 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLIDE-RL: Grounded Language Instruction through DEmonstration in RL
Paper and Code
Jan 03, 2024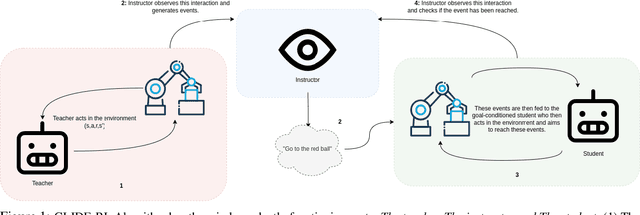

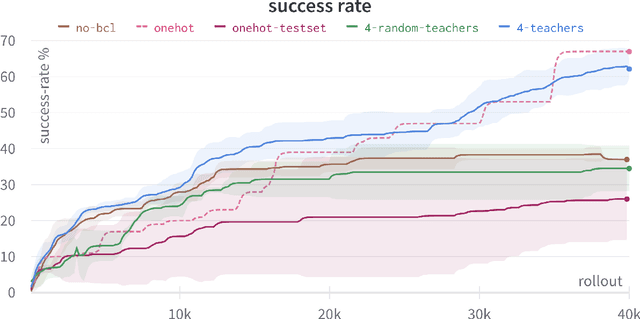
One of the final frontiers in the development of complex human - AI collaborative systems is the ability of AI agents to comprehend the natural language and perform tasks accordingly. However, training efficient Reinforcement Learning (RL) agents grounded in natural language has been a long-standing challenge due to the complexity and ambiguity of the language and sparsity of the rewards, among other factors. Several advances in reinforcement learning, curriculum learning, continual learning, language models have independently contributed to effective training of grounded agents in various environments. Leveraging these developments, we present a novel algorithm, Grounded Language Instruction through DEmonstration in RL (GLIDE-RL) that introduces a teacher-instructor-student curriculum learning framework for training an RL agent capable of following natural language instructions that can generalize to previously unseen language instructions. In this multi-agent framework, the teacher and the student agents learn simultaneously based on the student's current skill level. We further demonstrate the necessity for training the student agent with not just one, but multiple teacher agents. Experiments on a complex sparse reward environment validates the effectiveness of our proposed approach.