 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning To Navigate The Synthetically Accessible Chemical Space Using Reinforcement Learning
May 20, 2020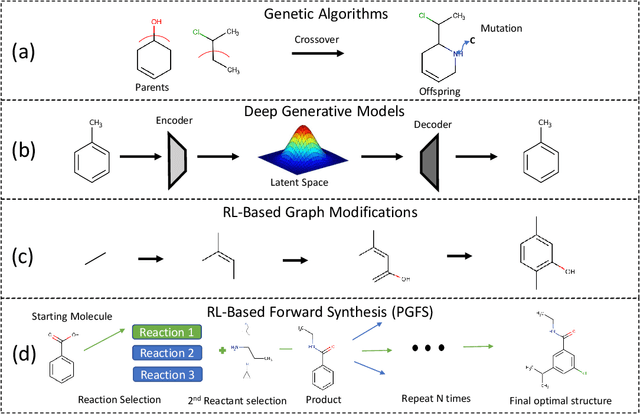


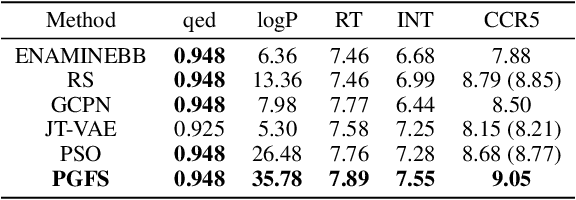
Over the last decade, there has been significant progress in the field of machine learning for de novo drug design, particularly in deep generative models. However, current generative approaches exhibit a significant challenge as they do not ensure that the proposed molecular structures can be feasibly synthesized nor do they provide the synthesis routes of the proposed small molecules, thereby seriously limiting their practical applicability. In this work, we propose a novel forward synthesis framework powered by reinforcement learning (RL) for de novo drug design, Policy Gradient for Forward Synthesis (PGFS), that addresses this challenge by embedding the concept of synthetic accessibility directly into the de novo drug design system. In this setup, the agent learns to navigate through the immense synthetically accessible chemical space by subjecting commercially available small molecule building blocks to valid chemical reactions at every time step of the iterative virtual multi-step synthesis process. The proposed environment for drug discovery provides a highly challenging test-bed for RL algorithms owing to the large state space and high-dimensional continuous action space with hierarchical actions. PGFS achieves state-of-the-art performance in generating structures with high QED and penalized clogP. Moreover, we validate PGFS in an in-silico proof-of-concept associated with three HIV targets. Finally, we describe how the end-to-end training conceptualized in this study represents an important paradigm in radically expanding the synthesizable chemical space and automating the drug discovery process.
Generalized Value Iteration Networks: Life Beyond Lattices
Oct 26, 2017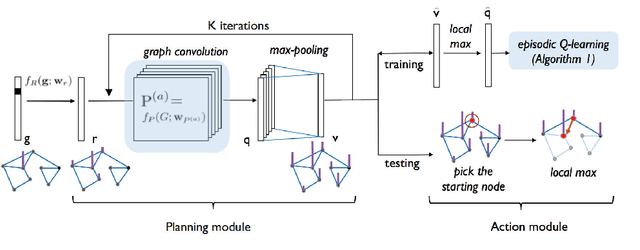
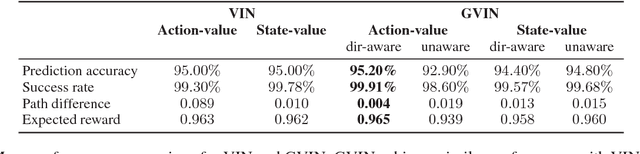
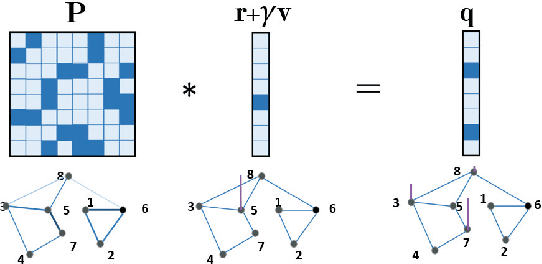

In this paper, we introduce a generalized value iteration network (GVIN), which is an end-to-end neural network planning module. GVIN emulates the value iteration algorithm by using a novel graph convolution operator, which enables GVIN to learn and plan on irregular spatial graphs. We propose three novel differentiable kernels as graph convolution operators and show that the embedding based kernel achieves the best performance. We further propose episodic Q-learning, an improvement upon traditional n-step Q-learning that stabilizes training for networks that contain a planning module. Lastly, we evaluate GVIN on planning problems in 2D mazes, irregular graphs, and real-world street networks, showing that GVIN generalizes well for both arbitrary graphs and unseen graphs of larger scale and outperforms a naive generalization of VIN (discretizing a spatial graph into a 2D image).