative virtual multi-step synthesis process. The proposed environment for drug discovery provides a highly challenging test-bed for RL algorithms owing to the large state space and high-dimensional continuous action space with hierarchical actions. PGFS achieves state-of-the-art performance in generating structures with high QED and penalized clogP. Moreover, we validate PGFS in an in-silico proof-of-concept associated with three HIV targets. Finally, we describe how the end-to-end training conceptualized in this study represents an important paradigm in radically expanding the synthesizable chemical space and automating the drug discovery process.